
原文:http://hwreblog.com/projects/so_debugging_binary_ninja.html
通过对嵌入式系统的固件进行动态分析,可以大大提高逆向工程的进度。反汇编程序不仅对于静态分析来说是至关重要的,同时,也可以在动态分析期间发挥巨大的威力。在大多数反汇编程序中,动态分析过程中的调试通常都可以直接完成,但是,当所处理的应用程序跳转到共享库时,这些反汇编程序似乎都没有提供直接的方法来跟踪程序流程。然而,如果能够在反汇编程序中跟踪共享库的跳转情况的话,不仅可以帮助我们更好地理解程序流程,此外,如果有必要的话,还可以帮助修补共享库。为了做到这些,还有一些问题需要解决。首先,在应用程序或进程启动之前,共享库的内存位置是未知的,其次,反汇编程序会把应用程序和共享库视为单独的实例。因此,为了在动态分析过程中通过反汇编程序进行调试,我们需要设法来解决这些问题。下面,我们将为读者将介绍一种借助gdb、Binary Ninja、Voltron和binjatron来动态分析共享库的简单技术,其中,binjatron是一个Binary Ninja插件,用于在动态分析期间进行可视化调试。
搭建测试环境
由于本人的大部分工作都涉及嵌入式系统的逆向分析,因此,这里将重点介绍一种用于远程调试嵌入式系统的方法。为了帮助读者复现这一过程,我们会给出目标端的具体设置过程。但是,这个过程将取决于您在目标上可用的接口情况。就本文来说,我的目标是运行Linux raspberrypi 4.14.50+的Raspberry Pi系统。我已经通过raspbian repo安装了gdbserver,我将TCP连接实现与gdbserver的连接。此外,我还在分析计算机上安装了Binary Ninja、Voltron和binjatron。对于Voltron和binjatron的安装过程,读者可以参考其github页面上的相关说明。
我们的示例程序非常简单:其中涉及一个简单的共享库,可以使用“-fpic -c”和“-shared”进行编译;还有一个主程序,它会调用共享库中的函数,可以使用库的位置和名称完成相应的编译。下面显示的是编译结果和源代码。



完成编译后,设置LD_LIBRARY_PATH并运行该程序。此外,我还运行了“ldd”命令,验证该程序是否将libfoo作为共享库。
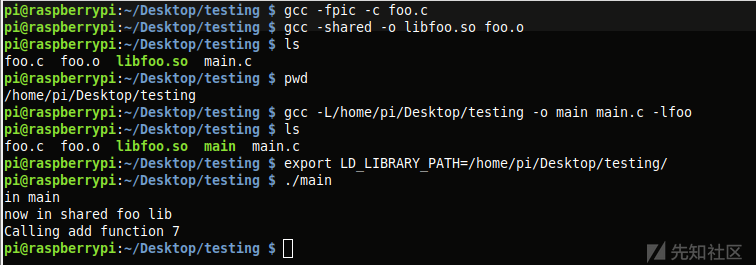

将这些程序拉入Binary Ninja,以验证一切是否如我们所愿。在下图中,我们可以看到,主程序和foo共享库已经加载进Binary Ninja了,当然,这里是以中级完整性来显示libfoo.so。


到目前为止,看起来一切正常,所以,接下来就可以使用gdbserver host:2345 main命令在目标系统上启动gdbserver了。为了启动连接会话,需要一个能够跨体系结构进行调试的gdb。我之前使用的是“arm-linux-gnueabihf-gdb”,在这里似乎也能工作。在gdb中,输入“target remote target-ip:2345”进行连接。

建立连接后,我们可以回到Binary Ninja,并与Voltron会话进行同步。
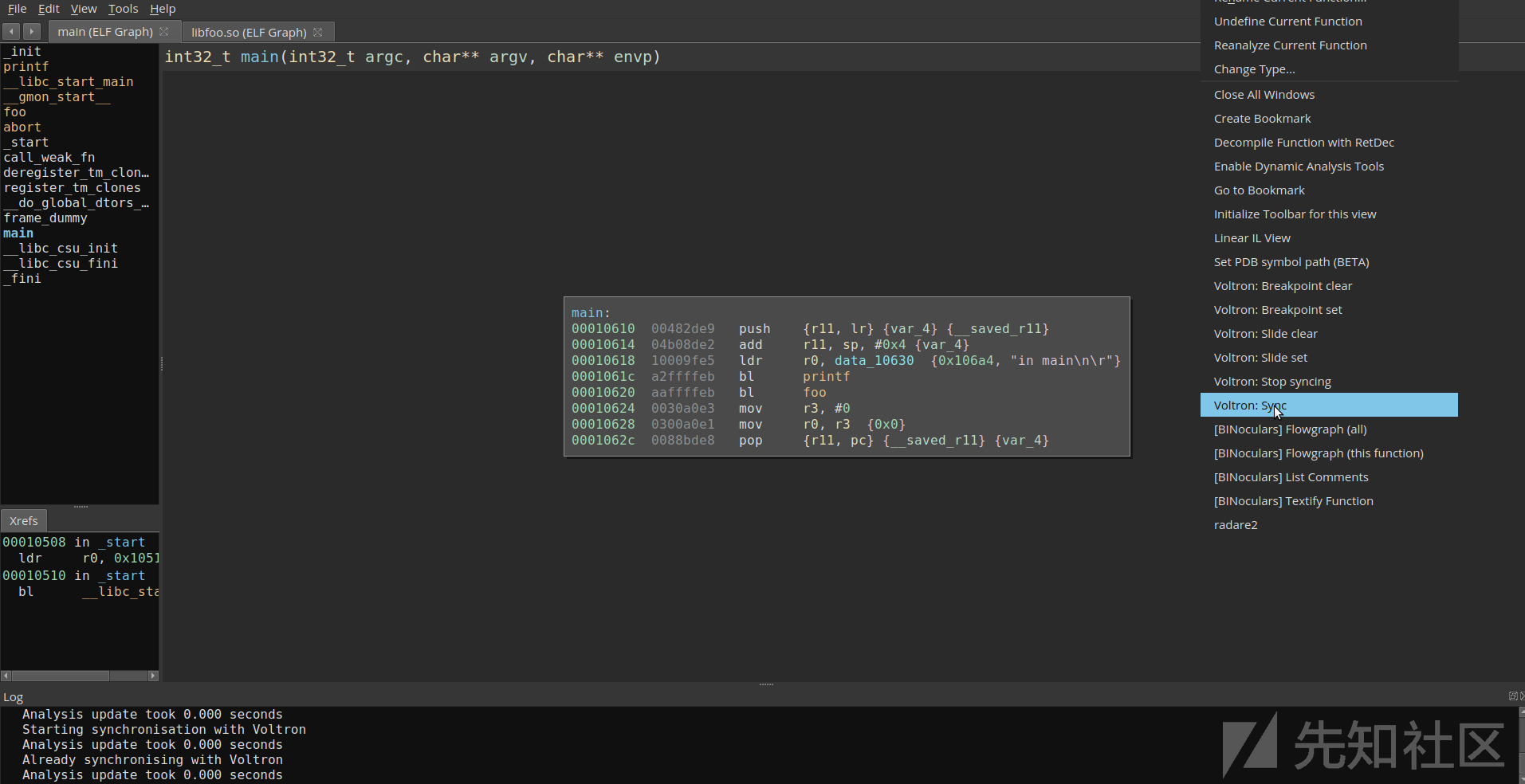
为了验证同步是否正常工作,我在main设置了一个断点,然后进行跟踪。

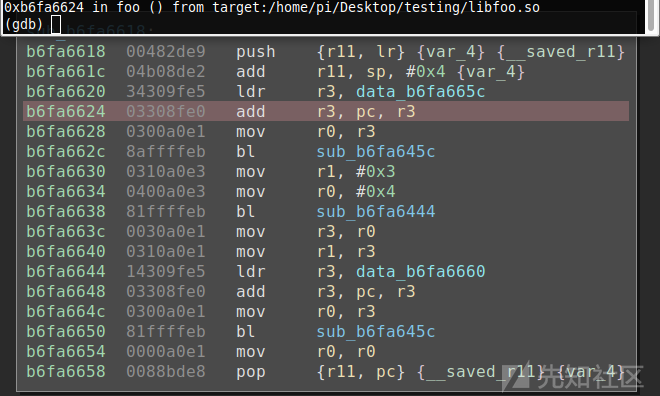
使用gdb跟踪该程序时,binjatron将突出显示Binary Ninja中的当前PC,具体如下所示。
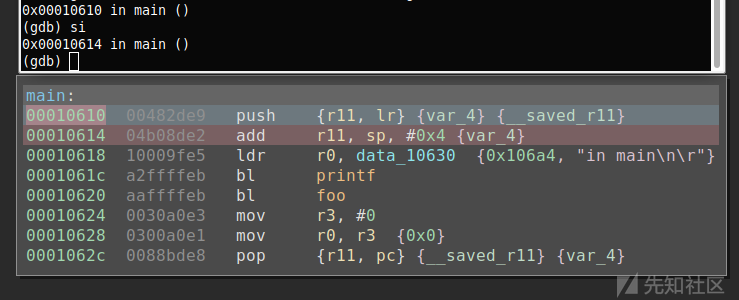


继续跟踪,一直到达PLT中的foo()为止,其实,PLT就是用来调用外部函数的。有关这方面的更多信息,请参阅这篇文章。
定位共享库的内存位置
现在,我们已经知道所有内容都能协同工作了,接下来,我们就可以生成进程,并对共享库进行动态分析了。如前所述,如果继续步进跟踪该应用程序,一旦main函数调用了foo(),由于共享库代码不在应用程序的二进制文件中,就无法高亮显示当前指令了。虽然可以单独使用Gdb和voltron进行动态分析,但是,对于带有大量分支语句的大型函数来说,图形化的视图能够帮我们更好地了解代码的执行流程。当然,我们也可以根据gdb/voltron的输出,利用Binary Ninja以手动方式来跟踪相关的反汇编代码,同时,在一个视图中协同工作的一大优点是,可以提高分析速度。然而,这样做的最大的问题在于,需要让Binary Ninja中的共享库偏移与应用程序期望的代码位置保持同步。由于这里的地址是偏移值,所以voltron连接无法同步。简单的解决方案是,求出共享库的加载地址的偏移,然后重新同步voltron。为此,首先需要以某种方式获得文件的偏移量。虽然有很多方法可以做到这一点,但在这里,只需在foo()处设置一个断点即可。当然,读者也可以采取其他方式。下面我们可以看到,这个断点给出了一个地址,即0xb6fa6620。
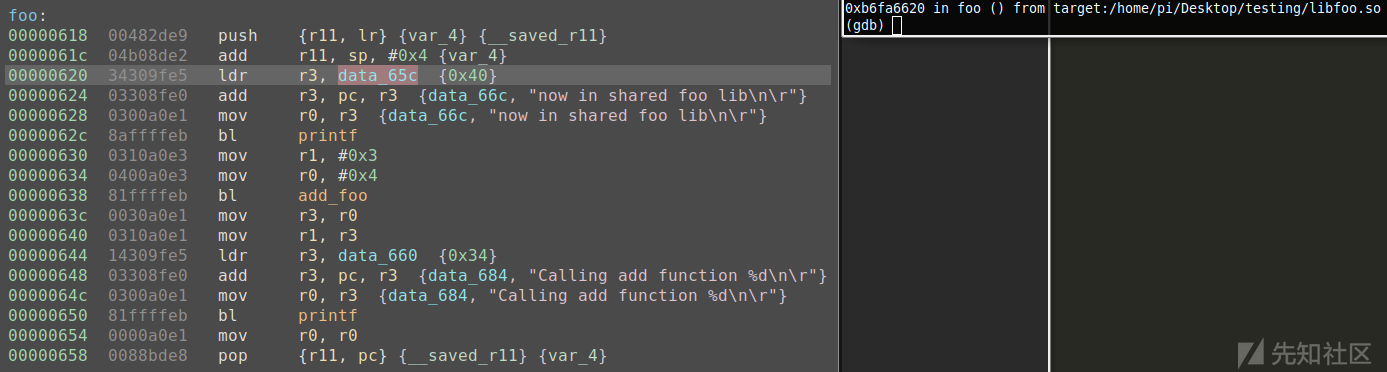
利用Binary Ninja分析这个共享库,我们发现,保存堆栈进入函数调用时,0x620偏移量位于foo()中。因此,我们可以使用该信息来计算偏移的起始地址,即0xb6fa6620 - 0x620 = 0xb6fa6000。
虽然Binary Ninja没有直接提供用于重新定义二进制文件的用户界面,但是,我们实际上可以通过一个API调用来解决这个问题。虽然他们没有给出调用示例或相关描述,但add_auto_segment的作用好像是从当前选定的文件中复制数据,并提供相应的偏移量。例如,对于add_auto_segment(self,start,length,data_offset,data_length,flags)来说:start是我们的偏移地址0xb6fa6000,length是原始文件长度,data_offset是0,data_length是原始文件长度。此外,如果将0xff传递给flags参数的话,就能够赋予相应的segment以读、写和执行权限。最后一个命令是“bv.add_auto_segment(0xb6fa6000, 0x6a0, 0, 0x6a0, 0xFF)”。下面展示的是在Binary Ninja的python控制台中运行该命令的情况。

在继续进行动态分析之前,需要先在新建的segment中创建相关的函数。为此,在Binary Ninja线性视图中找到新segment中的函数偏移后,只需按下“p”键即可。这时,Binary Ninja将分析新创建的函数,并对新segment中的调用进行递归分析。我还没有能够让线性扫描分析模式起作用,但这可能是另一种潜在的替代方案。下面,让我们来比较一下原始foo()与偏移后的foo()。


那么,接下来干什么呢?
我们已经计算好了偏移量,并在偏移处创建了函数,接下来,让我们继续进行动态分析。首先,我们需要停止与Binary Ninja中的共享库反汇编实例之间的同步,然后,重新进行同步。为此,可以通过右击Binary Ninja,然后选择“Voltron:Stop Syncing”/“Voltron:Sync”选项来完成。之后,当我们使用gdb进行步进跟踪时,就会像以前一样,开始高亮显示当前指令了。

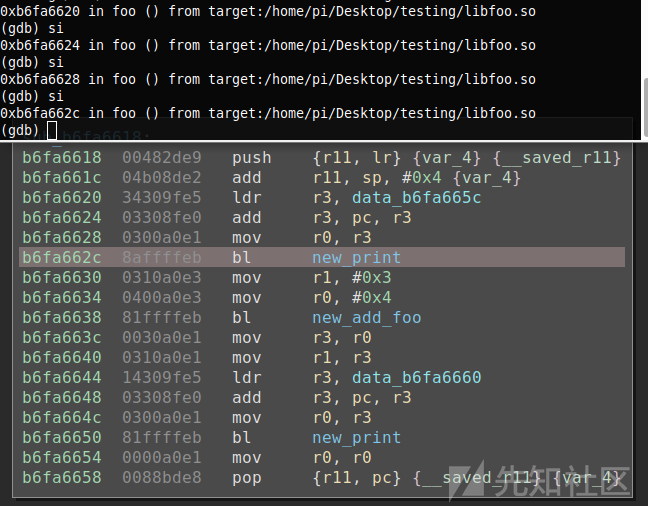
现在,我们还可以通过Binary Ninja的binjatron插件在共享库中设置断点。
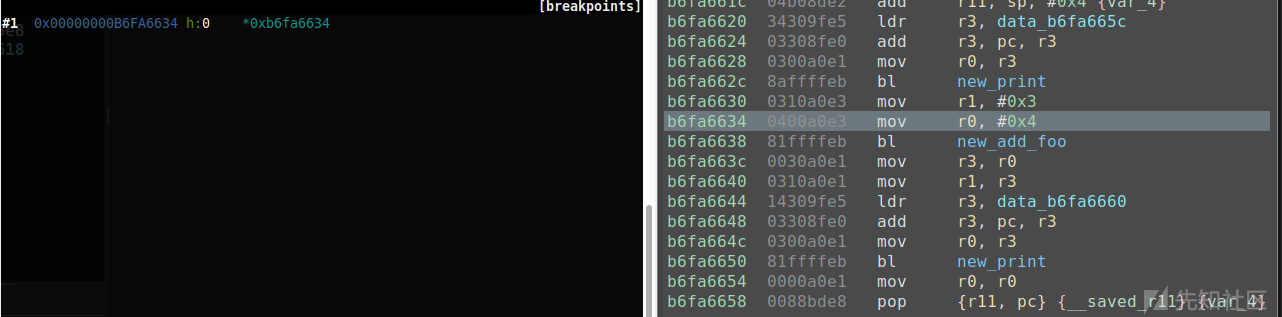
在计算偏移量时,使用Binary Ninja的python控制台会非常简便。同时,如果拥有一个可以自动执行这些操作的插件的话,能够极大地提高分析人员的工作效率。当我们分析的应用程序的时候,如果它依赖的多个共享库调用都需要进行动态分析的话,本文介绍的方法将会派上大用场。
 转载
转载
 分享
分享


能否分享一份授权版的Binary Ninja,谢谢