
NodeJS Headless 动态漏扫爬虫学习记录(爬虫篇)
前言
在两年前谷歌推出了一个Headless Chrome NodeJS API:Puppeteer,后来Github一个大牛用Python封装了一套api,作为一个第三方api:Pyppeteer。
在去年的时候,尝试过用Pyppeteer写过动态爬虫,Python版由于是第三方一个作者封装的,更新很慢,落后官方版本很多,很多迷之BUG,比如CDP协议去操作远程chromium,很容易中断导致一堆僵尸进程的chromium关不掉。虽然最后还是顶着各种bug,写成一个勉强能用的工具,但在服务器上很吃内存,一方面也是因为写的任务调度机制也有一些问题,最后服役了许多天天,不想维护了,捡了几个漏洞就退休了。后来在平时的工作和学习中频频接触到nodeJS,于是就趁着这段时间用nodejs重新实现一遍。
JS基础
JS中的事件模型
分为:内联、DOM0级、DOM2级事件

JS原型链介绍
Js是一种基于原型的语言,每一个对象都有一个原型对象,对象以其原型为模板、从原型继承方法和属性。原型对象也可能拥有原型,一层一层、以此类推。
在传统的面向对象编程中,我们首先会定义“类”,此后创建对象实例时,类中定义的所有属性和方法都被复制到实例中。但在 js 中并不是像这样复制,而是在对象实例和类之间之间建立一个链接。
demo:
function Cat() {
this.color = 'test'
}
var cat = new Cat()
console.log(cat.__proto__ === Cat.prototype) // true

在 JavaScript 中,如果想访问某个属性,首先会在实例对象(cat)的内部寻找,如果没找到,就会在该对象的原型(cat._proto_,即 Cat.prototype)上找,我们知道,对象的原型也是对象,它也有原型,如果在对象的原型上也没有找到目标属性,则会在对象的原型的原型(Cat.prototype._proto_)上寻找,以此内推,直到找到这个属性或者到达了最顶层。在原型上一层一层寻找,这便是原型链了。
如何抓取更多的URL
几种思路,可以直接使用正则抓取,也可以解析各种含有链接的标签,也就是src,href属性等。
当然这些都有一定的缺陷,比如相对路径需要单独去处理成完整URl,有的使用的js跳转,而不把URl写到标签内等等。另一种思路即使用动态爬虫的思路,Hook JS,通过触发各种事件信息收集URL。这里计划第一版爬虫先实现简易的URL抓取,之后再进一步优化。首先最常想到的是使用正则抓取,其次可以利用Headless的优势,将动态JS渲染的链接标签、属性抓取。
收集src、href属性的标签
function getSrcAndHrefLinks(nodes) {
let result = [];
for(let node of nodes){
let src = node.getAttribute("src");
let href = node.getAttribute("href");
let action = node.getAttribute("action");
if (src){
result.push(src)
}
if (href){
result.push(href);
}
if(action){
result.push(action);
}
}
return result;
}
const links = await page.$$eval('[src],[href],[action]', getSrcAndHrefLinks);爬行结果:

接着通过简单的URL去重、清洗,爬虫便可以进行迭代爬行了。
经过一番测试后发现,对于下面这种页面URL抓取是会有遗漏的:
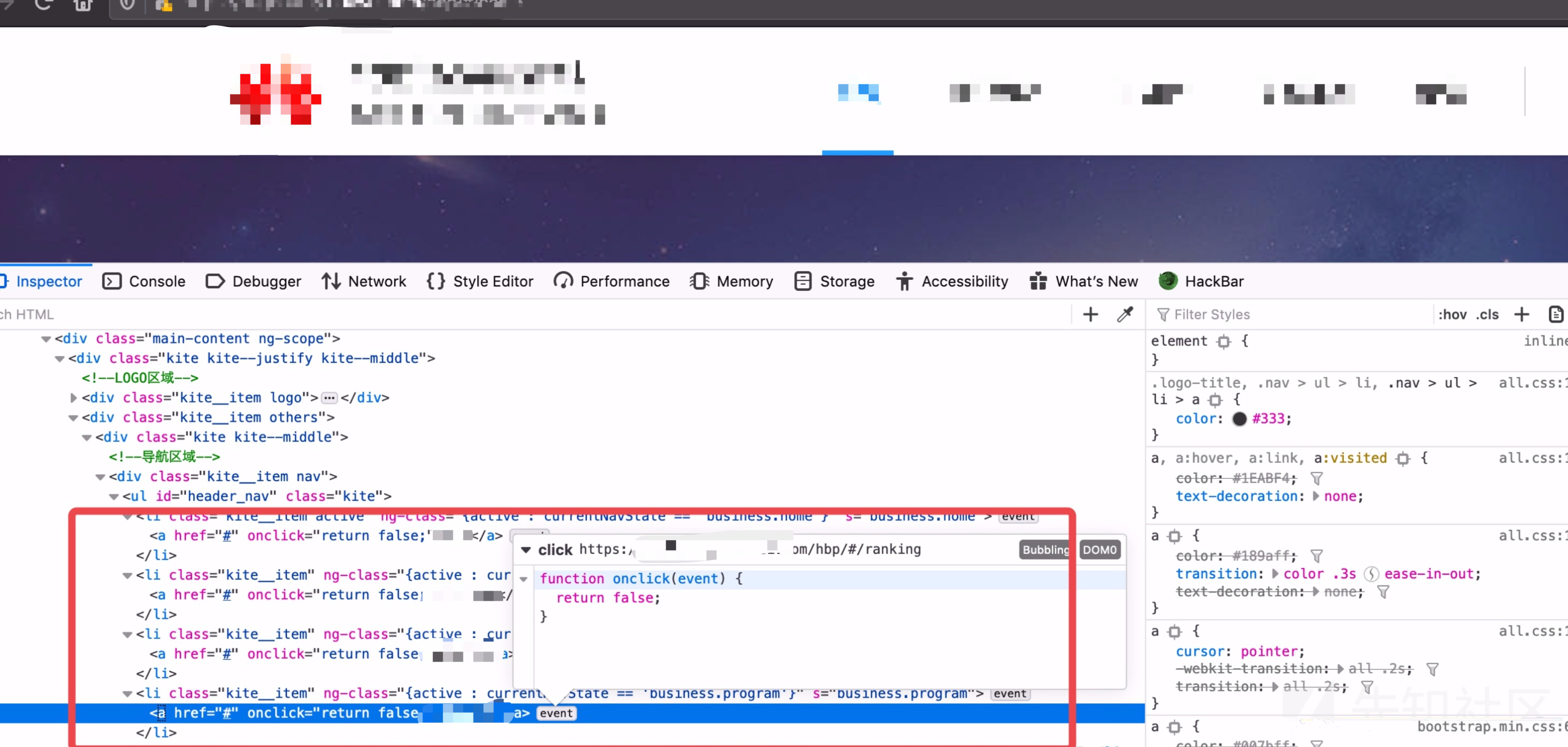
有的将跳转操作全写入了js事件中,或者有的要进行页面滚动JS才会进一步渲染,无疑遗漏了很多URL。解决这些问题的关键在于模拟用户操作,而用户操作的本质则为触发各种DOM事件。所以接下来需要解决的问题在于收集各种DOM事件,以及去触发它们。
收集DOM事件
在学习收集DOM事件的过程中参考了9ian1i师傅以及fate0师傅文章,很感谢前辈们的探索。
Hook事件
注册事件分为DOM0和DOM2事件,使用方法不同,收集方法也有差异。这里简单介绍了两者的差异DOM0级事件和DOM2级事件区别。以及JavaScript Prototype Chain 原型链学习
DOM0
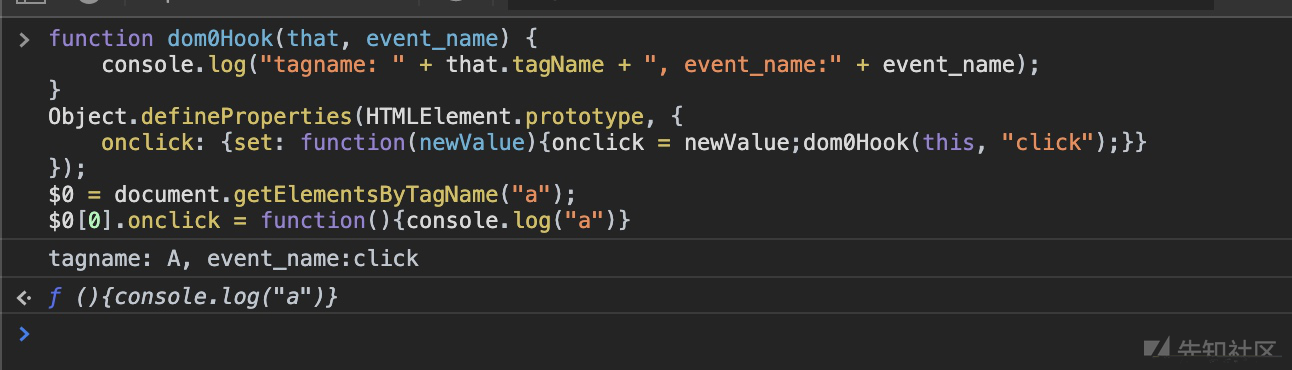
对于DOM0的事件监听,可以修改所有节点的相关属性原型,设置其访问器属性。
demo:
function dom0Hook(that, event_name) {
console.log("tagname: " + that.tagName + ", event_name:" + event_name);
}
Object.defineProperties(HTMLElement.prototype, {
onclick: {set: function(newValue){onclick = newValue;dom0Hook(this, "click");}},
onchange: {set: function(newValue){onchange = newValue;dom0Hook(this, "change");}}
});
$0 = document.getElementsByTagName("a");
$0[0].onclick = function(){console.log("a")
}
DOM2
DOM2级事件Hook,可以通过修改addEventListener的原型即可:
let oldEvent = Element.prototype.addEventListener;
Element.prototype.addEventListener = function(event_name, event_func, useCapture) {
console.log("tagname: " + this.tagName + ", event_name:" + event_name);
oldEvent.apply(this, arguments);
};

内联事件
除了上述两种绑定事件的办法,还有通过写在标签内的内联事件,无法通过Hook来收集。比如:
<div id="test" onclick="alert('1')">123</div>
解决办法是通过遍历节点,执行on事件:
function trigger_inline(){
var nodes = document.all;
for (var i = 0; i < nodes.length; i++) {
var attrs = nodes[i].attributes;
for (var j = 0; j < attrs.length; j++) {
attr_name = attrs[j].nodeName;
attr_value = attrs[j].nodeValue;
if (attr_name.substr(0, 2) == "on") {
console.log(attrs[j].nodeName + ' : ' + attr_value);
eval(attr_value);
}
if (attr_name in {"src": 1, "href": 1} && attrs[j].nodeValue.substr(0, 11) == "javascript:") {
console.log(attrs[j].nodeName + ' : ' + attr_value);
eval(attr_value.substr(11));
}
}
}
}

或者TreeWalker获取全部节点,用
dispatchEvent挨个触发事件
而DOM0、DOM2级事件通过收集到的标签和事件名依次触发即可。
导航锁定
触发事件的过程中,可能会被意外的导航请求给中断操作,所以我们应当取消非本页面的导航请求,避免造成漏抓。
前端JS跳转
取消跳转操作,记录跳转URL,但是Chrome不允许我们通过Object.defineProperty重定义window.Location操作,即无法通过Hook获取跳转的URL。
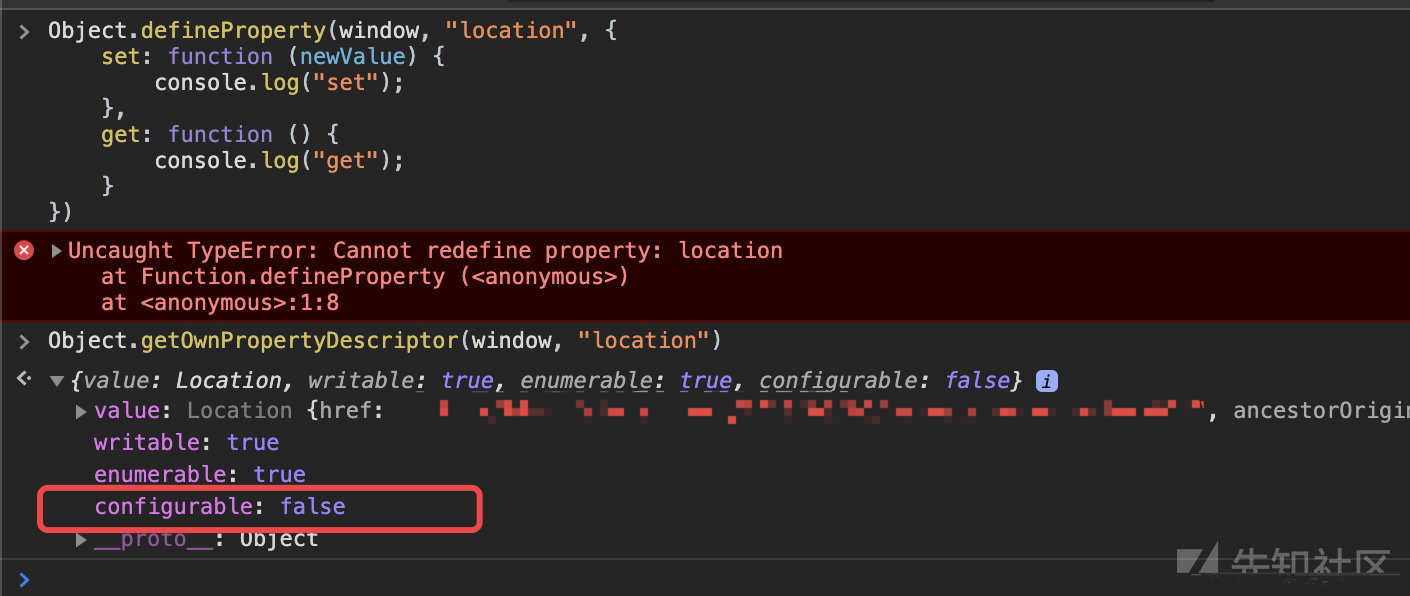
搜索了一些资料之后大致有下边一些解决办法:
- 修改Chromium默认location属性的configurable为true
- 加载自定义插件
- 使用puppeteer的拦截器返回204状态码
但最后我选择了为漏扫动态爬虫定制的浏览器,后边会细说。
后端跳转
请求体无内容,则跟进;请求体有内容,则渲染页面,记录跳转url。
表单填充
锁定重置表单事件
HTMLFormElement.prototype.reset = function() {
console.log("cancel reset form")
};
Object.defineProperty(HTMLFormElement.prototype, "reset", {"writable": false, "configurable": false}
);
填坑
为漏扫动态爬虫定制的浏览器
解决这个前端导航hook问题的时候,发现github上有一个大牛通过修改源码实现了一个为漏扫定制版的Chrome。作者通过修改chromium源码实现了导航的Hook,禁止页面的天锻跳转并收集其跳转的URL,并且通过底层hook了所有非默认事件,为我们开发提供了很多便利。
但还是有一些小的地方需要我们自己优化一下,会锁定导航自动收集前端跳转URL,但不会处理后端的Location,这里我们用一个拦截器去实现,记录后端跳转,加入扫描队列:
await page.on('response', interceptedResponse =>{
let status = interceptedResponse.status();
if(status.toString().substr(0,2) === "30"){
console.log("url: " + interceptedResponse.url());
console.log("status: " + status);
console.log("headers: " + interceptedResponse.headers().location);
// 添加进任务队列
cluster.queue(interceptedResponse.headers().location);
}
});
事件触发&收集结果
function executeEvent() {
var firedEventNames = ["focus", "mouseover", "mousedown", "click", "error"];
var firedEvents = {};
var length = firedEventNames.length;
for (let i = 0; i < length; i++) {
firedEvents[firedEventNames[i]] = document.createEvent("HTMLEvents");
firedEvents[firedEventNames[i]].initEvent(firedEventNames[i], true, true);
}
var eventLength = window.eventNames.length;
for (let i = 0; i < eventLength; i++) {
var eventName = window.eventNames[i].split("_-_")[0];
var eventNode = window.eventNodes[i];
var index = firedEventNames.indexOf(eventName);
if (index > -1) {
if (eventNode != undefined) {
eventNode.dispatchEvent(firedEvents[eventName]);
}
}
}
let result = window.info.split("_-_");
result.splice(0,1);
return result;
}

添加cookie
对于使用SSO单点站点体系而言,可以在开始爬行之前指定一段cookie,比如从文本中读取。但是对于爬行目标较为多且SSO的覆盖面有限的情况下,就得使用数据库了。在测试过程中遇到了另一个问题,就是并发过高,或者发送有害的payload,会有Cookie失效的问题,这里想到了一种比较实用的解决办法,写一个浏览器插件及时将当前页面的cookie同步到服务端数据库,然后爬虫定期从数据库中更新最新的cookie。
Chrome插件同步cookie
function updateCookie(domain, name , value){
let api = "http://127.0.0.1/add-cookie";
$.post(api, {
"domain": domain,
"name": name,
"value": value,
}, function (data, status) {
console.log(status);
});
}
/*
* doc: https://developer.chrome.com/extensions/cookies
*/
chrome.cookies.onChanged.addListener((changeInfo) =>{
// 记录Cookie增加,Cookie更新分两步,第一步先删除,第二步再增加
if(changeInfo.removed === false){
updateCookie(changeInfo.cookie.name, changeInfo.cookie.value, changeInfo.cookie.domain);
}
});
相似URL去重
去重在爬虫中是一个较为核心功能,规则过于宽松可能导致爬行不完或者说做一些无意义的重复爬行,规则过于严格则可能导致抓取结果过少,影响后续抓取和漏洞检测。去重一般分为两步对爬行队列去重,或者对结果集去重。
在解决这个问题的时候,参考了Fr1day师傅【技术分享】浅谈动态爬虫与去重的URL去重思路。不失为一种比较便捷,能基本满足当前需求的一种解决办法。
参数分析
大致有以下几种参数:类型int、hash、中文、URL编码
?m=home&c=index&a=index
?type=202cb962ac59075b964b07152d234b70
?id=1
?msg=%E6%B6%88%E6%81%AF根据不同的类型对其进行处理:
- 纯字母:中参数的值表示不同的路由功能,需要对这种参数进行保留
- 字母数字混合:可能是用户的hash,也可能具有路由功能,可根据任务量情况选择性保留
- 纯数字、URl编码:进行去重
处理结果即:
?m=home&c=index&a=index
?type={hash}
?id={int}
?msg={urlencode}然后在数据库中将相同的清洗掉即可。
相似页面去重
相似度计算,监控资产变化
网页结构相似度:http://xueshu.baidu.com/usercenter/paper/show?paperid=232b0da253211ecf9e2c85cb513d0bd3&site=xueshu_se
填坑
性能优化
图片资源优化
禁止浏览器加载图片 => 返回一个fake img
实际测试过程中,有的网站在加载图片失败后,会尝试重新加载,这样会陷入一个死循环,导致发送大量数据包,占用性能。


代码:
const browser = await puppeteer.launch(launchOptions);
const page = await browser.newPage();
await preparePage(page);
await page.setRequestInterception(true); // 开启拦截功能
await page.on('request', interceptedRequest => {
// 拦截图片请求
if (interceptedRequest.resourceType() === 'image' || interceptedRequest.url().endsWith('.ico')) {
//console.log(`abort image: ${interceptedRequest.url()}`);
let images = fs.readFileSync('public/image.png');
interceptedRequest.respond({
'contentType': ' image/png',
'body': Buffer.from(images)
});
}
else {
interceptedRequest.continue();
}
拦截logout请求
避免爬虫爬行到登出链接,导致Cookie失效,这里做一个简单的拦截:
await page.on('request', interceptedRequest => {
if(interceptedRequest.url().indexOf("logout") !== -1){
interceptedRequest.abort();
}
else{
interceptedRequest.continue();
}
});
puppeteer并发异步调度方案
简单粗暴,这里使用puppeteer-cluster库解决单Chrome多tab并发需求,也可以参考使用guimaizi师傅的demo:puppeteer异步并发方案
开源
这里边其实还有很多坑要填,师傅们多指点交流~
开源链接:https://github.com/Passer6y/CrawlerVuln
(求star
最后
非常感谢各位前辈师傅们的技术分享,欢迎一起交流,在下一篇中我将分享自己对于漏洞检测的一点理解。
 转载
转载
 分享
分享
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-

@threedr3am 应该还是不同的:
1、js的原型核心特点在于对象以其原型为模板、从原型继承方法和属性,也就是对象和对象的原型(构造对象的对象)指向了同一个原型;
2、js的原型存在“链”的关系,即“原型链”,如果要访问某个属性,首先会在实例对象(cat)的内部寻找,如果没找到,就会在该对象的原型(xxx.proto,即 xxx.prototype)上找,如果找不到,则会在对象的原型的原型(xxx.prototype.proto)上寻找,以此类推,直到找到这个属性或者到达了最顶层。而java中没有这种链式的关系。
js中的原型,是不是可以类比为java中的类呢?java中的类在实例化之后,并不会复制到实例中,类信息还是存在于常量池方法区中,而对象实例则存放在堆中,对象头会包含锁、年龄、类等信息,而类信息指的就是方法区中的类数据(字段、属性、方法等),而类也可以继承自另一个类,具体到对象中,public的字段、方法,对象都能访问到。这样,是否意味着js中的原型就相当于java中的类?
感谢分享,刚好最近也在研究动态爬虫。