
前言
论文名称:A comprehensive survey and taxonomy of the SVM-based intrusion detection systems
Abstract
对本文框架做了简要介绍,下面是文章主要结构:
- 首先介绍背景知识,包括什么是安全攻击、IDS和SVM的基本概念
- 其次介绍了svm-based ids的分类情况,包括每个类别的特点和优势
- 再次对上述的各种IDS做数据统计,给出一些统计图表
- 最后给出未来研究期望和总结
Introduction
开篇介绍三种类别的IDS:
-
基于异常检测的IDS:将正常行为之外的流量都归为异常流量(类似白名单)
- 优点:可以检测到新的攻击流量
- 缺点:非正常行为都归为攻击,误报率高,另外在一个较大的组织中,很难收集全所有的正常流量
-
基于误用检测的IDS:又叫基于签名的IDS,本质是集成一个攻击流量的特征库(类似黑名单)
- 优点:检测准确度高,特征库都基于已有攻击,一旦检测到基本可以认定为攻击
- 缺点:特征库的搭建和维护成本过高,另外无法应对流量加密的技术
- 混合检测的IDS:折中,吸取上面两种方法的优点,避免其缺点
提出本文的目标:对 SVM IDS 进行分类和研究,主要包括下面的步骤:
- 介绍IDS、SVM的基础知识
- 基于SVM classifier的类型和其他技术,对SVM IDS进行分类
- 针对每一类的研究方案,讨论其优势、劣势等等
- 最后对各类SVM IDS进行比较,突出它们的各种特征,以及未来可能的研究领域。
Research methodology
这一小节讲的是这篇综述的研究方法,详细讲了一下怎么搜索并找到SVM-based IDS的论文。
给出了检索论文的所用关键字、以及选择的论文期刊的范围
最后统计了一下每年 svm-based ids相关论文发表的数量
Research background
主要介绍IDS和SVM的基本概念,简单了解即可。
IDS
IDS分类
首先,根据IDS的机器学习方法,把IDS分类成监督学习、非监督学习、半监督学习三类:
- 监督学习:采用分类算法,检测的准确率高,但是要求数据集打全标签,实操起来有困难
- 无监督学习:用的聚类算法,不用给数据集打标签,但是误报率比较高
- 半监督:折中说,未标记的数据和带标记的数据结合使用
特征选择方法
其次,介绍了特征选择/特征提取的三种方法:过滤法、包装法、嵌入法
补充知识:特征选择(过滤法、包装法、嵌入法)_过滤法特征选择-CSDN博客
三种特征选择方法的简要概括:
- Filter:按照分散性/相关性对各个特征进行评分,设定评分标准(阈值)或者个数,来选择特征
- Wrapper:根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征
- Embedded:先不特征选择进行训练,得到各个特征的权值系数,根据系数从大到小选择特征(类似于Filter方法,但是是通过训练来确定特征的优劣)
Filter方法
1、方差选择法:先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。代码如下:
from scipy.stats import pearsonr
from sklearn.feature_selection import VarianceThreshold, SelectKBest
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# 1. 方差选择法
selector = VarianceThreshold(threshold=3)
selected_features = selector.fit_transform(iris.data)
print(pd.DataFrame(selected_features, columns=np.array(iris.feature_names)[selector.get_support(indices=True)]))
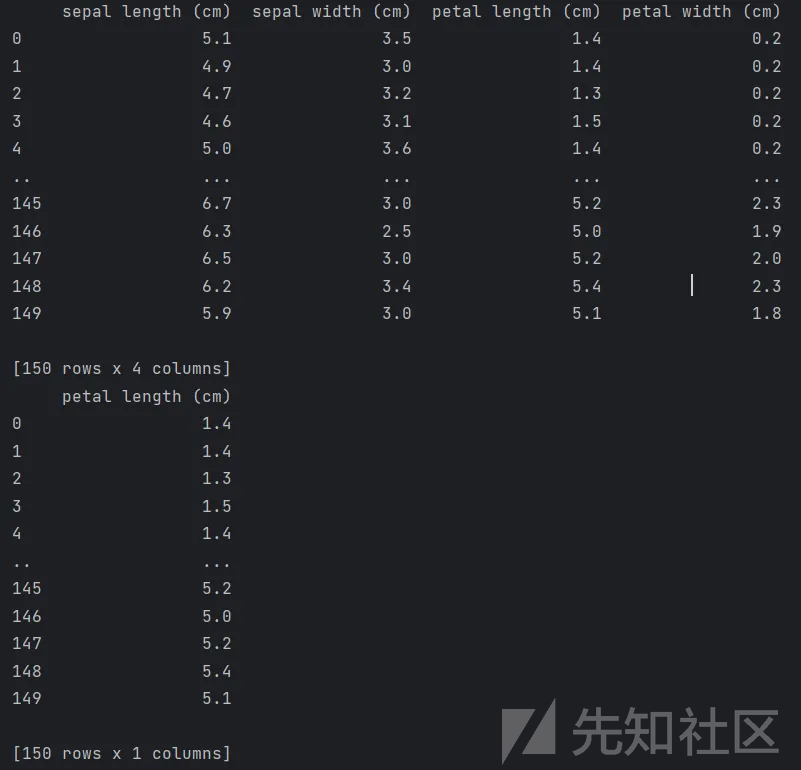
2、 相关系数法:先要计算各个特征x对目标值Y的相关系数,选择相关系数高的特征。代码如下:
from scipy.stats import pearsonr
from sklearn.feature_selection import VarianceThreshold, SelectKBest
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# 2. 相关系数法
selector = SelectKBest(lambda X, Y: np.array(list(map(lambda x: pearsonr(x, Y)[0], X.T))).T, k=2)
selected_features = selector.fit_transform(iris.data, iris.target)
print(pd.DataFrame(selected_features, columns=np.array(iris.feature_names)[selector.get_support(indices=True)]))
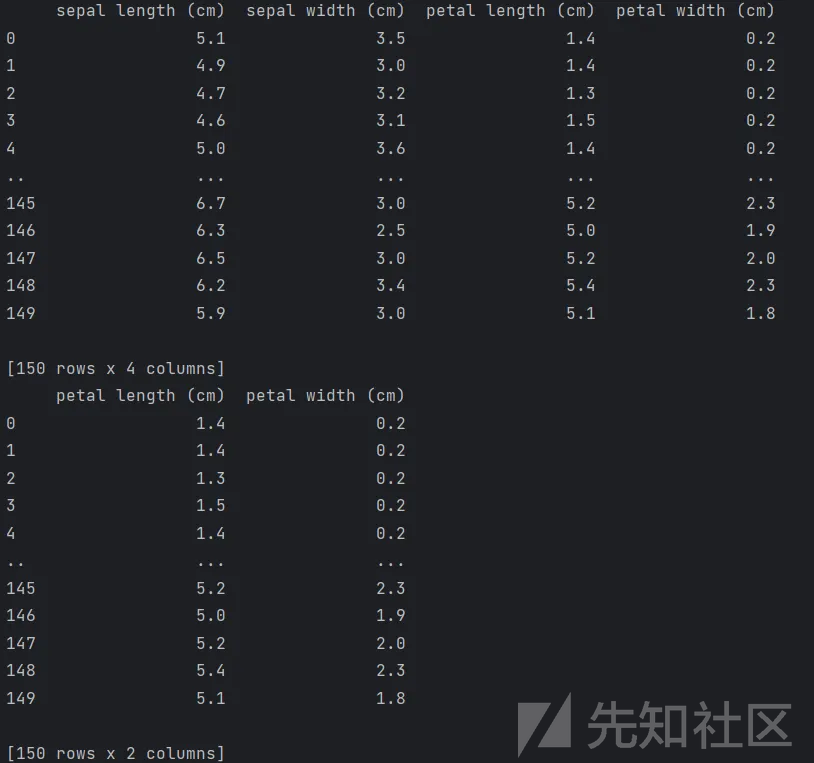
其余像是卡方选择法、MIC法就不再赘述,sklearn都集成函数,可直接使用。
Wrapper方法
递归特征消除法(RFE):顾名思义,通过反复地构建模型(如SVM或者回归模型),每次选出一个最差或最好的特征(通过相关系数等),然后利用其余特征重复构建、选择过程,直到遍历完所有特征。代码如下:
from sklearn.datasets import load_iris
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
import numpy as np
import pandas as pd
# 导入鸢尾花数据集
iris = load_iris()
print(pd.DataFrame(iris.data, columns=iris.feature_names))
# estimator是评估特征用的模型,n_features_to_select是选取特征的个数
selector = RFE(estimator=LogisticRegression(max_iter=1000), n_features_to_select=2)
selected_features = selector.fit_transform(iris.data, iris.target)
print(pd.DataFrame(selected_features, columns=np.array(iris.feature_names)[selector.get_support(indices=True)]))
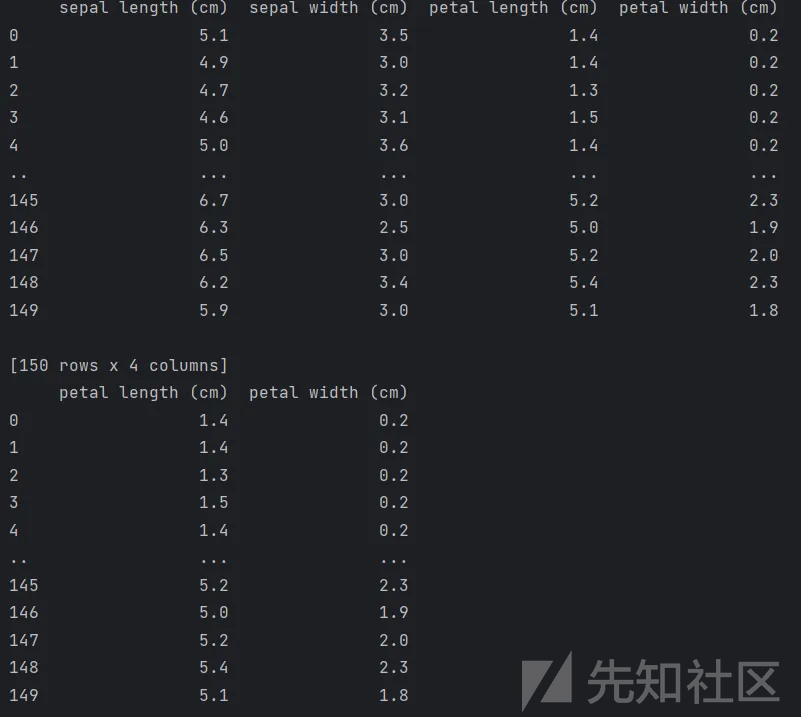
Embedded方法
嵌入特征选择方法和算法本身紧密结合,在模型训练过程中完成特征选择。例如:
- 决策树算法每次都选择分类能力最强的特征;
- 线性回归+L2正则化:某些信号比较弱的特征权重减小;
- 线性回归+L1正则化:某些信号比较弱的特征权重为0;
1、基于带L1惩罚项的逻辑回归模型
L1正则方法具有稀疏解的特性,因此天然具备特征选择的特性。
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# 导入鸢尾花数据集
iris = load_iris()
print(pd.DataFrame(iris.data, columns=iris.feature_names))
#带L1惩罚项的逻辑回归作为基模型的特征选择
selector = SelectFromModel(LogisticRegression(penalty="l1", C=0.1, solver='liblinear'))
selected_features = selector.fit_transform(iris.data, iris.target)
print(pd.DataFrame(selected_features, columns=np.array(iris.feature_names)[selector.get_support(indices=True)]))
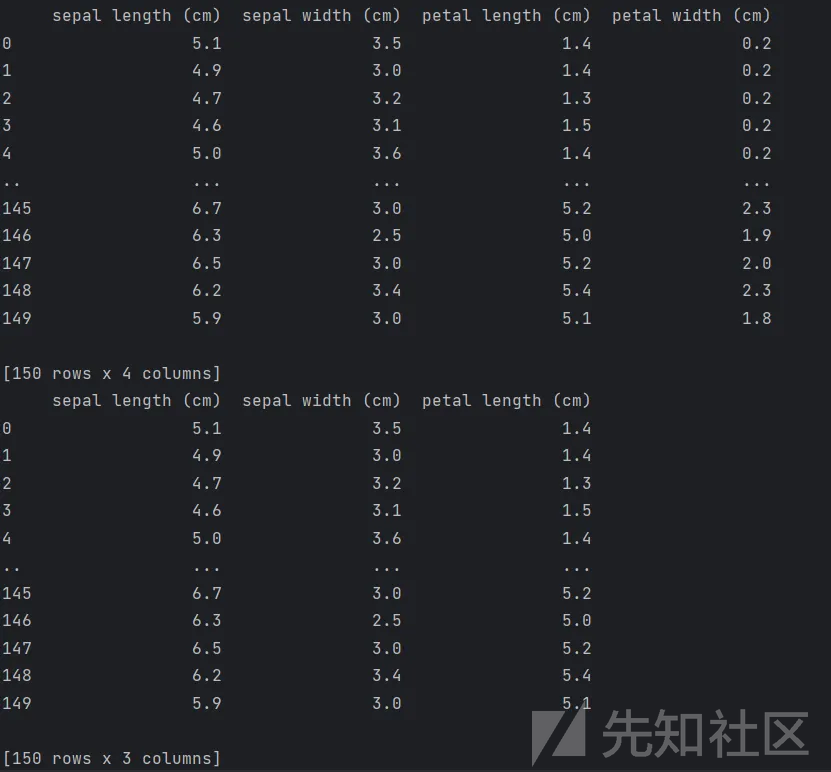
2、 基于树模型GBDT
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# 2. 树模型GBDT作为基模型的特征选择
selector = SelectFromModel(GradientBoostingClassifier())
selected_features = selector.fit_transform(iris.data, iris.target)
print(pd.DataFrame(selected_features, columns=np.array(iris.feature_names)[selector.get_support(indices=True)]))
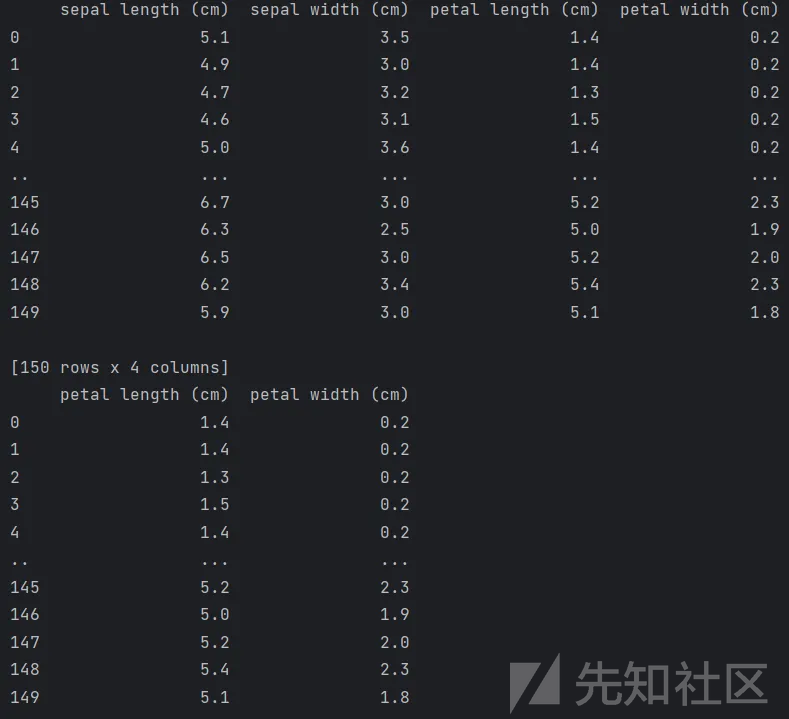
常用数据集
紧接着,提了一下标准数据集,例如DARPA、KDD99、NSL_KDD,详细介绍:入侵检测数据集-CSDN博客
然后,提到了IDS分类的四种情况,TP、TN、FP、FN:
- True Positives:正常样本,检测为正常
- True Negatives:攻击样本,检测为攻击
- False Positives:正常样本,检测为攻击
- False Negatives:攻击样本,检测为正常
最后,提到了一下验证IDS效果的方法:交叉验证。
以K折交叉验证为例,就是把数据集分成K份,轮流取每份做测试集,其余K-1份做训练集,结果取平均。
SVM
SVM分类
首先,介绍了SVM分类器的类别,包括多分类和二分类两个大类。
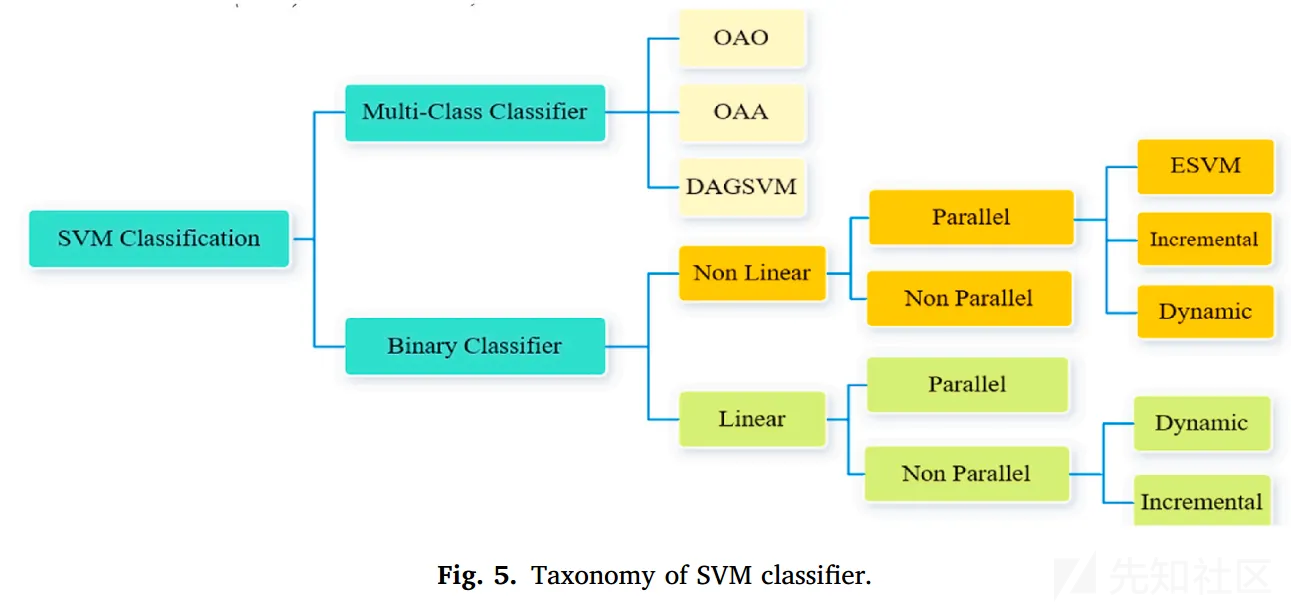
SVM一开始用来解决二分类问题,本小节主要介绍了多分类下OAO和OAA的区别
- OAO:任意两个类别之间建立一个SVM,需要建n(n-1)/2个SVM来分类
- OAA:训练时把每个类别分成一类,其余类别分成另一类,需要建n个SVM来分类
SVM原理
然后,介绍SVM的基本原理,找到一个最优超平面,使得其恰好分开两类不同的样本,最优指的是这个平面到每个样本的距离最远。

SVM核函数
最后,简单介绍了SVM的核函数
Study of the SVM-based IDS approaches
这是这篇文章的主要部分,汇总了常见的SVM IDS,将其分成12个大类,并总结出它们的优势和劣势。
One-Class SVM
原理:OC-SVM顾名思义,只有一个class,那么我就训练出一个最小的超球面(二维就是闭合曲线),把这堆数据全都包起来,识别一个新的数据点时,如果这个数据点落在超球面内,就是这个类,否则不是。例如对于2维数据,大概像下面这个样子:
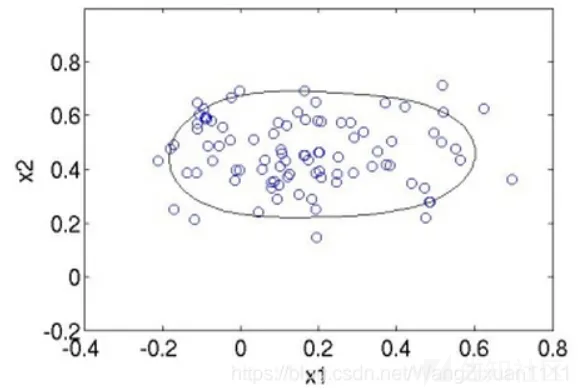
没有全部包裹正常样本的原因是,需要有一个松弛变量来避免这个球面被极个别的极端点影响导致球面过大。
代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import svm
# 生成训练样本
rng = np.random.RandomState(42)
n_samples = 200
X = 0.3 * rng.randn(n_samples, 2)
X_train = np.r_[X + 2, X - 2]
# 训练OneClassSVM模型
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
# 生成测试样本
X_test = np.r_[rng.uniform(low=-6, high=6, size=(50, 2))]
# 预测样本的异常情况
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
print(n_error_train) # 打印出训练集中异常值的个数为40 40/400=0.1 对应nu参数
print(n_error_test)
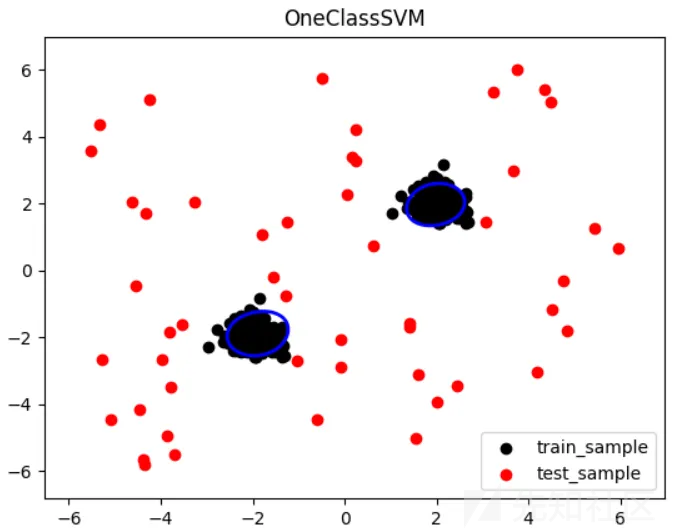
# 绘制训练样本和测试样本的散点图
plt.scatter(X_train[:, 0], X_train[:, 1], color='black', label='train_sample')
plt.scatter(X_test[:, 0], X_test[:, 1], color='red', label='test_sample')
# 绘制异常样本的边界
xmin, xmax = X_test[:, 0].min() - 1, X_test[:, 0].max() + 1
ymin, ymax = X_test[:, 1].min() - 1, X_test[:, 1].max() + 1
xx, yy = np.meshgrid(np.linspace(xmin, xmax, 500), np.linspace(ymin, ymax, 500))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors='blue')
# 设置图形标题和图例
plt.title("OneClassSVM")
plt.legend()
plt.show()
运行结果:
优点:
- 不需要异常数据进行训练,只需要正常数据即可。
- 对于高维数据和复杂的数据分布具有较好的适应性。
- 可以通过调整模型参数来控制异常点的检测灵敏度。
缺点:
- 在处理高维数据和大规模数据时,计算复杂度较高。
- 对于数据分布不均匀或存在噪声的情况,效果可能不理想。
- 需要谨慎选择模型参数,以避免过拟合或欠拟合的情况。
Hybrid SVM-based IDS
SVM + Dcision tree
参考文献:A Feature Selection Approach implemented with the Binary Bat Algorithm applied for Intrusion Detection
原理: 特征选择的过程采用Binary Bat Algorithm(Bat的改进版)+ (SVM或者Dcision tree),目的是选到更重要的特征,检测模型采用(SVM或者Dcision tree)。
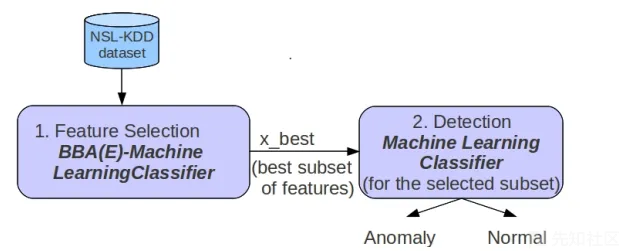
优点:减少了进64%的特征数量,进而提高了分类器的性能
缺点:没说
补充知识:
- 决策树算法:【非常详细】通俗易懂的讲解决策树(Decision Tree)
- Bat Algorithm算法:蝙蝠算法(Bat Algorithm)学习记录
Adaboost + SVM
参考文献:没找到PDF
原理: 主要是Liu等人,利用增强版Adaboost算法(enhanced adaptive boost)对决策树、SVM等弱分类器集成学习,生成一个强分类器来检测。
优点:
- 在Adaboost的框架下,可以使用各种回归分类模型来构建弱分类器,非常灵活。
- AdaBoost具有很高的精度,训练误差以指数速率下降。
- 相对于bagging算法,AdaBoost充分考虑的每个分类器的权重。
缺点:需要不断迭代更新弱分类器,训练比较耗时。
补充知识:
- Adaboost算法:也是增强学习的方法之一,(十三)通俗易懂理解——Adaboost算法原理
KNN+SVM
原理:采用KDDCup数据集,生成五个随机子集,再训练出六个KNN和六个SVM模型,利用加权多数算法集成学习各个模型,然后利用粒子群算法优化参数,得到最终的模型。
优点:准确率有所提升
缺点:没说
补充知识:
- 粒子群算法(PSO):一种优化算法,一文搞懂什么是粒子群优化算法
- 加权多数算法(WMA):集成学习常用的算法集成学习 Ensemble learning
ANN+SVM
原理:数据集采用NSL-KDD,利用多层感知机(MLP)和SVM相混合,特征选择基于信息熵
优点:针对不平衡数据集检测效果较好,可以实现高精度,并减少大规模数据集上的训练时间和测试时间。
缺点:没说
补充知识:
- 信息熵:描述信息系统的混乱程度(不确定度)。信息越确定,越单一,信息熵越小。信息越不确定,越混乱,信息熵越大。因此一个系统的信息熵越高就越无序,信息熵越低就越有序,信息熵越高,使其有序所要消耗的信息量就越大。
- MLP:就是简单的人工神经网络
SOM+SVM
原理:数据集采用KDDCup,混合SOM和one-class SVM来检测异常流量,
优点:针对不平衡数据集检测效果较好,可以实现高精度,并减少大规模数据集上的训练时间和测试时间。
缺点:使用了旧的KDDCup数据集
补充知识:
- SOM:即无监督的ANN模型,SOM(自组织映射神经网络)——理论篇
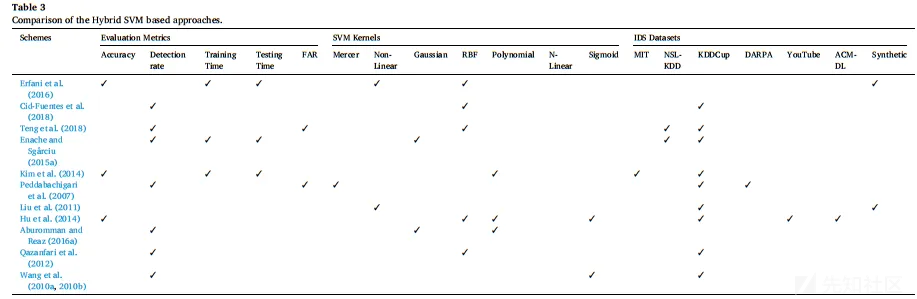
对比
最后,是各个Hybird SVM-based IDS的对比,主要比较了准确率、检测速度、训练时间、SVM 核函数、数据集
Incremental SVM
原理:利用增量学习的方法,将KDDCup划分成初始集和增量集,输入基于SVM的模型中。
主要目的是让IDS能在线更新,对于源源不断的新数据,无需基于整个新数据集来训练模型。
代码:划分初始集用于训练,然后传入增量集,调用partial_fit函数来更新模型。
from sklearn.linear_model import SGDClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成示例数据
X, y = make_classification(n_samples=1000, n_features=20, n_informative=10, n_classes=2, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化增量学习的 SVM 模型
svm_model = SGDClassifier(loss='hinge', max_iter=1000, random_state=42)
# 初始模型训练
svm_model.fit(X_train, y_train)
# 预测
y_pred = svm_model.predict(X_test)
# 输出初始模型准确率
print(f"Initial Accuracy: {accuracy_score(y_test, y_pred)}")
# 模拟增量学习,添加新数据并更新模型
new_data_X, new_data_y = make_classification(n_samples=10, n_features=20, n_informative=10, n_classes=2, random_state=0)
svm_model.partial_fit(new_data_X, new_data_y)
# 预测
y_pred_incremental = svm_model.predict(X_test)
# 输出增量学习后模型准确率
print(f"Incremental Learning Accuracy: {accuracy_score(y_test, y_pred_incremental)}")
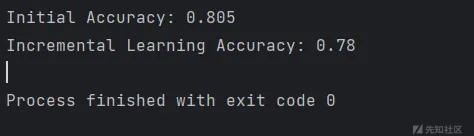
优点:能够让IDS在线更新,持续不断地学习新数据,同时又无需从头训练整个数据集。
缺点:增量学习的效果可能取决于数据的分布和模型的特性,随着增量集训练增多模型可能准确率逐渐下降
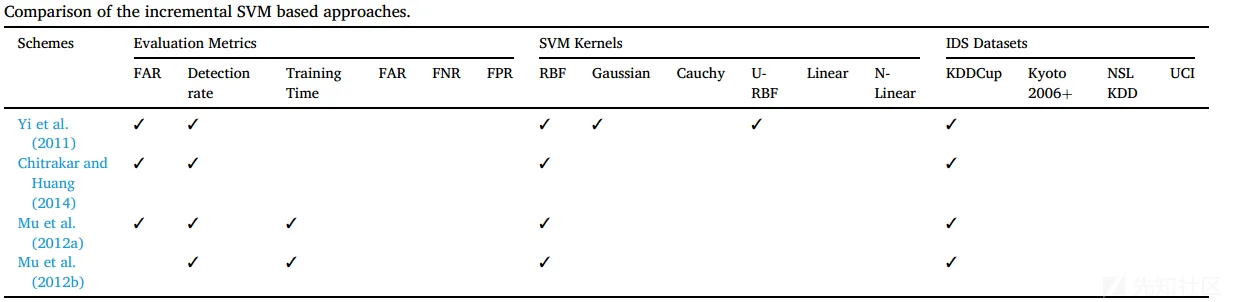
对比:不同方案的I-SVM之间的特性与效果对比
补充知识:增量学习,增量学习(Incremental Learning)小综述
Muti-class SVM
原理:解决SVM只能处理二分类问题的缺陷,主要分为OVO、OVA两个大类的Muti-class SVM。
优点:可以处理各种多分类问题
缺点:需要构造多个SVM,会增加训练时长和检测时长
对比:不同的Muti-class SVM的一些特性对比,包括准确率、所用数据集、核函数等等

Multiple kernel SVM
原理:顾名思义,多核SVM是一个利用多个核函数进行映射,来进行训练的模型。
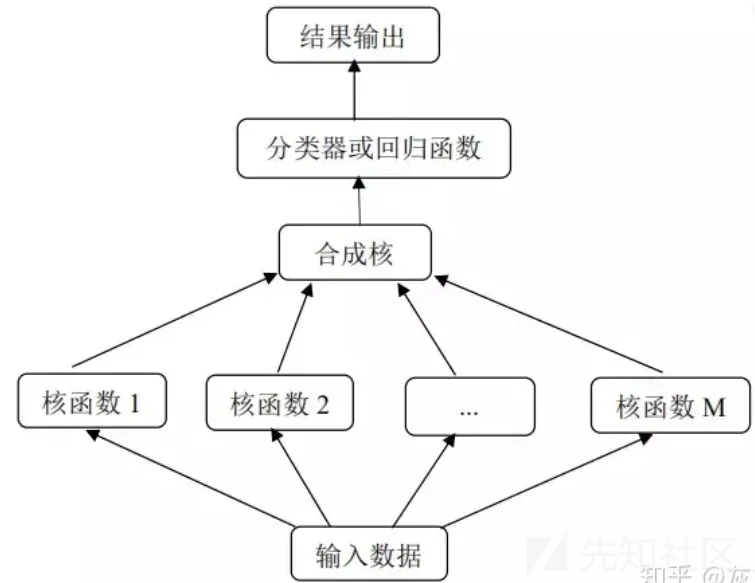
优点:可以减少搜索空间和所需的训练时间,同时提高精确度
缺点:评估是在KDDCup数据集上进行的,较新的数据集未作实验
Multilayer SVM
参考文献:Multi-Layer Support Vector Machines
原理:仿照多层感知机的思路,出现了多层支持向量机,它应用于由多个子问题组成的复杂分类问题。在多层SVM中,核函数将第i个子问题的输入映射到一个更高维的特征空间中,并在该特征空间中实现第i子问题的求解,然后将该新的特征空间作为第i+1个子问题的输出空间,直到完全解决为止。
x是特征向量,S是第一层SVM,M是总SVM。
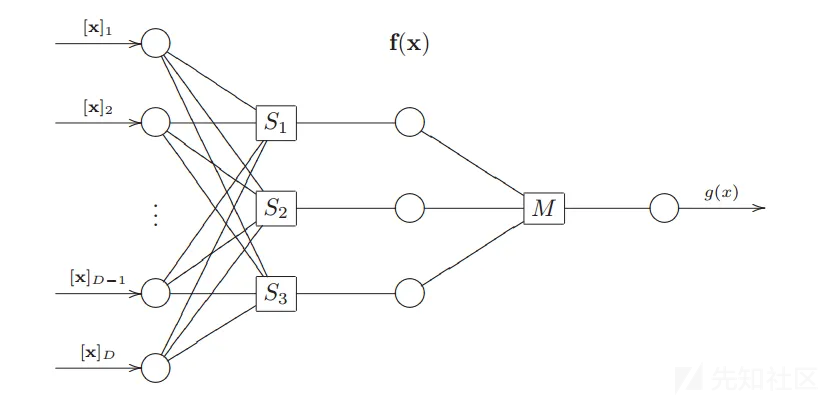
优点:能够解决复杂的分类问题
缺点:多层svm,训练时长不可避免会更长
Clustering assisted IDS schemes
参考文献:A semi-supervised Intrusion Detection System using active learning SVM and fuzzy c-means clustering
原理:同时训练FCM(Fuzz C-means/模糊C均值)和SVM两个分类器,两个分类器同时对输入的样本进行检测,论文中有算法写了两个分类器的权重。
优点:
缺点:没写
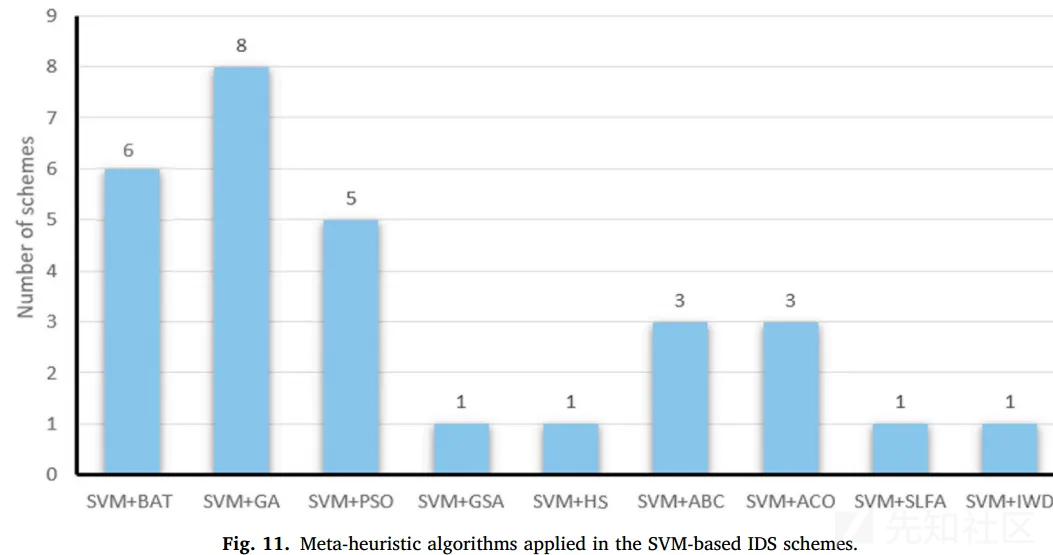
Meta-heuristic algorithm+SVM
原理:将不同的元启发式算法与SVM分类器相结合,以提高IDS的检测能力。通常,使用元启发式算法来训练SVM并找到其最优参数或选择更重要的特征。
优点:相比常用的特征选择方法,元启发式算法能够选择更重要的特征
缺点:没说,可能相比常用特征选择更加耗时?
补充知识:
- 启发式算法:一个基于直观或经验构造的算法,在可接受的花费(指计算时间和空间)下给出待解决组合优化问题每一个实例的一个可行解,该可行解与最优解的偏离程度一般无法估计。现阶段,启发式算法以仿自然体算法为主,主要有蚁群算法、模拟退火法、神经网络等。
- 元启发式算法:元启发式算法是启发式算法的一种改进,它不依赖于特定问题,通常是一个通用的启发式策略(problem independent),因而能够运用于更广泛的方面
LeastSquare SVM
原理:采用LS-SVM,它是SVM的改进版,自然就可以提高效率。
优点: LS-SVM方法通过求解线性方程组实现最终的决策函数(不等式变成等式),降低了求解难度,提高了求解速度,使之更适合于求解大规模问题,更适合于实际问题,虽然不一定能获得全局最优解,但仍可获得较高的识别率。
缺点:缺少稀疏性,对于每一次预测都需要所有训练数据参与
补充知识:LS-SVM(最小二乘SVM),机器学习:最小二乘支持向量机
Multi-level SVM
原理:采用“多级”SVM来训练IDS处理恶意行为和攻击
优点:提高检测准确度
缺点:训练时间变长、没考虑特征选择和提取问题、数据集用的KDDCup99太老
PCA + SVM
原理:利用PCA(Principal Component Analysis)对数据集进行降维,再应用到SVM-based IDS上。
优点:降低特征维度,减少训练和检测的时间,提高IDS的效率
缺点:减少特征,检测准确度可能会有所下降
补充知识:PCA(主成分分析):常用的数据降维方法,它将数据投影到由数据本身构造的子空间上,从而达到降低数据维度的目的。
Rough set theory + SVM
原理:利用RST对数据进行预处理,用于减少SVM模型用于训练和测试的维数,然后用SVM训练
优点:降低特征维度,减少训练和检测的时间,提高IDS的效率
缺点:减少特征,检测准确度可能会有所下降
补充知识:粗糙集与数据降维,模糊粗糙集及数据降维-CSDN博客
Discussion
最后是这篇综述统计的,关于上述一系列SVM的相关信息。
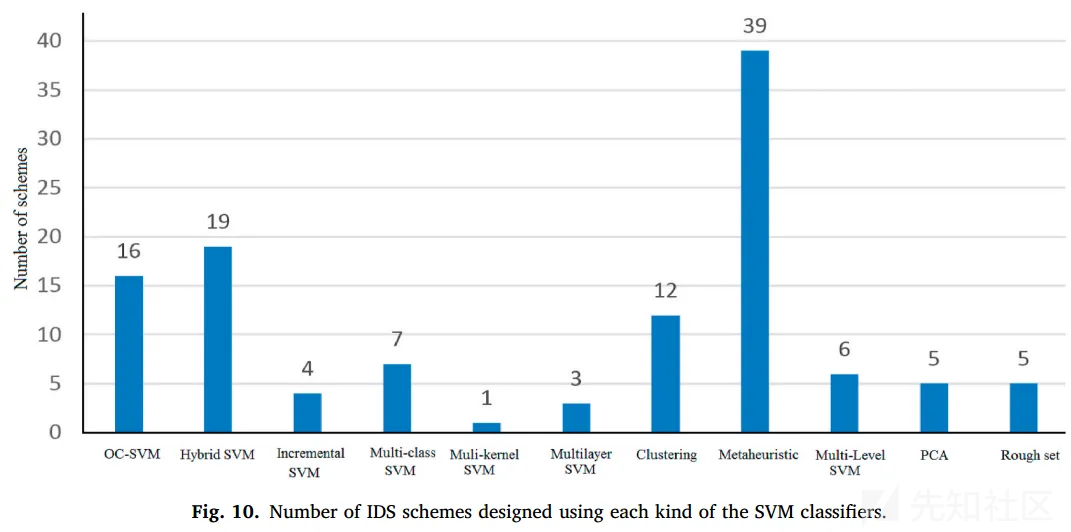
检测速度和准确率是主要的评价指标,(FAR是误识率,人脸识别里用的比较多)
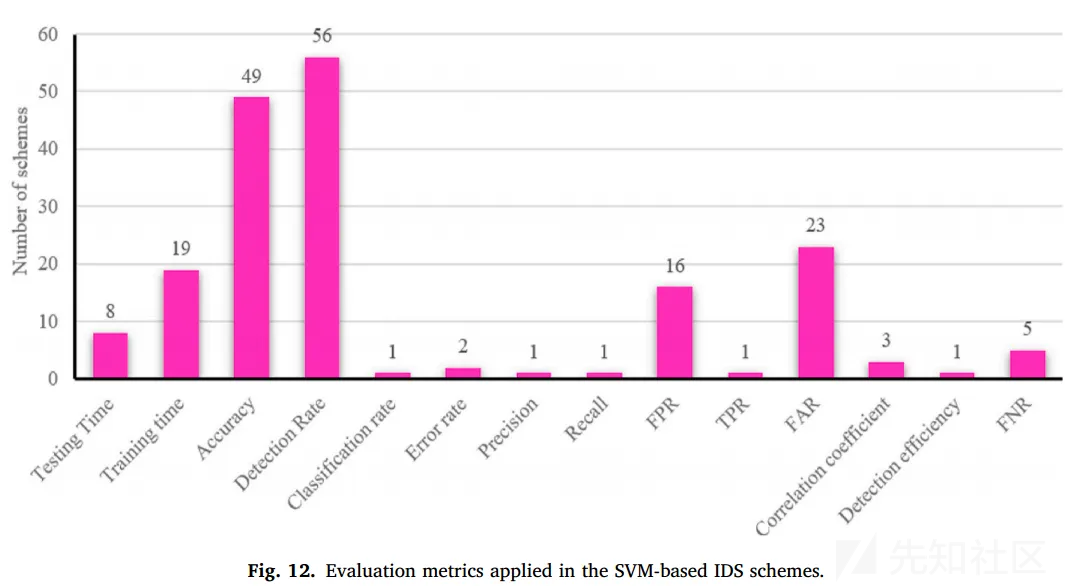
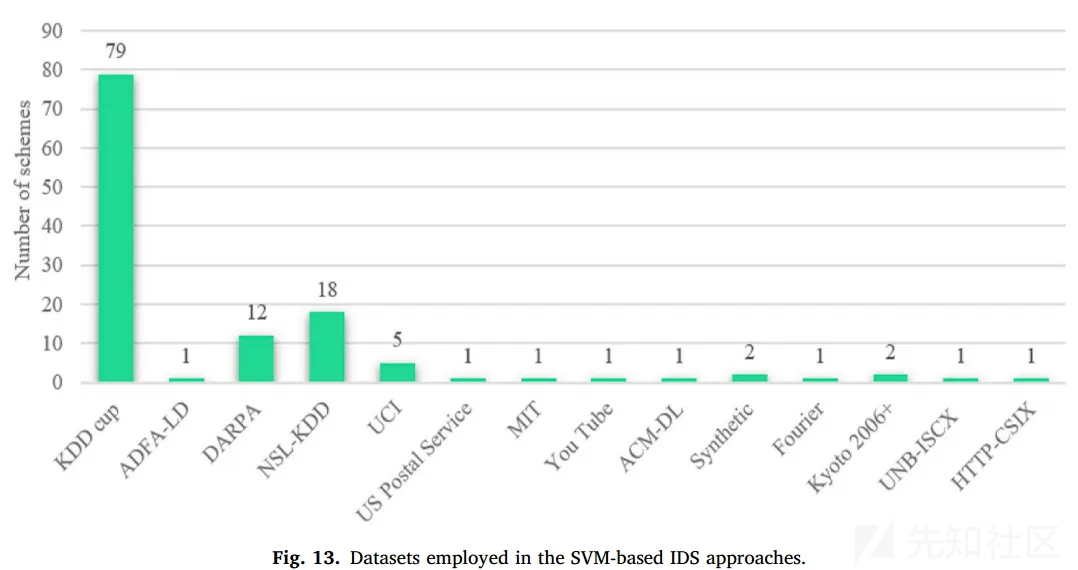
上述这些svm-based ids,用得最多的是KDDCUP99这个比较老的数据集
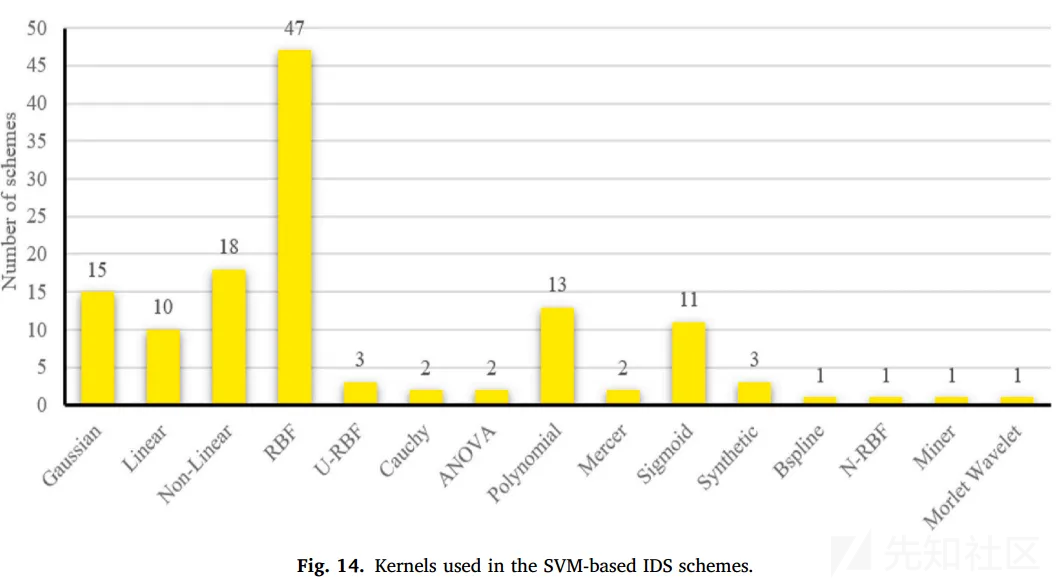
各个svm-based IDS中,核函数也是RBF(高斯核函数)用得最多,它也是比较常用的核函数。
高斯核函数的优点在于可以适应不同的数据集,主要缺点是计算复杂度较高,特别是在处理大规模数据集时。
Future
- 针对大数据的IDS模型训练,如何解决训练时间过长的问题?
在不丢失数据中有价值的信息的情况下减少数据点的数量,例如Wang提出了一种样本提取的异常入侵检测方法
- 归一化方法的选择
根据SVM的类型和核函数,选择正确的归一化方法是非常重要的,通过选择更好的归一化方法来提高SVM分类器的性能是一些方案研究的一个重要问题。
- 机器学习方法的选择
目前大部分svm-based IDS 都是基于全标签的数据集进行训练的,然而实际情况下很多数据可能是没有标签的,所以半监督学习也是值得研究的方向。
- 增量学习/终身学习
网络安全没有银弹,为了识别到最新的攻击,IDS必须不断地进行新的训练,此时增量学习的优势就体现出来了。
Summarize
读完这篇综述,可以了解各种特征选择的方法、各种数据降维的算法、增量学习、各种集成学习的算法等等。
通读综述可以发现,SVM-based IDS这一块的内容十分地完善,光分类就有12种。
用导师的话说,不要轻视简单的方法,稍微结合变种一下,一样可以是创新点发文。
 转载
转载
 分享
分享

-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-

没有评论