
在2022年的第五空间决赛中出现了一道关于多媒体安全的题目,其中给出了一张如下图所示的由三原色像素组长的图片,需要我们进行解密获取Flag。题目已经放入附件中

经过资料查询发现一篇论文与本CTF题目相似
《A color image encryption technique using exclusive-OR with DNA complementary rules based on chaos theory and SHA-2》
中文翻译过来是:基于混沌理论和SHA-2的异或与DNA互补规则的彩色图像加密技术
本篇论文有三个突出的特点
1.打破彩色图像通道的相关性
2.提出了一种新的像素级混淆机制
3.提出了一种新的像素级混淆机制
前置知识补充
首先论文的名字中可以看出其中由多种加密方式共同组成因此先理解各种加密方式的原理
混沌算法
基于混沌理论,这篇论文打破彩色图像通道的相关性,提出了一种新的像素级混淆机制
混沌映射是生成混沌序列的一种方法,混沌映射可以用于替代伪随机数生成器,生成 0 到 1 之间的混沌数。常见的混沌映射方式有 Logistic映射、Tent映射、Circle映射,而 Piecewise映射作为混沌映射的典型代表,数学形式简单,具有遍历性和随机性
本文主要使用三种混沌算法: PWLCM序列排序、Chen模型、Lorenz模型
混沌系统:Piecewise混沌映射/PWLCM混沌映射
这种算法为分段线性混沌映射:主要根据上一个数值,分段计算下一个值
公式如下:
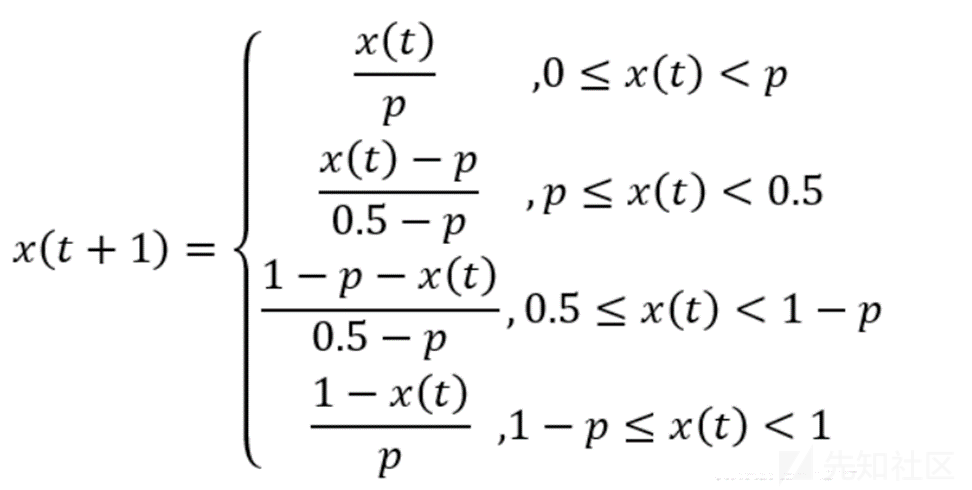
for i in range(3*w*h):
if 0 <= a0 < p0:
a0 = a0/p0
elif a0 < 0.5:
a0 = (a0-p0)*(0.5-p0)
else:
a0 = 1-a0
ai.append(a0)
混沌系统:Lorenz’s system
劳伦兹混沌系统
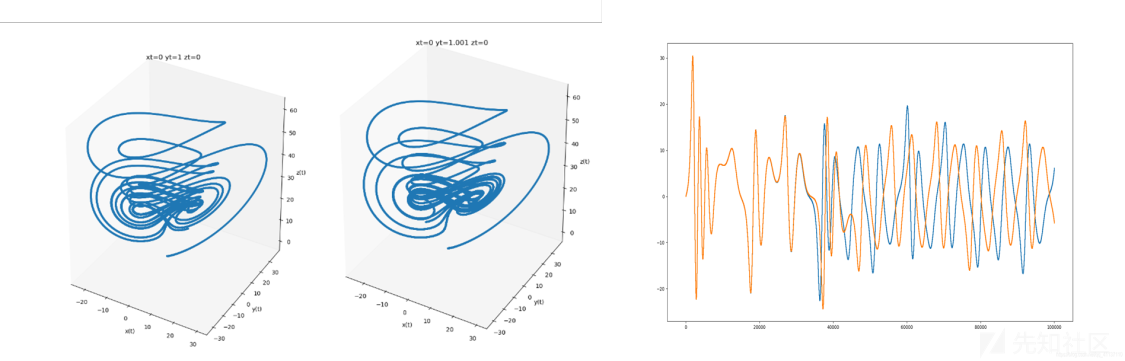
它是由美国气象学家Lorenz在研究大气运动的时候,通过对对流模型简化,只保留三个变量提出的一个完全确定性的三阶自治常微分方程组。其中,三个参数分别为:σ 为普朗特数,ρ 是瑞利数,β 是方向比。在 σ = 10 , ρ = 28 , β = 8 / 3时系统进入混沌
公式如下:
def Lorenz(x0, y0, z0, p, q, r, T):
# 微分迭代步长
h = 0.01
x = []
y = []
z = []
for t in range(T):
xt = x0+h*p*(y0-x0)
yt = y0+h*(q*x0-y0-x0*z0)
zt = z0+h*(x0*y0-r*z0)
# x0、y0、z0统一更新
x0, y0, z0 = xt, yt, zt
x.append(x0)
y.append(y0)
z.append(z0)
return x, y, z
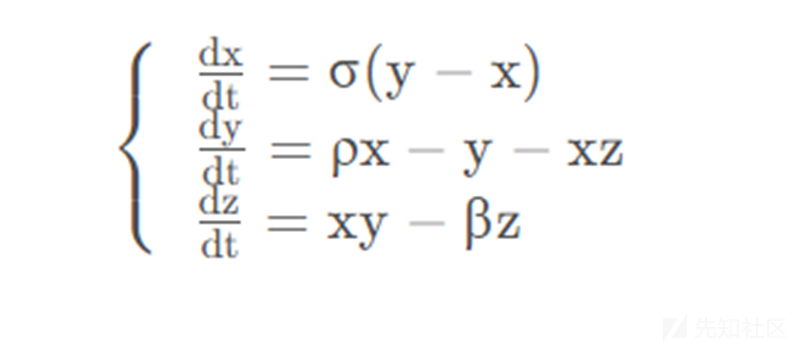
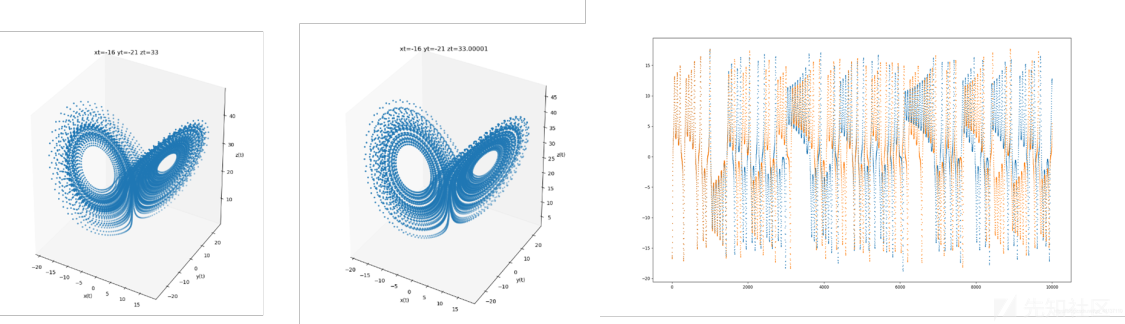
可以看到原本靠得很近的轨道迅速地分开,最后两条轨道变得毫无关联,这正是动力学系统对初值敏感性的直观表现,因此我们说此系统的这种状态为混沌态
混沌系统:Chen’s hyper-chaotic system
陈氏混沌系统
a, b, c,为系统参数,当a=35,b=3,c=28时,陈氏超混沌系统处于混沌状态,可以产生4个混沌序列

代码复现
def Chen(u0, v0, w0, x0, a, b, c, d, k, T):
h = 0.001
u = []
v = []
w = []
x = []
for t in range(T):
ut = u0+h*(a*(v0-u0))
vt = v0+h*(-u0*w0+d*u0+c*u0-x0)
wt = w0+h*(u0*v0-b*w0)
xt = u0+k
# u0、v0、w0,x0统一更新
u0, v0, w0, x0 = ut, vt, wt, xt
u.append(u0)
v.append(v0)
w.append(w0)
x.append(x0)
return u, v, w, x
结果如下
DNA编码
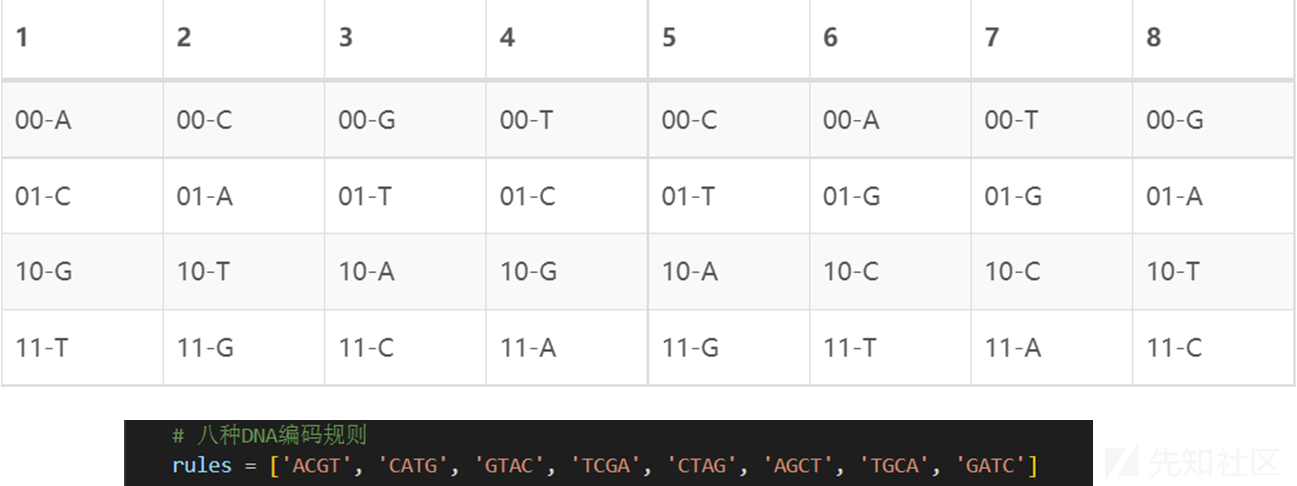
•DNA有A、C、G、T
根据互补规则,每一对DNA碱基必须是互补的,就像A和T是互补的,C和G是互补的。二进制数字系统只由两个数字组成;0和1相互对立或互补。同理,00和11是互补的,01和10也是互补的。
•DNA转化规则共有24种,但只有8种符合所示的Watson-Crick互补规则
我们通过一个例子进行解释
•一幅数字图像的像素强度在0到255之间,所以将8位像素强度值表示到DNA域只需要4个DNA碱基。例如,如果像素强度值为93,则其二进制值为“01 01 11 01”,93的DNA转化值取决于DNA编码规则的选择,如果采用DNA编码规则8,它将成为“AACA”。利用相同的DNA规则8将“AACA”转换为数字格式,得到相同的强度值93。但如果我们选择另一条DNA规则解码,如规则1,那么“AACA”将是‘00 00 01 00’,像素的强度值将是2。这是DNA编码/解码方法。
DNA碱基XOR运算
首先给出表格,此时可能看着还不能理解

我们不要把它看为字母直接换成数字,A-00,G-01,C-10,T-11

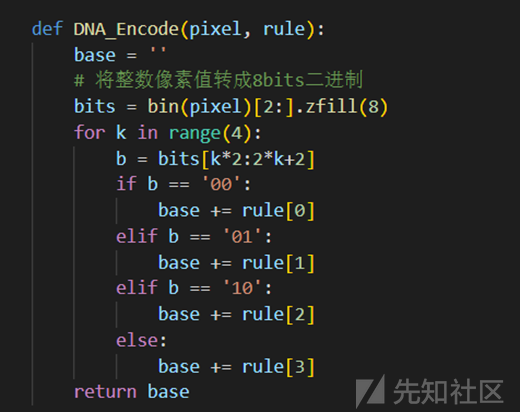
编码
对于编码,提取一个像素值点,转换为8位的二进制分成四组
如果此时对于DNA编码rule为TCGA,像素值为155(10011011)
10->G,01->C,10->G,11->A
经过编码后得到的值为GCGA
解码
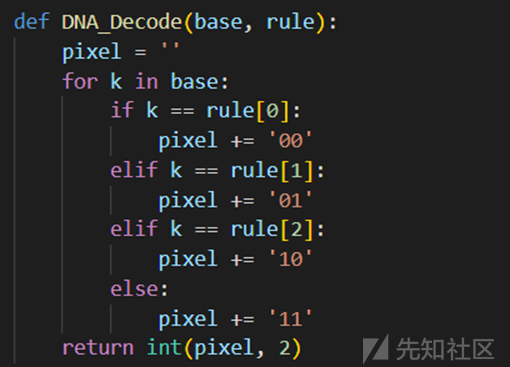
同理对于解码,通过X混沌序列获得编码规则后,进行解析,例子用上述的
GCGA对于编码规则为TCGA
G->10,C->01,G->10,A->11
得解码后的值为10011011->155
def DNA_Encode(pixel, rule):
base = ''
# 将整数像素值转成8bits二进制
bits = bin(pixel)[2:].zfill(8)
for k in range(4):
b = bits[k*2:2*k+2]
if b == '00':
base += rule[0]
elif b == '01':
base += rule[1]
elif b == '10':
base += rule[2]
else:
base += rule[3]
return base
def DNA_Decode(base, rule):
pixel = ''
for k in base:
if k == rule[0]:
pixel += '00'
elif k == rule[1]:
pixel += '01'
elif k == rule[2]:
pixel += '10'
else:
pixel += '11'
return int(pixel, 2)
def DNA_XOR(base1, base2):
# 转成整数进行异或
pixel = DNA_Decode(base1, 'AGCT') ^ DNA_Decode(base2, 'AGCT')
return DNA_Encode(pixel, 'AGCT')
论文复现
加密
首先对于加密的流程进行分析
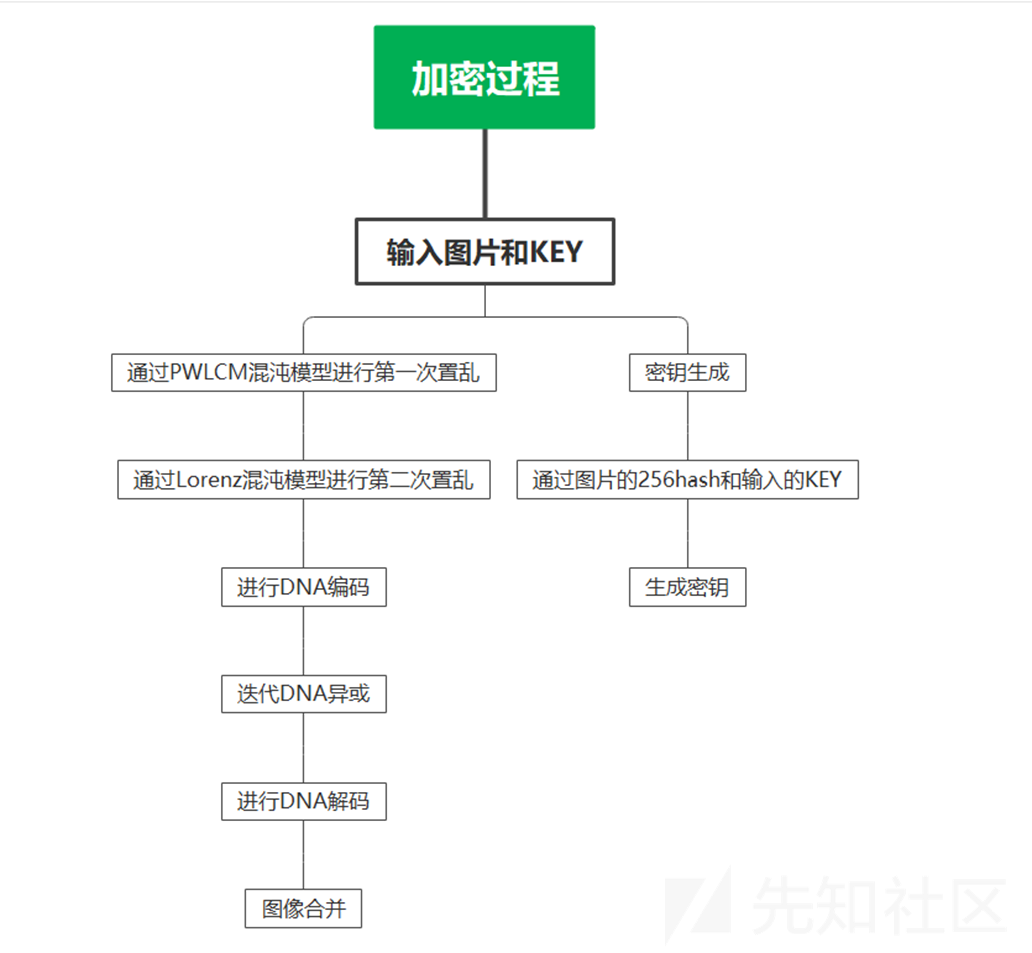
密钥
密钥由以下公式生成

SHA-256生成256位的摘要,而不管输入的大小。如果两个输入之间有一个比特的差异,它们的消息摘要将完全不同。因此,这可以用来生成要加密的彩色图像的摘要,然后消息摘要分为两组十六进制值。第一组分为大小相同的8块,其值分别为 m_j,j=1,2....,8。;
每个块包含7个十六进制数字,通过公式将其转换为浮点小数m_j 属于(0,0.0156)
注意:我们输入的密钥并不是最终密钥,密钥主要用于混沌算法的参数
def Generate_Key(img, key):
im = cv2.imread(img)[:, :, (2, 1, 0)]
# 获取图像高宽和通道数
[h, w, dim] = im.shape
with open(img, 'rb') as f:
bytes = f.read()
img_hash = hashlib.sha256(bytes).hexdigest()
m = []
# hash共256位,第一部分占224位
for i in range(8):
m.append(int(img_hash[i*7:i*7+7], 16)/2**34)
# 因此这里我们的第二部分密钥可以直接取后八位十六进制即32位
d = int(img_hash[-8:], 16)/2**38
# print(m)
# print(d)
ck = 0
for i in range(len(key)):
ck += key[i]
# 生成初始条件
for i in range(8):
key[i] = (key[i]+m[i]+ck) % 1
key[8] = (key[8]+d+ck) % 1
return key

第一次置乱
本文提出的彩色图像的置乱方法分两次进行
第一次是采用PWLCM迭代3MN次得到的混沌序列A,将图像I的所有三个通道合并成一个13MN大小的一维数组,然后根据混沌序列A进行排序。
1)先提取图片的RGB通道
2)图像扁平化为一维
3)第一次置乱,PWLCM迭代3w*h次,得到迭代序列ai
4)根据ai排序,得到排序后的像素列表
5)分成R、G、B三个通道.此时知识名称叫R、G、B ,划分的依据为1-wh,wh-2wh,2wh-3wh
# 第一次置乱
# PWLCM迭代3*w*h次,得到迭代序列ai
ai = []
for i in range(3*w*h):
if 0 <= a0 < p0:
a0 = a0/p0
elif a0 < 0.5:
a0 = (a0-p0)*(0.5-p0)
else:
a0 = 1-a0
ai.append(a0)
# 打包
dic = list(zip(ai, pixels))
# 根据ai排序
dic.sort(key=lambda x: x[0])
# 得到排序后的像素列表
pixels = list(list(zip(*dic))[1])
# 分成R、G、B三个通道
R = pixels[:w*h]
G = pixels[w*h:2*w*h]
B = pixels[2*w*h:]
第二次置乱
•在第一次置乱的基础上
•对于R、G、B三个分组根据Lorenz系统生成大小为t+WH的三个伪随机序列Y、Z、Q去混淆三个通道的像素。
# 第二次置乱
# Lorenz生成三个序列Y,Z,Q
t = 100
f = 10
r = 28
g = 8/3
# 调用Lorenz模型函数
Y, Z, Q = Lorenz(y0, z0, q0, f, r, g, t+w*h)
# 丢弃序列前t个值
Y = Y[t:]
Z = Z[t:]
Q = Q[t:]
# 分别在R、G、B三个通道进行排序
Y_R = list(zip(Y, R))
# 根据序列Y排序
Y_R.sort(key=lambda x: x[0])
# 得到排序后的像素列表
R = list(list(zip(*Y_R))[1])
Z_G = list(zip(Z, G))
# 根据序列Z排序
Z_G.sort(key=lambda x: x[0])
# 得到排序后的像素列表
G = list(list(zip(*Z_G))[1])
Q_B = list(zip(Q, B))
# 根据序列Q排序
Q_B.sort(key=lambda x: x[0])
# 得到排序后的像素列表
B = list(list(zip(*Q_B))[1])
# 得到重新排列后的R、G、B颜色分量
混淆/扩散
对于第二次置乱后的R、G、B通道
1)对于各个通过循环WH次
2)通过CHEN混沌系统,产生的U,V,W,X
3)U伪随机混沌序列分为三组,每一组对应R、G、B
用于选择DNA编码规则
4)V,W伪随机混沌序列用于产生编码对应的起始位置和迭代的次数
5)X伪随机混沌序列用于选择解码规则
假设红通道的一个像素由DNA碱基{A, C, T, T}组成,start_R={4},times_R={6},则{A, C, T,T}将与规则GTAC异或,然后是ACGT, TCGA, CATG, AGCT和GATC

DNA编码
在前置知识中我们讲解了DNA编码的原理,现在我们需要进行代码的实现
# DNA编码
# Hyper Chaos Chen系统控制参数
a = 36
b = 3
c = 28
d = 16
k = 0.2
t = 100
U, V, W, X = Chen(u0, v0, w0, x0, a, b, c, d, k, t+3*w*h)
# U适用于选择编码规则
U = U[t:]
# 用于选择start_R
V = V[t:]
# 用于选择迭代次数
W = W[t:]
#
X = X[t:]
for i in range(3*w*h):
rule = 'ACGT'
if(int(U[i] % 1/0.05) in [0, 4, 8, 10, 19]):
# 采用 AGCT
rule = 'AGCT'
elif(int(U[i] % 1/0.05) in [1, 6, 12, 14, 17]):
# 编码规则ACGT
rule = 'ACGT'
elif(int(U[i] % 1/0.05) in [2, 7, 11, 13, 16]):
rule = 'GATC'
elif(int(U[i] % 1/0.05) in [3, 5, 9, 15, 18]):
rule = 'CATG'
if(i/(w*h) < 1):
R[i] = DNA_Encode(R[i], rule)
elif(i/(w*h) < 2):
G[i-w*h] = DNA_Encode(G[i-w*h], rule)
else:
B[i-2*w*h] = DNA_Encode(B[i-2*w*h], rule)
start = []
times = []
for i in V:
start.append(int(i*pow(10, 12)) % 8)
for i in W:
times.append(int(i*pow(10, 12)) % 8)
startR = start[:w*h]
startG = start[w*h:2*w*h]
startB = start[2*w*h:]
timesR = times[:w*h]
timesG = times[w*h:2*w*h]
timesB = times[2*w*h:]
DNA迭代异或
# 八种DNA编码规则
rules = ['ACGT', 'CATG', 'GTAC', 'TCGA', 'CTAG', 'AGCT', 'TGCA', 'GATC']
for i in range(w*h):
# 起始规则位置
s = startR[i]
for j in range(timesR[i]):
R[i] = DNA_XOR(R[i], rules[s])
s = (s+1) % 8
for i in range(w*h):
# 起始规则位置
s = startG[i]
for j in range(timesG[i]):
G[i] = DNA_XOR(G[i], rules[s])
s = (s+1) % 8
for i in range(w*h):
# 起始规则位置
s = startB[i]
for j in range(timesB[i]):
B[i] = DNA_XOR(B[i], rules[s])
s = (s+1) % 8
DNA解码
# DNA解码
for i in range(3*w*h):
rule = 'ACGT'
if(int(X[i] % 1/0.05) in [0, 4, 8, 10, 19]):
# 采用解码规则GTAC
rule = 'GTAC'
elif(int(X[i] % 1/0.05) in [1, 6, 12, 14, 17]):
# 解码规则TGCA
rule = 'TGCA'
elif(int(X[i] % 1/0.05) in [2, 7, 11, 13, 16]):
rule = 'CTAG'
elif(int(X[i] % 1/0.05) in [3, 5, 9, 15, 18]):
rule = 'TCGA'
if(i/(w*h) < 1):
R[i] = DNA_Decode(R[i], rule)
elif(i/(w*h) < 2):
G[i-w*h] = DNA_Decode(G[i-w*h], rule)
else:
B[i-2*w*h] = DNA_Decode(B[i-2*w*h], rule)
# 合并R、G、B三个通道得到加密彩色图像
encrypt_img = np.array((R+G+B)).reshape((512, 512, 3), order='C')
return encrypt_img
最后结合三个解码通道得到加密彩色图像;

解密
图像解密步骤,通过加密过程来逆向分析
1)先读取加密图片,通过密钥获得的CHEN混沌模型,获得迭代次数和编码规则
2)获得的三组数据在进行混沌算法的排序(两次置乱)
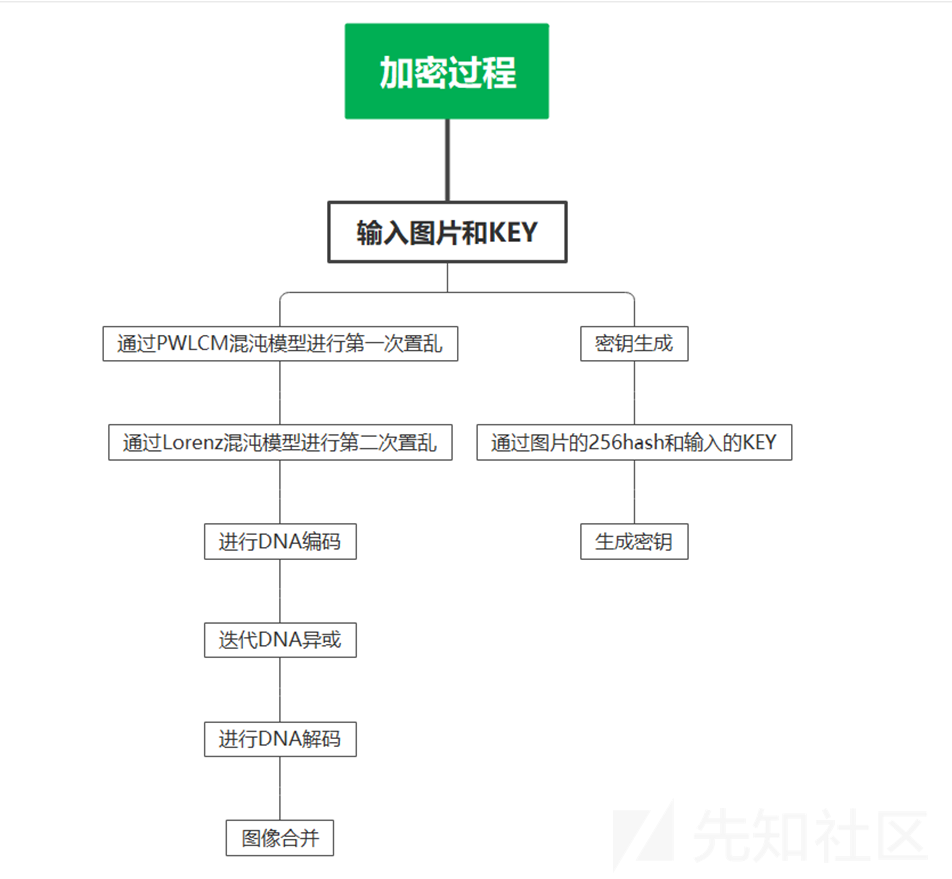
解码
1)先读取加密图片,通过密钥获得的CHEN混沌模型,获得迭代次数和编码规则
对于编码规则的逆向迭代
第一次迭代的rules = (startR[i]+timesR[i]-1) % 8
接下来每次迭代rules = rules-1 % 8
2)获得的三组数据在进行混沌算法的排序(两次置乱)

逆运算
密码学的安全性,密钥安全而非密码安全
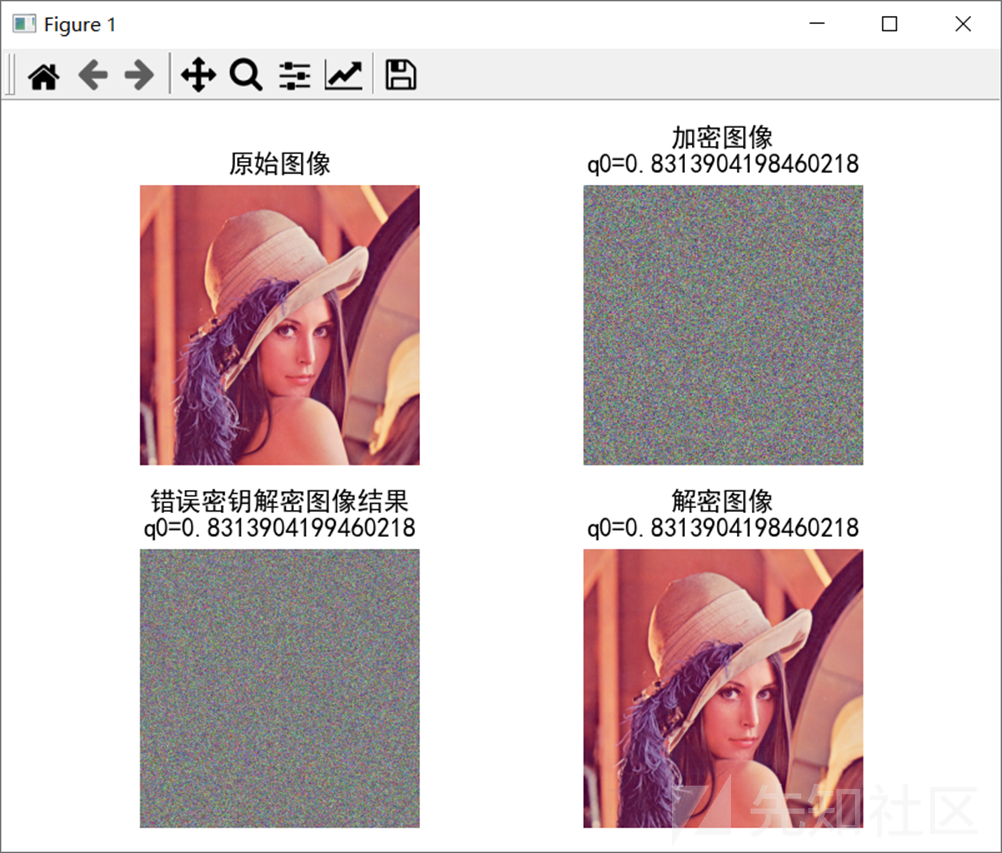
最后结果


 转载
转载
 分享
分享
