
前言
American Fuzzy Lop(AFL)很棒。在命令行应用程序上快速进行的模糊测试分析是最好的选择。但是,如果通过命令行访问你想要模糊的东西的情况怎么样呢?很多时候你可以编写一个测试工具(或者可能使用 libFuzzer),但如果你想要模拟你想要模糊的代码部分,并得到 AFL 的所有基于 coverage 的优点呢?
例如,你可能想要从嵌入式系统中模糊解析函数,该系统通过 RF 接收输入并且不容易调试。也许你感兴趣的代码深藏在一个复杂、缓慢的程序中,你不能轻易地通过任何传统工具。
我已经为 AFL 创建了一个新的 'Unicorn Mode' 工具来让你做到这一点。如果你可以模拟你对使用 Unicorn 引擎感兴趣的代码,你可以用 afl-unicorn 来 fuzz 它。所有源代码(以及一堆附加文档)都可以在 afl-unicorn GitHub 页面上找到。
如何获得它
克隆或从 GitHub 下载 afl-unicorn git repo 到 Linux 系统(我只在 Ubuntu 16.04 LTS 上测试过它)。之后,像普通方法一样构建和安装 AFL,然后进入 'unicorn_mode' 文件夹并以 root 身份运行 'build_unicorn_support.sh' 脚本。
cd /path/to/afl-unicorn
make
sudo make install
cd unicorn_mode
sudo ./build_unicorn_support.sh如何运作
Unicorn Mode 通过实现 AFL 的 QEMU 模式用于 Unicorn Engine 的块边缘检测来工作。基本上,AFL 将使用来自任何模拟代码段的块覆盖信息来驱动其输入生成。整个想法围绕着基于 Unicorn 的测试工具的正确构造,如下图所示:
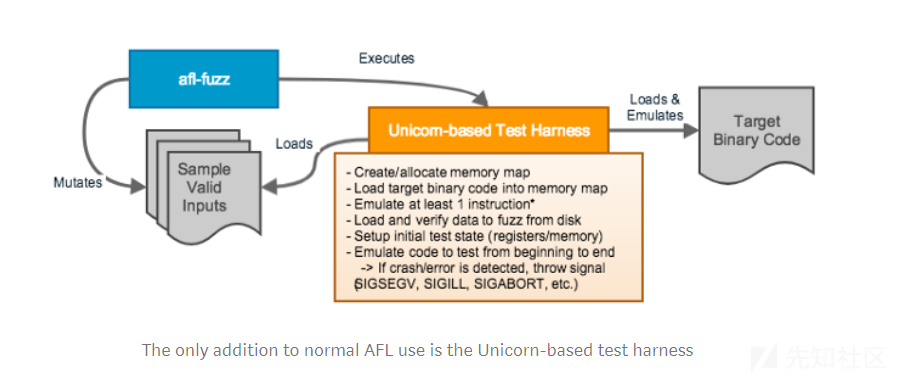
基于 Unicorn 的测试工具加载目标代码,设置初始状态,并加载 AFL 从磁盘变异的数据。然后,测试工具将模拟目标二进制代码,如果它检测到发生了崩溃或错误,则会抛出信号。 AFL会做所有正常的事情,但它实际上模糊了模拟的目标二进制代码!
Unicorn Mode 应该按照预期的方式使用 Unicorn 脚本或用任何标准 Unicorn 绑定(C / Python / Go / Whatever)编写的应用程序,只要在一天结束时测试工具使用从补丁编译的 libunicorn.so 由 afl-unicorn 创建的 Unicorn Engine 源代码。到目前为止,我只用 Python 测试了这个,所以如果你测试一下,请向repo提供反馈和/或补丁。
- 请注意,构建 afl-unicorn 将在本地系统上编译并安装修补版本的 Unicorn Engine v1.0.1。在构建 afl-unicorn 之前,您必须卸载任何现有的 Unicorn 二进制文件。与现成的 AFL 一样,afl-unicorn 仅支持 Linux。我只在 Ubuntu 16.04 LTS 上测试过它,但它应该可以在任何能够同时运行A FL 和 Unicorn 的操作系统上顺利运行。
- 注意:在加载模糊输入数据之前,必须至少模拟 1 条指令。这是 AFL 的 fork 服务器在 QEMU 模式下启动的工件。它可能可以修复一些更多的工作,但是现在只需模拟至少 1 条指令,如示例所示,不要担心它。下面的示例演示了如何轻松解决此限制。
使用例子
注意:这与 repo 中包含的 “简单示例” 相同。请在您自己的系统上使用它来查看它的运行情况。 repo 包含 main()的预构建 MIPS 二进制文件,在此处进行演示。
首先,让我们看一下我们将要模糊的代码。这只是一个简单的示例,它会以几种不同的方式轻松崩溃,但我已将其扩展到实际用例,并且它的工作方式完全符合预期。
/*
* Sample target file to test afl-unicorn fuzzing capabilities.
* This is a very trivial example that will crash pretty easily
* in several different exciting ways.
*
* Input is assumed to come from a buffer located at DATA_ADDRESS
* (0x00300000), so make sure that your Unicorn emulation of this
* puts user data there.
*
* Written by Nathan Voss <njvoss99@gmail.com>
*/
// Magic address where mutated data will be placed
#define DATA_ADDRESS 0x00300000
int main(void)
{
unsigned char* data_buf = (unsigned char*)DATA_ADDRESS;
if(data_buf[20] != 0)
{
// Cause an 'invalid read' crash if data[0..3] == '\x01\x02\x03\x04'
unsigned char invalid_read = *(unsigned char*)0x00000000;
}
else if(data_buf[0] > 0x10 && data_buf[0] < 0x20 && data_buf[1] > data_buf[2])
{
// Cause an 'invalid read' crash if (0x10 < data[0] < 0x20) and data[1] > data[2]
unsigned char invalid_read = *(unsigned char*)0x00000000;
}
else if(data_buf[9] == 0x00 && data_buf[10] != 0x00 && data_buf[11] == 0x00)
{
// Cause a crash if data[10] is not zero, but [9] and [11] are zero
unsigned char invalid_read = *(unsigned char*)0x00000000;
}
return 0;
}请注意,这段代码本身就完全是举例的。它假设 'data_buf' 的数据神奇地位于地址 0x00300000。虽然这看起来很奇怪,但这类似于许多解析函数,它们假设它们会在固定地址的缓冲区中找到数据。在实际情况中,您需要对目标二进制文件进行逆向工程,以查找并确定要模拟和模糊的确切功能。在即将发布的博客文章中,我将介绍一些工具来简化提取和加载流程状态,但是现在您需要完成在Unicorn中启动和运行所有必需组件的工作。
您的测试工具必须通过命令行中指定的文件将输入变为 mutate。这是允许 AFL 通过其正常接口改变输入的粘合剂。如果在仿真期间检测到崩溃情况,测试工具也必须强行自行崩溃,例如 emu_start()抛出异常。下面是一个示例测试工具,可以执行以下两个操作:
"""
Simple test harness for AFL's Unicorn Mode.
This loads the simple_target.bin binary (precompiled as MIPS code) into
Unicorn's memory map for emulation, places the specified input into
simple_target's buffer (hardcoded to be at 0x300000), and executes 'main()'.
If any crashes occur during emulation, this script throws a matching signal
to tell AFL that a crash occurred.
Run under AFL as follows:
$ cd <afl_path>/unicorn_mode/samples/simple/
$ ../../../afl-fuzz -U -m none -i ./sample_inputs -o ./output -- python simple_test_harness.py @@
"""
import argparse
import os
import signal
from unicorn import *
from unicorn.mips_const import *
# Path to the file containing the binary to emulate
BINARY_FILE = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'simple_target.bin')
# Memory map for the code to be tested
CODE_ADDRESS = 0x00100000 # Arbitrary address where code to test will be loaded
CODE_SIZE_MAX = 0x00010000 # Max size for the code (64kb)
STACK_ADDRESS = 0x00200000 # Address of the stack (arbitrarily chosen)
STACK_SIZE = 0x00010000 # Size of the stack (arbitrarily chosen)
DATA_ADDRESS = 0x00300000 # Address where mutated data will be placed
DATA_SIZE_MAX = 0x00010000 # Maximum allowable size of mutated data
try:
# If Capstone is installed then we'll dump disassembly, otherwise just dump the binary.
from capstone import *
cs = Cs(CS_ARCH_MIPS, CS_MODE_MIPS32 + CS_MODE_BIG_ENDIAN)
def unicorn_debug_instruction(uc, address, size, user_data):
mem = uc.mem_read(address, size)
for (cs_address, cs_size, cs_mnemonic, cs_opstr) in cs.disasm_lite(bytes(mem), size):
print(" Instr: {:#016x}:\t{}\t{}".format(address, cs_mnemonic, cs_opstr))
except ImportError:
def unicorn_debug_instruction(uc, address, size, user_data):
print(" Instr: addr=0x{0:016x}, size=0x{1:016x}".format(address, size))
def unicorn_debug_block(uc, address, size, user_data):
print("Basic Block: addr=0x{0:016x}, size=0x{1:016x}".format(address, size))
def unicorn_debug_mem_access(uc, access, address, size, value, user_data):
if access == UC_MEM_WRITE:
print(" >>> Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value))
else:
print(" >>> Read: addr=0x{0:016x} size={1}".format(address, size))
def unicorn_debug_mem_invalid_access(uc, access, address, size, value, user_data):
if access == UC_MEM_WRITE_UNMAPPED:
print(" >>> INVALID Write: addr=0x{0:016x} size={1} data=0x{2:016x}".format(address, size, value))
else:
print(" >>> INVALID Read: addr=0x{0:016x} size={1}".format(address, size))
def force_crash(uc_error):
# This function should be called to indicate to AFL that a crash occurred during emulation.
# Pass in the exception received from Uc.emu_start()
mem_errors = [
UC_ERR_READ_UNMAPPED, UC_ERR_READ_PROT, UC_ERR_READ_UNALIGNED,
UC_ERR_WRITE_UNMAPPED, UC_ERR_WRITE_PROT, UC_ERR_WRITE_UNALIGNED,
UC_ERR_FETCH_UNMAPPED, UC_ERR_FETCH_PROT, UC_ERR_FETCH_UNALIGNED,
]
if uc_error.errno in mem_errors:
# Memory error - throw SIGSEGV
os.kill(os.getpid(), signal.SIGSEGV)
elif uc_error.errno == UC_ERR_INSN_INVALID:
# Invalid instruction - throw SIGILL
os.kill(os.getpid(), signal.SIGILL)
else:
# Not sure what happened - throw SIGABRT
os.kill(os.getpid(), signal.SIGABRT)
def main():
parser = argparse.ArgumentParser(description="Test harness for simple_target.bin")
parser.add_argument('input_file', type=str, help="Path to the file containing the mutated input to load")
parser.add_argument('-d', '--debug', default=False, action="store_true", help="Enables debug tracing")
args = parser.parse_args()
# Instantiate a MIPS32 big endian Unicorn Engine instance
uc = Uc(UC_ARCH_MIPS, UC_MODE_MIPS32 + UC_MODE_BIG_ENDIAN)
if args.debug:
uc.hook_add(UC_HOOK_BLOCK, unicorn_debug_block)
uc.hook_add(UC_HOOK_CODE, unicorn_debug_instruction)
uc.hook_add(UC_HOOK_MEM_WRITE | UC_HOOK_MEM_READ, unicorn_debug_mem_access)
uc.hook_add(UC_HOOK_MEM_WRITE_UNMAPPED | UC_HOOK_MEM_READ_INVALID, unicorn_debug_mem_invalid_access)
#---------------------------------------------------
# Load the binary to emulate and map it into memory
print("Loading data input from {}".format(args.input_file))
binary_file = open(BINARY_FILE, 'rb')
binary_code = binary_file.read()
binary_file.close()
# Apply constraints to the mutated input
if len(binary_code) > CODE_SIZE_MAX:
print("Binary code is too large (> {} bytes)".format(CODE_SIZE_MAX))
return
# Write the mutated command into the data buffer
uc.mem_map(CODE_ADDRESS, CODE_SIZE_MAX)
uc.mem_write(CODE_ADDRESS, binary_code)
# Set the program counter to the start of the code
start_address = CODE_ADDRESS # Address of entry point of main()
end_address = CODE_ADDRESS + 0xf4 # Address of last instruction in main()
uc.reg_write(UC_MIPS_REG_PC, start_address)
#-----------------
# Setup the stack
uc.mem_map(STACK_ADDRESS, STACK_SIZE)
uc.reg_write(UC_MIPS_REG_SP, STACK_ADDRESS + STACK_SIZE)
#-----------------------------------------------------
# Emulate 1 instruction to kick off AFL's fork server
# THIS MUST BE DONE BEFORE LOADING USER DATA!
# If this isn't done every single run, the AFL fork server
# will not be started appropriately and you'll get erratic results!
# It doesn't matter what this returns with, it just has to execute at
# least one instruction in order to get the fork server started.
# Execute 1 instruction just to startup the forkserver
print("Starting the AFL forkserver by executing 1 instruction")
try:
uc.emu_start(uc.reg_read(UC_MIPS_REG_PC), 0, 0, count=1)
except UcError as e:
print("ERROR: Failed to execute a single instruction (error: {})!".format(e))
return
#-----------------------------------------------
# Load the mutated input and map it into memory
# Load the mutated input from disk
print("Loading data input from {}".format(args.input_file))
input_file = open(args.input_file, 'rb')
input = input_file.read()
input_file.close()
# Apply constraints to the mutated input
if len(input) > DATA_SIZE_MAX:
print("Test input is too long (> {} bytes)".format(DATA_SIZE_MAX))
return
# Write the mutated command into the data buffer
uc.mem_map(DATA_ADDRESS, DATA_SIZE_MAX)
uc.mem_write(DATA_ADDRESS, input)
#------------------------------------------------------------
# Emulate the code, allowing it to process the mutated input
print("Executing until a crash or execution reaches 0x{0:016x}".format(end_address))
try:
result = uc.emu_start(uc.reg_read(UC_MIPS_REG_PC), end_address, timeout=0, count=0)
except UcError as e:
print("Execution failed with error: {}".format(e))
force_crash(e)
print("Done.")
if __name__ == "__main__":
main()创建一些测试输入并自行运行测试工具,以验证它是否按预期模拟代码(和崩溃)。现在测试工具已启动并运行,创建一些示例输入并在 afl-fuzz 下运行,如下所示。
确保添加 '-U' 参数以指定 Unicorn Mode,我建议将内存限制参数('-m')设置为 'none',因为运行 Unicorn 脚本可能需要相当多的 RAM。遵循正常的 AFL 惯例,将包含文件路径的参数替换为使用 '@@' 进行模糊处理(有关详细信息,请参阅AFL的自述文件)
afl-fuzz -U -m none -i /path/to/sample/inputs -o /path/to/results
-- python simple_test_harness.py @@如果一切按计划进行,AFL 将启动并很快找到一些崩溃点。

然后,您可以手动通过测试工具运行崩溃输入(在results / crashes /目录中找到),以了解有关崩溃原因的更多信息。我建议保留 Unicorn 测试工具的第二个副本,并根据需要进行修改以调试仿真中的崩溃。例如,您可以打开指令跟踪,使用 Capstone 进行反汇编,在关键点转储寄存器等。
一旦您认为自己有一个有效的崩溃,就需要找到一种方法将其传递给仿真之外的实际程序,并验证崩溃是否适用于实际物理系统。
值得注意的是,整体模糊测速度和性能在很大程度上取决于测试线束的速度。基于 Python 的大型复杂测试工具的运行速度比紧密优化的基于 C 的工具要慢得多。如果您计划运行大量长时间运行的模糊器,请务必考虑这一点。作为一个粗略的参考点,我发现基于 C 的线束每秒可以比类似的 Python 线束多执行 5-10 倍的执行。
更深层次的用法
虽然我最初创建它是为了发现嵌入式系统中的漏洞(如 Project Zero 和 Comsecuris 在 Broadcom WiFi 芯片组中发现的那些漏洞),但在我的后续博客文章中,我将发布工具并描述使用 afl-unicorn 进行模糊测试的方法在 Windows,Linux 和 Android 进程中模拟功能。
- Afl-unicorn 不仅可用于查找崩溃,还可用于进行基本路径查找。在测试工具中,如果执行特定指令(或您选择的任何其他条件),您可以强制崩溃。
AFL 将捕获这些“崩溃”并存储导致满足该条件的输入。这可以替代符号分析,以发现深入分析逻辑树的输入。
Unicorn 和 Capstone 的制造商最近发布的图片暗示 AFL 支持可能即将推出...... 看看他们创造了哪些功能,以及是否有任何合作机会来优化我们的工具。
结尾
我在美国俄亥俄州哥伦布的 Battelle 担任网络安全研究员时,开发了 afl-unicorn 作为内部研究项目。 Battelle 是一个很棒的工作场所,afl-unicorn 只是在那里进行的新型网络安全研究的众多例子之一。
有关 Battelle 赞助的更多项目,请查看 Chris Domas和John Toterhi 之前的工作。有关 Battelle 职业生涯的信息,请查看他们的职业页面。
当然,如果没有 AFL 和 Unicorn Engine,这一切都不可能实现。 Alex Hude 为 IDA 提供了很棒的 uEmu 插件,其他许多灵感来源于 NCC 集团的 AFLTriforce 项目。
原文链接:https://hackernoon.com/afl-unicorn-fuzzing-arbitrary-binary-code-563ca28936bf
 转载
转载
 分享
分享



没有评论