
文章前言
MPT(Merkle Patrica Tree)是以太坊中用于存储任意数据对(key->Value)的树形结构,它主要用于存储用户的状态信息、交易信息、交易收据等,而且它的插入、查找和删除效率都是O(Log(N)),在以太坊中MPT为三种数据结构的集合:Trie、Patricia Trie、Merkle,下面将分别对此进行详细的介绍,同时我们将对默克尔树构造中的安全问题进行一个简易的梳理并给出一个安全示例供大家思考
树形结构
Trie Tree
Trie又被称之为字典树,它是一种用于快速检索的多叉树结构,例如我们的英文字母的字典树就是一个26叉数,阿拉伯数字的字典树是一个典型的10叉树,这里的Trie树通过利用字符串的公共前缀来节约存储空间,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的Trie树将变得非常消耗内存,这也是Trie树的一个缺点。
Trie Tree具备以下特点:
- 根节点不包含字符,除根节点以外每个节点仅包含一个字符
- 每一个节点的所有子节点包含的字符串不相同
- 节点对应的字符串由根节点到某一节点路径上经过的所有字符链接而成
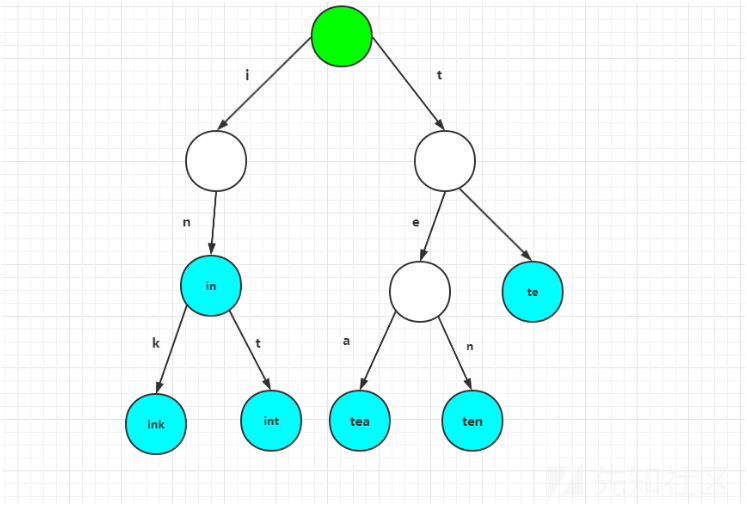
如下图所示,该Trie Tree用了10个节点保存了6个字符串:tea、ten、to、in、int、ink,可以看到这里的ink与int用了一个前缀——"in",从而实现了对存储空间的节省,但是如果存储的字符串没有公共的前缀时则使用Trie Tree就会变得非常消耗内存,而这也是Trie树的一个缺点:
Patricia Tries
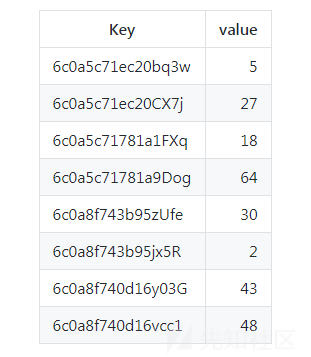
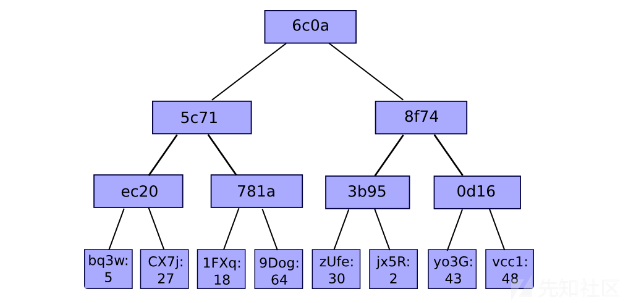
Patricia Tries又称之为"前缀树",它和Trie树的不同之处在于Trie树是为每一个字符串分配一个节点,而前缀树是将那些很长但又没有公共节点的字符串的Trie树退化成数组,前缀树的不同之处在于如果节点前缀相同则就使用公共的前缀,否则就把剩下的所有节点插入同一个节点,例如:
Merkle Tree
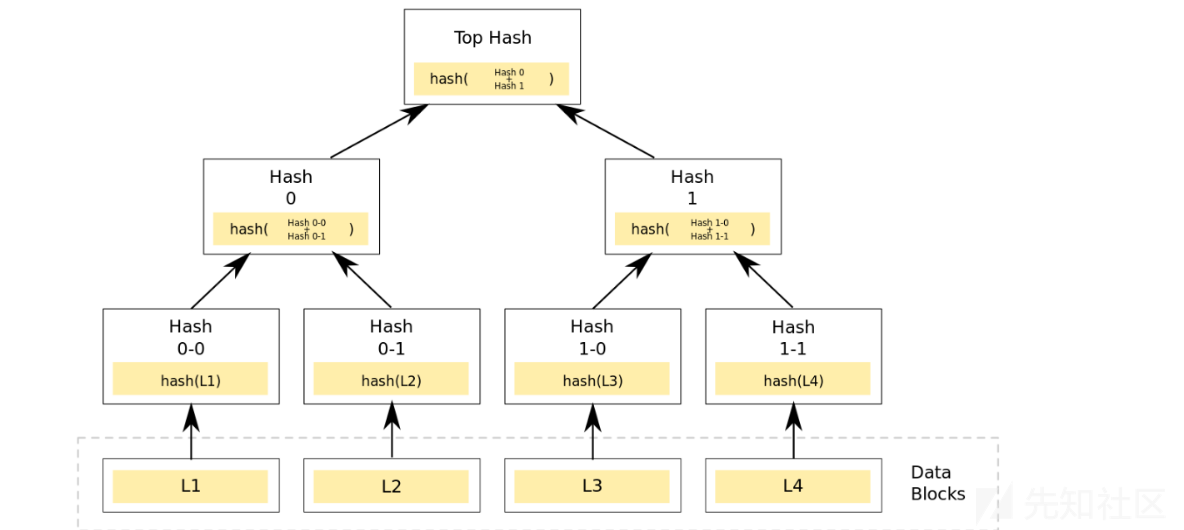
Merkle Tree,通常也被称作Hash Tree,顾名思义就是存储hash值的一棵树,Merkle树的叶子是数据块的hash值,非叶节点是其对应子节点串联字符串的hash,当我们拿到Merkle Tree的Top Hash的时候(代表了整颗树的信息摘要),当树里面任何一个数据发生了变动,都会导致Top Hash的值发生变化,所以只要拿到一个区块头,就可以对区块信息进行验证
MPT Tree
以太坊的每一个区块头都包含了三棵MPT树:
- 交易树
- 收据树(交易执行过程中的一些数据)
- 状态树(账号信息, 合约账户和用户账户)
MPT树主要以下几个作用(核心):
- 可以存储任意长度的key-value键值对数据
- 提供了一种交易状态快速回滚的处理机制
- 提供了一种快速计算所维护数据集哈希标识的机制
- 提供了一种称为默克尔证明的证明方法,进行轻节点的扩展,实现简单支付验证(重中之重)
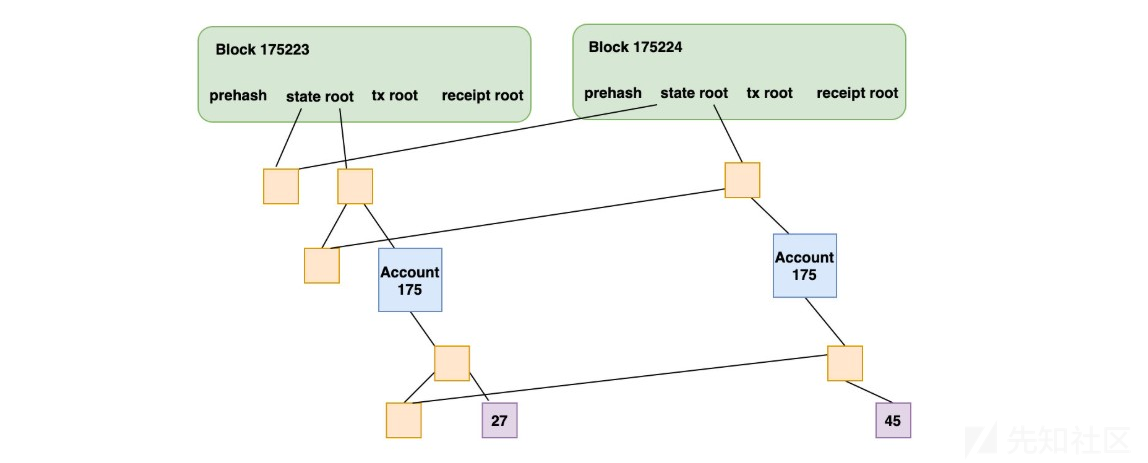
下图中的两个区块头中State root,Tx root、Receipt root分别存储了这三棵树的树根,第二个区块显示了当账号175的数据变更(27->45)的时候,只需要存储跟这个账号相关的部分数据即可,而且之前的区块中的数据还是可以正常访问:
prefix前缀:
- 0 - 扩展节点,偶数个半字节
- 1 - 扩展节点,奇数个半字节
- 2 - 叶子节点,偶数个半字节
- 3 - 叶子节点,奇数个半字节
Key-Value:
-----------------------------
key | value |
-----------------------------
a711355 | 45.0 ETH |
a77d337 | 1.00 WEI |
a7f9365 | 1.1 ETH |
a77d397 | 0.12 ETH |
-----------------------------
具体图示:
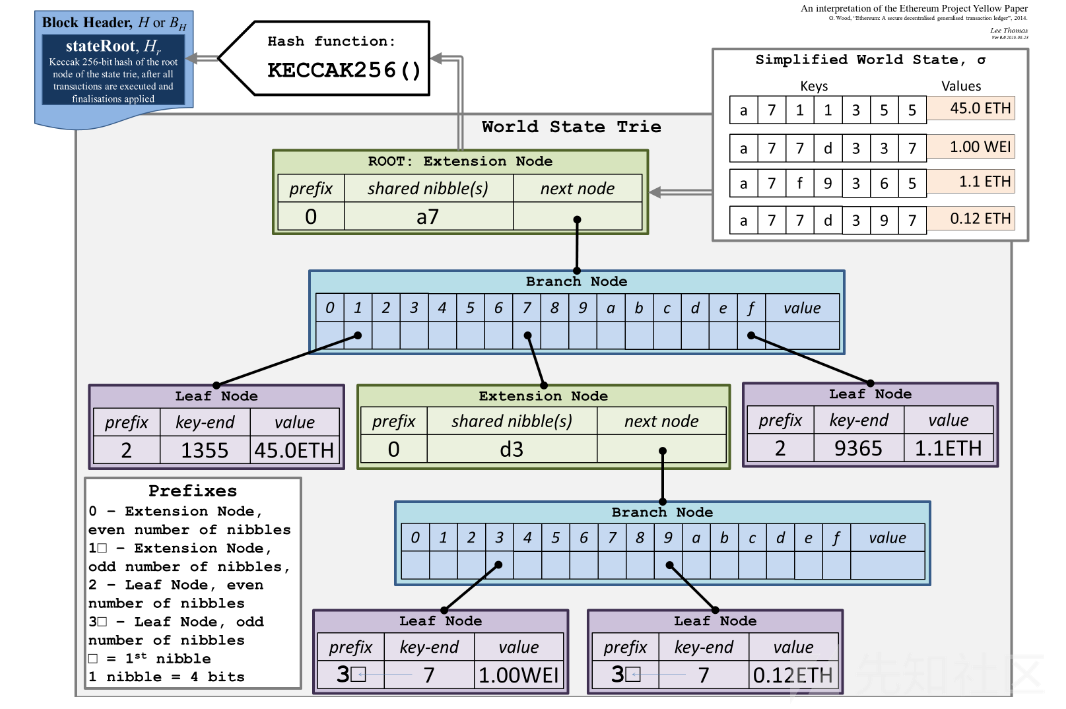
Trie树中有三种节点:
- 叶子节点(Leaf): 叶子节点包含两个字段, 第一个字段是剩下的Key的半字节编码, 第二个字段是Key对应的Value
- 扩展节点(Extention): 扩展节点也包含两个字段, 第一个字段是剩下的Key的半字节编码,第二个字段是n(J,j)
- 分支节点(Branch): 分支节点包含了17个字段,其前16个字段对应于这些节点在其遍历时键的十六个可能的半字节值中的每一个,第17个字段是存储那些在当前节点结束了的节点(例如:有三个key,分别是abc ,abd, ab,则第17个字段用于储存ab节点的值)
源码分析
Trie目录下的关键文件如下:
|-commiter.go 节点提交操作
|-database.go 内存中Trie的操作
|-encoding.go 编码转换
|-hasher.go 从某一节点开始计算子树的哈希
|-iterator.go 枚举相关的接口
|-node.go Trie树中所有结点类型和解析代码
|-sync.go 实现SyncTrie对象的定义和所有方法
|-secure_trie.go 实现SecureTrie对象
|-proof.go 为key构造一个merkle证明
|-trie.go Trie树的增删改查
数据结构
在研究树的构建、增删改查之前,我们先来看一下树的基本组成单位节点的类型,首先看一下之前的三种节点类型的定义:
- fullNode:对应分支节点,可以有多个子节点,它有一个容量为17的node数组成员变量Children,数组中前16个空位分别对应16进制(hex))下的0-9a-f,这样对于每个子节点,根据其key值16进制形式下的第一位的值,可挂载到Children数组的某个位置,fullNode本身不再需要额外key变量,Children数组的第17位,留给fullNode的数据部分,fullNode继承了原生trie的特点
- shortNode:对应扩展节点,只有一个子节点,成员Val指向一个子节点,成员Key是一个字节数组,shortNode通过合并只有一个子节点的父节点和其子节点来缩短trie的深度
- valueNode:对应叶子节点,没有子节点,它是承载MPT结构中真正数据部分的节点,在使用中valueNode就是所携带数据部分的RLP哈希值,长度32byte,数据的RLP编码值作为valueNode的匹配项存储在数据库里
- hashNode:hashNode是fullNode和shortNode对象的RLP哈希值,hashNode不会单独存在,而是以nodeFlag.hsah的形式存在,被fullNode和shortNode间接持有,一旦fullNode或shortNode的成员变量发生任何变化,nodeFlag.hsah就一定会更新
// filedir:go-ethereum-1.10.2\trie\node.go L34
type (
fullNode struct {
Children [17]node // Actual trie node data to encode/decode (needs custom encoder)
flags nodeFlag
}
shortNode struct {
Key []byte
Val node
flags nodeFlag
}
hashNode []byte
valueNode []byte
)
Trie的数据结构如下所示,其中root包含了当前的root节点,db是后端的KV存储,unhashed用于跟踪自上次哈希操作后插入的叶子数,该数字不会直接映射到实际unhashed的节点数:
// Trie is a Merkle Patricia Trie.
// The zero value is an empty trie with no database.
// Use New to create a trie that sits on top of a database.
//
// Trie is not safe for concurrent use.
type Trie struct {
db *Database
root node
// Keep track of the number leafs which have been inserted since the last
// hashing operation. This number will not directly map to the number of
// actually unhashed nodes
unhashed int
}
树的创建
New函数用于根据数据库中存在的root节点信息来创建一个树,在这里首先会检查db是否为空,之后检查root的hash是否为空,如果不为空则从数据库中加载一个已经存在的Trie树,如果为空则直接返回一个新的Trie:
// filedir:go-ethereum-1.10.2\trie\trie.go L62
// New creates a trie with an existing root node from db.
//
// If root is the zero hash or the sha3 hash of an empty string, the
// trie is initially empty and does not require a database. Otherwise,
// New will panic if db is nil and returns a MissingNodeError if root does
// not exist in the database. Accessing the trie loads nodes from db on demand.
func New(root common.Hash, db *Database) (*Trie, error) {
if db == nil {
panic("trie.New called without a database")
}
trie := &Trie{
db: db,
}
if root != (common.Hash{}) && root != emptyRoot {
rootnode, err := trie.resolveHash(root[:], nil)
if err != nil {
return nil, err
}
trie.root = rootnode
}
return trie, nil
}
resolveHash具体实现代码如下:
func (t *Trie) resolveHash(n hashNode, prefix []byte) (node, error) {
hash := common.BytesToHash(n)
if node := t.db.node(hash); node != nil {
return node, nil
}
return nil, &MissingNodeError{NodeHash: hash, Path: prefix}
}
树的检索
树的检索功能主要是根据传入的key值来查找Trie中对应的value,主要通过Get函数来实现:
// Get returns the value for key stored in the trie.
// The value bytes must not be modified by the caller.
func (t *Trie) Get(key []byte) []byte {
res, err := t.TryGet(key)
if err != nil {
log.Error(fmt.Sprintf("Unhandled trie error: %v", err))
}
return res
}
在合理可以看到又调用了TryGet方法,参数依旧为key(类型为byte数组),TryGet的具体实现如下所示,在这里又掉了了tryGet方法来检索key对应的value值,在这里需要注意的时此时传入tryGet的第一个参数是Trie的Root根,第二个参数有我们检索的依据——key通过keybytesToHex从bytes转十六进制所得,第三个参数为0
// TryGet returns the value for key stored in the trie.
// The value bytes must not be modified by the caller.
// If a node was not found in the database, a MissingNodeError is returned.
func (t *Trie) TryGet(key []byte) ([]byte, error) {
value, newroot, didResolve, err := t.tryGet(t.root, keybytesToHex(key), 0)
if err == nil && didResolve {
t.root = newroot
}
return value, err
}
tryGet函数的实现如下所示,从这里可以看到从上面传入的第三个参数即为pos,也就是我们的起始检索点,该函数有四个返回值:
- value:通过检索key所得的值
- newnode:node类型,新的检索node
- didResolve:布尔类型,是否有检索成功
- err:error类型,错误信息
func (t *Trie) tryGet(origNode node, key []byte, pos int) (value []byte, newnode node, didResolve bool, err error) {
switch n := (origNode).(type) {
case nil:
return nil, nil, false, nil
case valueNode:
return n, n, false, nil
case *shortNode:
if len(key)-pos < len(n.Key) || !bytes.Equal(n.Key, key[pos:pos+len(n.Key)]) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.tryGet(n.Val, key, pos+len(n.Key))
if err == nil && didResolve {
n = n.copy()
n.Val = newnode
}
return value, n, didResolve, err
case *fullNode:
value, newnode, didResolve, err = t.tryGet(n.Children[key[pos]], key, pos+1)
if err == nil && didResolve {
n = n.copy()
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
case hashNode:
child, err := t.resolveHash(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.tryGet(child, key, pos)
return value, newnode, true, err
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
}
在这里首先会检查当前检查的node的类型:
switch n := (origNode).(type) {
如果node类型为nil,则说明此时的Trie为一个空树,之后停止检索,检索失败:
case nil:
return nil, nil, false, nil
如果是叶子节点,则直接将叶子节点作为通过检索key所得的值,将node作为新的子树节点、检索结果为失败(这样做的原因是不更新newroot,即子树节点,因为叶子节点没有子节点,具体可以查看TryGet),错误为nil:
case valueNode:
return n, n, false, nil
如果检查节点为扩展节点,则首先会通过检查剩余未检查的key的长度是否小于当前检查节点的shared nibbles的长度,以及当前检查节点的shared nibbles的长度是否与key的未检测部分数值一致,如果满足以上一个条件则说明Trie中并没有要检索的key,否则继续递归调用TryGet向下进行检索:
case *shortNode:
if len(key)-pos < len(n.Key) || !bytes.Equal(n.Key, key[pos:pos+len(n.Key)]) {
// key not found in trie
return nil, n, false, nil
}
value, newnode, didResolve, err = t.tryGet(n.Val, key, pos+len(n.Key))
if err == nil && didResolve {
n = n.copy()
n.Val = newnode
}
return value, n, didResolve, err
如果此时的检查节点为一个分支节点,则通过增加pos的方式递归调用tryGet来检索children子节点中是否有对应的value:
case *fullNode:
value, newnode, didResolve, err = t.tryGet(n.Children[key[pos]], key, pos+1)
if err == nil && didResolve {
n = n.copy()
n.Children[key[pos]] = newnode
}
return value, n, didResolve, err
如果为hashNode则说明当前节点信息还未添加到内存中,所以需要先调用t.resolveHash(n, prefix)来加载节点到内存,之后调用tryGet进行检索:
case hashNode:
child, err := t.resolveHash(n, key[:pos])
if err != nil {
return nil, n, true, err
}
value, newnode, _, err := t.tryGet(child, key, pos)
return value, newnode, true, err
如果没有匹配到检查节点的类型则直接返回错误的节点类型
default:
panic(fmt.Sprintf("%T: invalid node: %v", origNode, origNode))
}
树的更新
树的更新通过Update函数来实现,在这里主要是更新key对应的value值,从下面的代码中可以看到这里又调用了TryUpdate函数:
// Update associates key with value in the trie. Subsequent calls to
// Get will return value. If value has length zero, any existing value
// is deleted from the trie and calls to Get will return nil.
//
// The value bytes must not be modified by the caller while they are
// stored in the trie.
func (t *Trie) Update(key, value []byte) {
if err := t.TryUpdate(key, value); err != nil {
log.Error(fmt.Sprintf("Unhandled trie error: %v", err))
}
}
TryUpdate函数如下所示,在这里首先将key通过keyBytesToHex从byte转为十六进制,之后检查value是否为0,如果为0则表示删除操作,调用delete函数进行删除,如果不为空则表示更新操作,调用insert函数进行更新:
// TryUpdate associates key with value in the trie. Subsequent calls to
// Get will return value. If value has length zero, any existing value
// is deleted from the trie and calls to Get will return nil.
//
// The value bytes must not be modified by the caller while they are
// stored in the trie.
//
// If a node was not found in the database, a MissingNodeError is returned.
func (t *Trie) TryUpdate(key, value []byte) error {
t.unhashed++
k := keybytesToHex(key)
if len(value) != 0 {
_, n, err := t.insert(t.root, nil, k, valueNode(value))
if err != nil {
return err
}
t.root = n
} else {
_, n, err := t.delete(t.root, nil, k)
if err != nil {
return err
}
t.root = n
}
return nil
}
在这里我们先来看树的更新操作,具体实现函数为insert,在上述代码中传入insert函数的有四个参数,我们可以对应下面的insert函数来了解其含义:
- n node:当前检查的节点
- prefix:已经处理完的部分key(PS:完整的key=key=prefix)
- key:未处理完的部分Key(PS:完整的key=key=prefix)
-
value:待更新的节点的value(node类型)
func (t *Trie) insert(n node, prefix, key []byte, value node) (bool, node, error) { if len(key) == 0 { if v, ok := n.(valueNode); ok { return !bytes.Equal(v, value.(valueNode)), value, nil } return true, value, nil } switch n := n.(type) { case *shortNode: matchlen := prefixLen(key, n.Key) // If the whole key matches, keep this short node as is // and only update the value. if matchlen == len(n.Key) { dirty, nn, err := t.insert(n.Val, append(prefix, key[:matchlen]...), key[matchlen:], value) if !dirty || err != nil { return false, n, err } return true, &shortNode{n.Key, nn, t.newFlag()}, nil } // Otherwise branch out at the index where they differ. branch := &fullNode{flags: t.newFlag()} var err error _, branch.Children[n.Key[matchlen]], err = t.insert(nil, append(prefix, n.Key[:matchlen+1]...), n.Key[matchlen+1:], n.Val) if err != nil { return false, nil, err } _, branch.Children[key[matchlen]], err = t.insert(nil, append(prefix, key[:matchlen+1]...), key[matchlen+1:], value) if err != nil { return false, nil, err } // Replace this shortNode with the branch if it occurs at index 0. if matchlen == 0 { return true, branch, nil } // Otherwise, replace it with a short node leading up to the branch. return true, &shortNode{key[:matchlen], branch, t.newFlag()}, nil case *fullNode: dirty, nn, err := t.insert(n.Children[key[0]], append(prefix, key[0]), key[1:], value) if !dirty || err != nil { return false, n, err } n = n.copy() n.flags = t.newFlag() n.Children[key[0]] = nn return true, n, nil case nil: return true, &shortNode{key, value, t.newFlag()}, nil case hashNode: // We've hit a part of the trie that isn't loaded yet. Load // the node and insert into it. This leaves all child nodes on // the path to the value in the trie. rn, err := t.resolveHash(n, prefix) if err != nil { return false, nil, err } dirty, nn, err := t.insert(rn, prefix, key, value) if !dirty || err != nil { return false, rn, err } return true, nn, nil default: panic(fmt.Sprintf("%T: invalid node: %v", n, n)) } }
在这里首先检索key的值是否为空(为空则表示我们已经检查key了),之后检查当前检查节点的value值是否不为空,且与要更新的value值一致,如果一致则不做更新,否则重设value值并返回:
if len(key) == 0 { if v, ok := n.(valueNode); ok { return !bytes.Equal(v, value.(valueNode)), value, nil } return true, value, nil }
之后检查当前检查节点的类型,如果节点类型为扩展节点则调用prefixLen来获取检索的key与当前检查节点具有的公共前缀的长度值,如果公共前缀的长度值等于当前检查节点的前缀值则将当前扩展节点的value设置为新的检查节点,然后更新已检查的前缀部分,以及已检查部分和要更新的value值,之后继续递归调用insert向下进行检查,如果公共前缀的长度值不等于当前检查节点的前缀值(表示没有key-value),之后在出现不同的地方创建一个分支节点,然后在分支节点的Children位置调用t.insert插入两个shortNode(其中一个存储当前扩展节点的value数据信息,另一个存储当前要检查数据的信息),之后进行匹配,当匹配长度为0时则用分支节点来替换扩展节点,否则将扩展节点作为插入后子树的根节点返回:
case *shortNode: matchlen := prefixLen(key, n.Key) // If the whole key matches, keep this short node as is // and only update the value. if matchlen == len(n.Key) { dirty, nn, err := t.insert(n.Val, append(prefix, key[:matchlen]...), key[matchlen:], value) if !dirty || err != nil { return false, n, err } return true, &shortNode{n.Key, nn, t.newFlag()}, nil } // Otherwise branch out at the index where they differ. branch := &fullNode{flags: t.newFlag()} var err error _, branch.Children[n.Key[matchlen]], err = t.insert(nil, append(prefix, n.Key[:matchlen+1]...), n.Key[matchlen+1:], n.Val) if err != nil { return false, nil, err } _, branch.Children[key[matchlen]], err = t.insert(nil, append(prefix, key[:matchlen+1]...), key[matchlen+1:], value) if err != nil { return false, nil, err } // Replace this shortNode with the branch if it occurs at index 0. if matchlen == 0 { return true, branch, nil } // Otherwise, replace it with a short node leading up to the branch. return true, &shortNode{key[:matchlen], branch, t.newFlag()}, nil
如果当前检查节点类型为分支节点,则从分支节点的第一个子节点开始递归检查,然后把更新后的子树根节点设置为对应的孩子节点
case *fullNode: dirty, nn, err := t.insert(n.Children[key[0]], append(prefix, key[0]), key[1:], value) if !dirty || err != nil { return false, n, err } n = n.copy() n.flags = t.newFlag() n.Children[key[0]] = nn return true, n, nil
如果节点类型是nil则说明树是空的,直接返回shortNode{key, value, t.newFlag()}, 这个时候整颗树的根就含有了一个shortNode节点
case nil: return true, &shortNode{key, value, t.newFlag()}, nil
如果当前节点是hashNode, 则表示当前节点还未添加到内存中,首先调用t.resolveHash(n, prefix)来加载到内存之后调用insert进行更新操作
case hashNode: // We've hit a part of the trie that isn't loaded yet. Load // the node and insert into it. This leaves all child nodes on // the path to the value in the trie. rn, err := t.resolveHash(n, prefix) if err != nil { return false, nil, err } dirty, nn, err := t.insert(rn, prefix, key, value) if !dirty || err != nil { return false, rn, err } return true, nn, nil
### 树的删除
下面我们紧接着来看树的删除操作,该操作主要通过delete来实现:// delete returns the new root of the trie with key deleted. // It reduces the trie to minimal form by simplifying // nodes on the way up after deleting recursively. func (t *Trie) delete(n node, prefix, key []byte) (bool, node, error) { switch n := n.(type) { case *shortNode: matchlen := prefixLen(key, n.Key) if matchlen < len(n.Key) { return false, n, nil // don't replace n on mismatch } if matchlen == len(key) { return true, nil, nil // remove n entirely for whole matches } // The key is longer than n.Key. Remove the remaining suffix // from the subtrie. Child can never be nil here since the // subtrie must contain at least two other values with keys // longer than n.Key. dirty, child, err := t.delete(n.Val, append(prefix, key[:len(n.Key)]...), key[len(n.Key):]) if !dirty || err != nil { return false, n, err } switch child := child.(type) { case *shortNode: // Deleting from the subtrie reduced it to another // short node. Merge the nodes to avoid creating a // shortNode{..., shortNode{...}}. Use concat (which // always creates a new slice) instead of append to // avoid modifying n.Key since it might be shared with // other nodes. return true, &shortNode{concat(n.Key, child.Key...), child.Val, t.newFlag()}, nil default: return true, &shortNode{n.Key, child, t.newFlag()}, nil } case *fullNode: dirty, nn, err := t.delete(n.Children[key[0]], append(prefix, key[0]), key[1:]) if !dirty || err != nil { return false, n, err } n = n.copy() n.flags = t.newFlag() n.Children[key[0]] = nn // Check how many non-nil entries are left after deleting and // reduce the full node to a short node if only one entry is // left. Since n must've contained at least two children // before deletion (otherwise it would not be a full node) n // can never be reduced to nil. // // When the loop is done, pos contains the index of the single // value that is left in n or -2 if n contains at least two // values. pos := -1 for i, cld := range &n.Children { if cld != nil { if pos == -1 { pos = i } else { pos = -2 break } } } if pos >= 0 { if pos != 16 { // If the remaining entry is a short node, it replaces // n and its key gets the missing nibble tacked to the // front. This avoids creating an invalid // shortNode{..., shortNode{...}}. Since the entry // might not be loaded yet, resolve it just for this // check. cnode, err := t.resolve(n.Children[pos], prefix) if err != nil { return false, nil, err } if cnode, ok := cnode.(*shortNode); ok { k := append([]byte{byte(pos)}, cnode.Key...) return true, &shortNode{k, cnode.Val, t.newFlag()}, nil } } // Otherwise, n is replaced by a one-nibble short node // containing the child. return true, &shortNode{[]byte{byte(pos)}, n.Children[pos], t.newFlag()}, nil } // n still contains at least two values and cannot be reduced. return true, n, nil case valueNode: return true, nil, nil case nil: return false, nil, nil case hashNode: // We've hit a part of the trie that isn't loaded yet. Load // the node and delete from it. This leaves all child nodes on // the path to the value in the trie. rn, err := t.resolveHash(n, prefix) if err != nil { return false, nil, err } dirty, nn, err := t.delete(rn, prefix, key) if !dirty || err != nil { return false, rn, err } return true, nn, nil default: panic(fmt.Sprintf("%T: invalid node: %v (%v)", n, n, key)) } }
在这里首先检查当前检查节点的类型,如果节点类型为shortNode,则首先检查公共前缀,如果公共前缀的长度小于节点的前缀,则节点删除失败(不存在),如果共同的前缀等于key的长度,则删除匹配的整个节点,如果key比node.key还要长,则将扩展节点的子节点作为新的检查点并更新已检查的前缀信息,之后递归调用delete向下进行检索,之后检查子节点的节点类型,如果子节点的节点类型也为扩展节点则通过调用concat将检查节点的key与当前子节点的key相连接作为新的key,之后将子树的节点作为新的子节点,实例化一个ShortNode返回(即间接性的删除当前的检查节点),否则直接返回一个shortNode,需要注意的是这里返回的扩展节点的为子节点child实例化后的哦~
case *shortNode: matchlen := prefixLen(key, n.Key) if matchlen < len(n.Key) { return false, n, nil // don't replace n on mismatch } if matchlen == len(key) { return true, nil, nil // remove n entirely for whole matches } // The key is longer than n.Key. Remove the remaining suffix // from the subtrie. Child can never be nil here since the // subtrie must contain at least two other values with keys // longer than n.Key. dirty, child, err := t.delete(n.Val, append(prefix, key[:len(n.Key)]...), key[len(n.Key):]) if !dirty || err != nil { return false, n, err } switch child := child.(type) { case *shortNode: // Deleting from the subtrie reduced it to another // short node. Merge the nodes to avoid creating a // shortNode{..., shortNode{...}}. Use concat (which // always creates a new slice) instead of append to // avoid modifying n.Key since it might be shared with // other nodes. return true, &shortNode{concat(n.Key, child.Key...), child.Val, t.newFlag()}, nil default: return true, &shortNode{n.Key, child, t.newFlag()}, nil }
如果是fullNode(分支节点),则从下标为0的第一个children开始递归调用delete向下进行检索,待检索到后更新pos,然后通过一个for循环来检索删除操作之后有多少非空的子树,假设此时的pos为0,则pos:=-1的结果为pos=-1,如果当前分支节点只有一个子节点,那么此时的pos将被置为0,所以减一操作后为-1,之后pos变更为0,此时如果有另一个子树则还需要再进入到for中一次,此时pos被置为-2,之后通过break跳出循环,此时如果满足pos>=0,可见如果此时子树多余两个则pos的值将为-2(无论最初pos为多少),之后判断pos是否大于0,如果大于0则判断pos是否等于16(即非分支节点的value部分),如果不为16则调用resolve加载其子树,用子节点的子节点来替换当前子节点,之后更新key并返回一个shortNode(扩展节点),否则返回一个使用检查节点的第十六位即value字段的值初始化后的一个shortNode,如果pos<0,则说明依旧至少包含两个不可被缩减的子节点,则直接返回一个shortNode:
case *fullNode:
dirty, nn, err := t.delete(n.Children[key[0]], append(prefix, key[0]), key[1:])
if !dirty || err != nil {
return false, n, err
}
n = n.copy()
n.flags = t.newFlag()
n.Children[key[0]] = nn
// Check how many non-nil entries are left after deleting and
// reduce the full node to a short node if only one entry is
// left. Since n must've contained at least two children
// before deletion (otherwise it would not be a full node) n
// can never be reduced to nil.
//
// When the loop is done, pos contains the index of the single
// value that is left in n or -2 if n contains at least two
// values.
pos := -1
for i, cld := range &n.Children {
if cld != nil {
if pos == -1 {
pos = i
} else {
pos = -2
break
}
}
}
if pos >= 0 {
if pos != 16 {
// If the remaining entry is a short node, it replaces
// n and its key gets the missing nibble tacked to the
// front. This avoids creating an invalid
// shortNode{..., shortNode{...}}. Since the entry
// might not be loaded yet, resolve it just for this
// check.
cnode, err := t.resolve(n.Children[pos], prefix)
if err != nil {
return false, nil, err
}
if cnode, ok := cnode.(*shortNode); ok {
k := append([]byte{byte(pos)}, cnode.Key...)
return true, &shortNode{k, cnode.Val, t.newFlag()}, nil
}
}
// Otherwise, n is replaced by a one-nibble short node
// containing the child.
return true, &shortNode{[]byte{byte(pos)}, n.Children[pos], t.newFlag()}, nil
}
// n still contains at least two values and cannot be reduced.
return true, n, nil
如果节点为valueNode(叶子结点(没有子节点))类型则直接返回成功:
case valueNode:
return true, nil, nil
如果节点为nil类型,则说明整颗树都是空的,直接返回失败:
case nil:
return false, nil, nil
如果类型为hashNode,hashNode的意思是当前节点还没有加载到内存里面来,则调用resolveHash加载节点,之后递归调用delete进行删除操作:
case hashNode:
// We've hit a part of the trie that isn't loaded yet. Load
// the node and delete from it. This leaves all child nodes on
// the path to the value in the trie.
rn, err := t.resolveHash(n, prefix)
if err != nil {
return false, nil, err
}
dirty, nn, err := t.delete(rn, prefix, key)
if !dirty || err != nil {
return false, rn, err
}
return true, nn, nil
如果类型不匹配则直接抛出错误节点:
default:
panic(fmt.Sprintf("%T: invalid node: %v (%v)", n, n, key))
}
PS:篇幅有点长,一篇放不下,下篇再续,
 转载
转载
 分享
分享

