
字符流导致乱码的ctf题
问题简介
周末闲来无事,刷题!在刷一道简单的jarviosj网站上的题目的时候,发现了一个很多人都做出来,但是却有个问题,无人指出/指出了貌似还存在错误的情况...
那么现在开始对此问题进行分析
问题由来
题目是jarvisoj网站re栏目的FindPass题目.
正常的流程拿着jadx_gui分析该apk
发现其实就是很简单的流程,从res目录中(需要反编译)获取到一段字符串,从assets目录下获取到图片,载入1024个字节,然后进行简单的算法,最后判断是否相等...

其实这个过程很简单,所以当时我就直接写exp了...
key = 'Tr43Fla92Ch4n93'
with open('src.jpg', 'rb') as f:
image_data = f.read()
flag = ""
for i in range(len(key)):
if i % 2 == 1:
flag += chr(ord(key[i]) + temp)
else:
flag += chr(ord(key[i]) - temp)
print flag
#输出结果是Qv49AmZB2Df4jB-
但是输入到apk中,却是错误的,思考了一会儿,怀疑是不是java中char是有符号单字节数据,而python中是无符号的单字节数据,所以flag不对...(这个猜想是错误的,后面会有解释)
所以我去将符号增加,并且模128,最后进行运算,最后跑出来的答案是对的,也符合了最后的flag(这真的是碰巧,运气好,才会在这种情况下猜对)
key = 'Tr43Fla92Ch4n93'
with open('src.jpg', 'rb') as f:
image_data = f.read()
flag = ""
for i in range(len(key)):
if ord(image_data[ord(key[i])]) < 128:
temp = ord(image_data[ord(key[i])]) % 10
else:
temp = -(ord(image_data[ord(key[i])]) % 128) % 10
if i % 2 == 1:
flag += chr(ord(key[i]) + temp)
else:
flag += chr(ord(key[i]) - temp)
print flag
#错误的flag:Qv49AmZB2Df4jB-
#正确的flag:Qv49CmZB2Df4jB-
仔细对于一下两个flag,其实就第五位存在变化
但是在我写这段代码的时候,我突然想着这道题也可以调试,一口气直接出结果,所以就当复习调试,就重新走了一遍,但是这次调试,却发现了不一样的结果
问题发现
调试工具走起
android studio,个人觉得全世界最牛皮的apk调试/开发工具,在android3.0版本之后,在File工具栏就存在Profile or Debug APK 的功能,直接选择需要调试的apk
这里首先要对于我们这道题的apk增加android:debuggable="true"属性,否则没法调试
然后选择符合apk的sdk,在project structure->module里面设置好符合apk版本的sdk
然后插上我们开启的usb调试选项的手机
以上三个条件,缺一不可...各种报错就因为这三个原因
等待1分钟载入so文件,就可以开始快乐调试了
调试
因为as只能调试smali文件,所以并不是特别的直观,所以尽量结合这jadx_gui反编译出来的java一起看,比较容易懂
然后一定要仔细看下面的变量窗口,这个窗口,就是调试的关键
当F8很多次之后,调试到这一行,我们就会发现,为什么出现了问题?
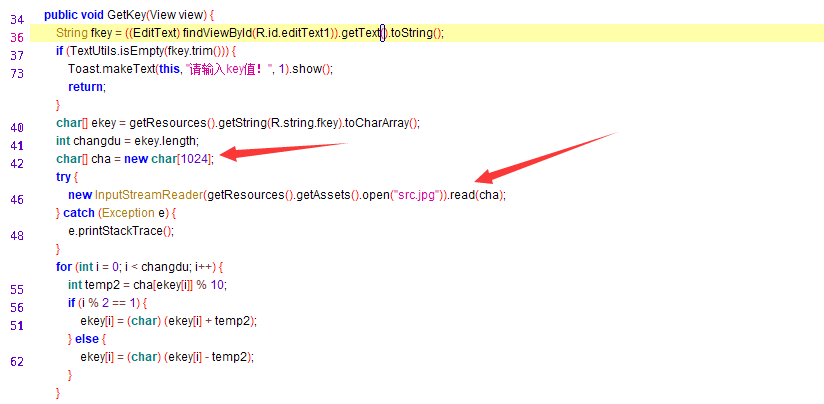
getkey函数,里面的cha变量存储了一个1024字节的字符数组,读入jpg文件,肯定是二进制内容,但是这里,就在这里出现了大问题
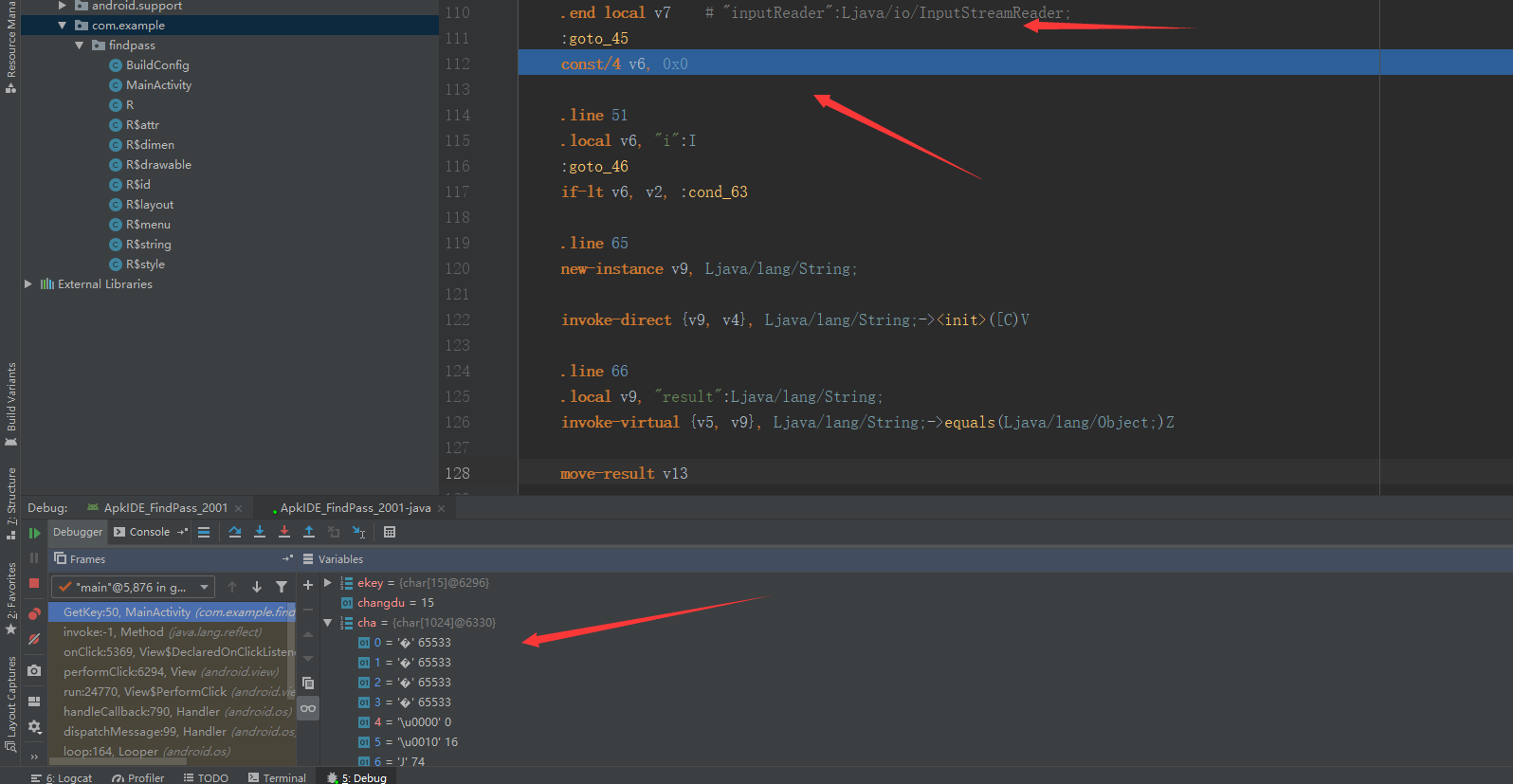
这个jpg的头部,我们用010editor打开,其实是这样的

但是为什么,apk调试出来的结果,jpg读取到的字符串的开头就是65533呢?
想到这里,我再次测试了一波,在图片中寻找到三个数据,查看载入之后的数值
0x7E和0x7F和0x80的数据对比:
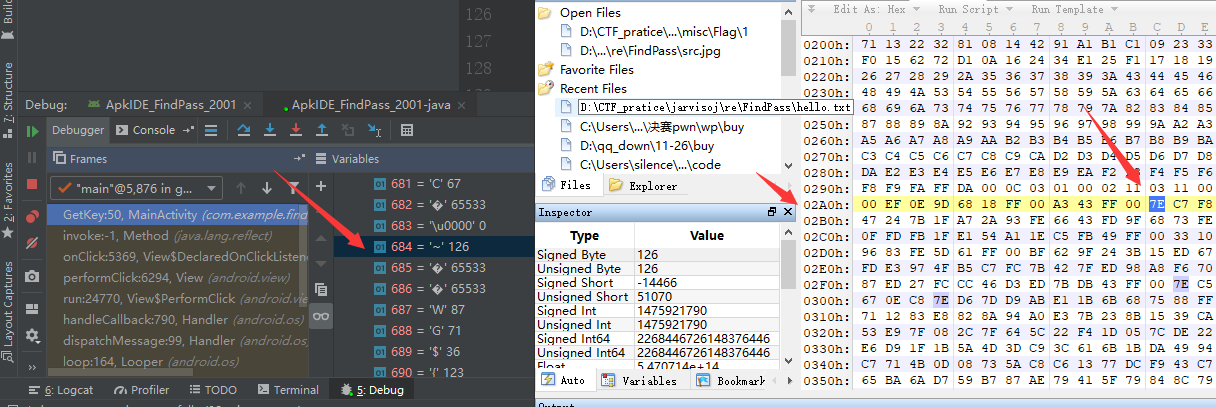
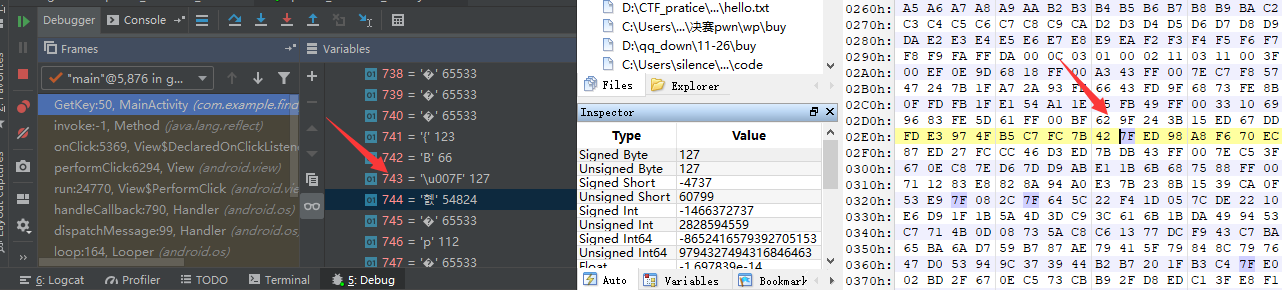
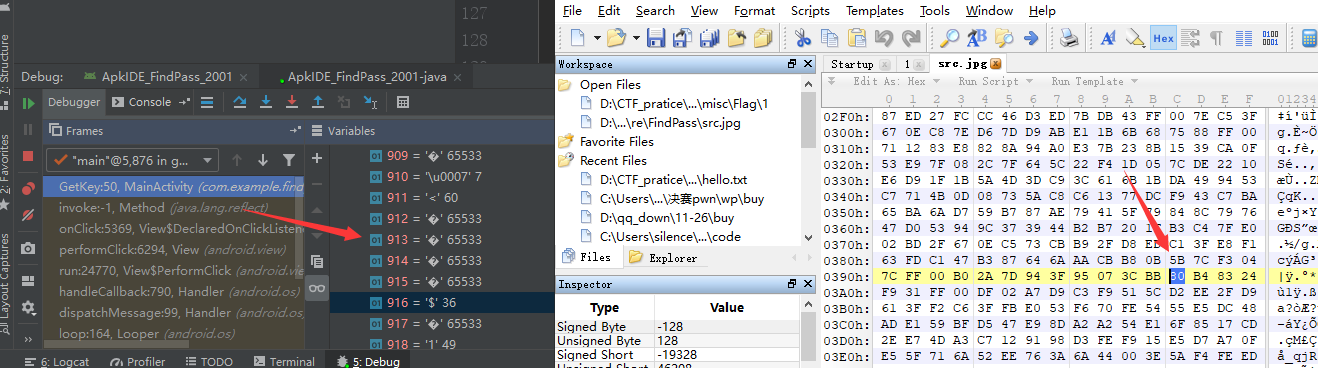
我们可以很清楚的发现,当一个字节的第一个bit位为1的时候,那么InputStreamReader函数读入该字节的时候,就会默认转为0xFFFD,也就是65533...
所以实际上,内存上所有大于127的数据,在这道题目读入之后,都是变成65533,然后在获取这道题的flag的过程中,模取10,最后会等于3,然后再根据奇偶位,确定是加一还是减一...
回到题目,F(70)-3当然等于C(67),而不是因为有符号的数据需要转换的成无符号的数据,这次正好是正巧好,才会出现两种不同的原因解出同一个flag
所以这道题,根本就不是我之前的猜想,我同时也查阅了很多网上对于该题目的writeup,貌似发现,都是认为是有符号和无符合的转换问题
那么下面,继续对于该InputStreamReader函数进行深入分析
- 这个函数的功能是什么?
- 为什么它会将所有大于127的数据转换成65533?
- 明明一个字节的数据,为什么调试的时候会显示成两个字节的数据?
- 为什么是0xFFFD,为什么不是0xFFFF,为什么不是其它?
深入分析
首先是引入字节流和字符流的概念:
字节流、字符流,两类都分为输入和输出操作。
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。
而InputStreamReader正是从字节流到字符流的桥梁.
FileReader的父类InputStreamReader,它是从字节流到字符流的桥梁:它读取字节并使用特定的字符集解码成字符。字符集可能通过名字来确定或者直接特别给出或者是平台的默认字符集。
InputStreamReader的每一个read方法的调用可能会引起一个或多个字节从字节输出流中被读取。为了使字节能够有效的转换为字符,可能会提前从流中读取比当前读取操作所需字节数更多的字节。
InputStreamReader继承了抽象类Reader,Reader中实现了一些具体方法,这些方法没有在InputStreamReader中重写,比如skip方法。InputStreamReader有一个核心内部变量StreamDecoder,这个类的作用是将输入的字节转换为字符,后面会具体分析。
而且通过分析源码可知,该函数每次都会读入两个字节,进行解码,而解码需要字符集之间的转换
为了让使用Java语言编写的程序能在各种语言的平台下运行,Java在其内部使用Unicode字符集来表示字符,这样就存在Unicode字符集和本地字符集进行转换的过程。当在Java中读取字符数据的时候,需要将本地字符集编码的数据转换为Unicode编码,而在输出字符数据的时候,则需要将Unicode编码转换为本地字符集编码。
也就是说,所有读入的数据都会在unicode和本地字符集之间进行转换,那么我们读入jpg图片文件的时候(在那道赛题中使用的是默认的字符集,也就是系统字符集):
从其他字符集向Unicode编码转换时,如果这个二进制数在该字符集中没有标识任何的字符,则得到的结果是0xfffd。例如一个GBK的编码值0x8140,从GB2312向Unicode转换,然而由于0x8140不在GB2312字符集的编码范围(0xa1a1-0xfefe),当然也就没有对应任何的字符,所以转换后会得到0xfffd。
所以上面的所有问题,全部都迎刃而解了,舒服了
同时我还写了一些java代码和c语言代码进行测试,验证了上面所说的字节流和字符流的区别,在附件中,就不截图了,大家可以自己运行试试,还有一个帮大家加上了debug属性的apk,大家可以自己调试
怀疑任何事情,才能发现问题的真正答案!
参考链接
-
 附件.rar
下载
附件.rar
下载
 转载
转载
 分享
分享



没有评论