
前言
论文名称:tabby:Automated Gadget Chain Detection for Java Deserialization Vulnerabilities
发表期刊:IEEE DSN(CCF B)
Tabby的源码分析和实际应用已经有很多师傅分析过了,本文通过阅读Tabby作者发表的论文,简单分析一下Tabby解决了什么问题、主要算法思想、工具的优势和不足等等。如有错误,还请斧正。
摘要
挖掘Java 反序列化链现存问题:
- 实际漏洞挖掘过程中,利用链复用困难。因为每条链子基本都是针对特定环境使用的,所以如果想要复用之前挖掘的链子,往往需要根据当前环境进行微调,也就是调试链子的过程。这个过程往往是很耗费时间的。
- 人工挖掘利用链,耗时长且存在重复的机械步骤。利用链的挖掘往往是从sink method出发,向上寻找函数调用,直至回溯到source method,由于这个过程依赖于人工审计,目前没有一个比较好的方法将其自动化,人工挖掘往往是一个工作量巨大的任务。
- 现有工具只能分析源码,没法源码结合依赖组件一起分析,而目前大部分的gadgets chain都是源码+依赖的形式,即 gadgets chain = source code gadgets + lib gadgets。
针对上面的问题,论文提出了一个自动化的框架:Tabby,它基于soot框架和Neo4j图数据库来半自动化地寻找gadgets chains,安研只需要编写查询,即可获取所有由sink到source的利用链。
论文作者使用Tabby工具分析Apache Dubbo组件,挖出了80多个链子,并且拿到了7个CVE编号。
主要贡献:
- 提出用代码属性图(CPG)存储代码语义信息,将代码抽象成一个中间层。同时考虑到在CPG中寻找链子的时间复杂度,提出一种剪枝算法(可控变量算法),去除图中无效的节点和边。
- 支持项目源码+组件依赖一起构建CPG,解决了现有工具只能分析Java应用的单个模块的问题。
- 通过Neo4j图数据库来存储所有查询到的gadgets chain,提高链条复用性。
关键词:代码属性图、代码分析、漏洞检测
设计与实现
总览
首先,为了解决链子的复用性问题,本文将程序抽象成代码属性图(CPG)这一中间层的数据结构,然后将保存在基于neo4j的图数据库中,实现链子的存储工作。
其次,为了解决在寻找链子的复杂度问题,本文提出了变量可控性算法来优化CPG的构建,去除一些明显不可控的节点和边,加快tabby-path-finder在CPG中的搜索。
最后,基于gadgets chain finder算法,开发了tabby-path-finder插件,用于实现在CPG中的路径搜索功能。
构造代码属性图
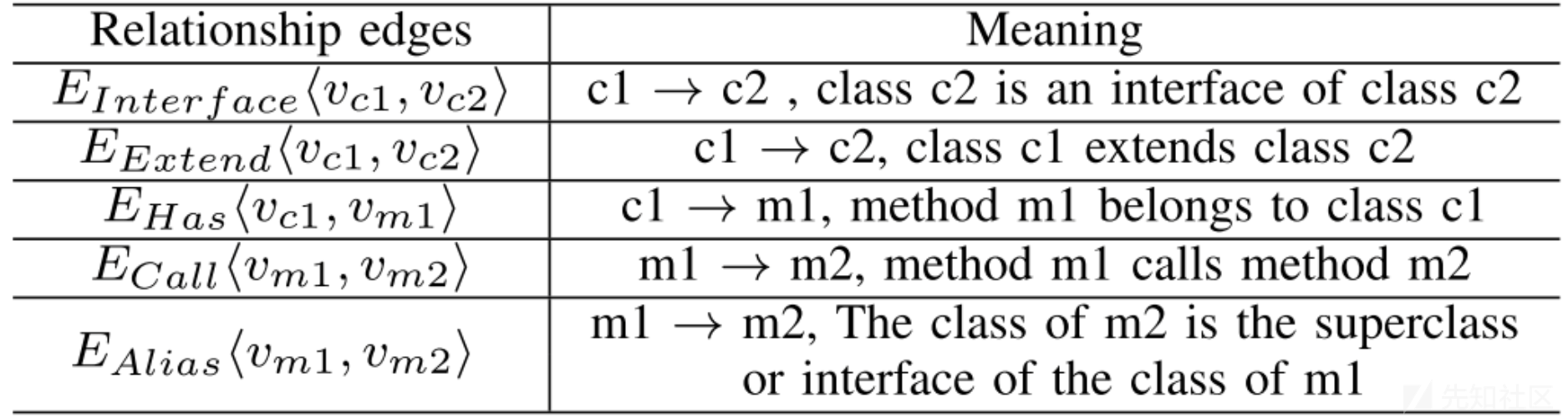
CPG定义:CPG是一个有向图,节点有Class、Method两种类型,边有Extend、Interface、Has、Alias、Call五种类型。不同节点之间连接的边所代表的含义如下表所示:
语义信息提取:提取Jar包/tar包中的语义信息,包括类、方法、控制流图等,用于后面构造CPG。
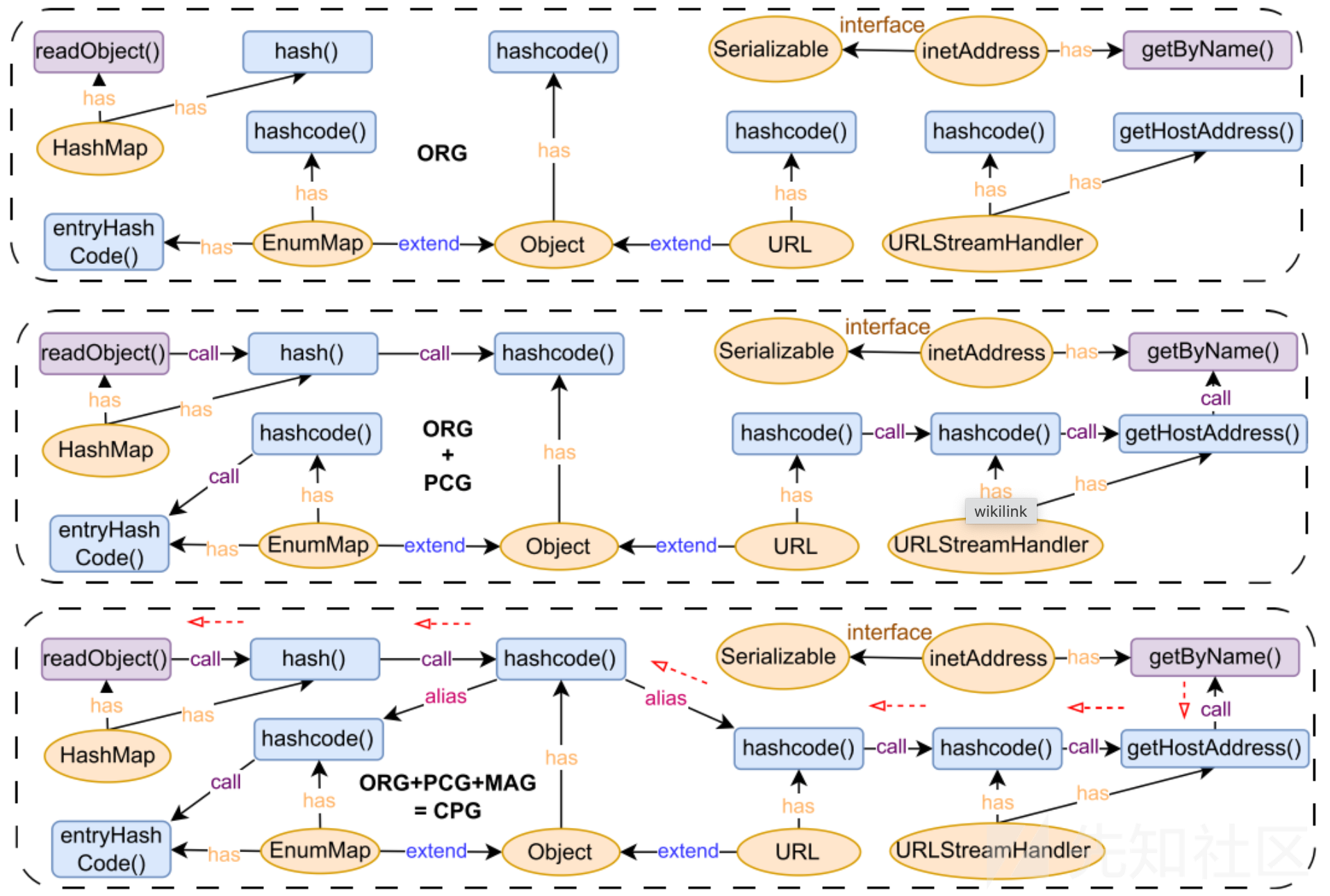
对象关系图(ORG):主要包含所有class node和method node,以及节点间基于静态分析得到的基本关系,如has、extends、interface。ORG构造CPG的基础图。
精确函数调用图(PCG):主要包括节点间的精确函数调用关系,由函数调用图(MCG)经过可控性分析算法剪枝而成,MCG则是在语义信息提取步骤中由控制流图(CFG)生成。
同名函数图(MAG):主要存储父类与子类、接口类与实现类之间的同名函数关系。由于java的多态特性,相同参数、相同返回值的函数可能存在于某个类以及他的父类或者接口中,如何定位我们真正需要的函数就变得十分困难,所以需要在构建图的时候特别表明,后续可使用finder插件查找。
CPG构造过程:CPG = ORG + PCG + MAG,构造分成三步,以ORG为基础依次添加边。
下面以URLDNS链为例,给出了构造CPG的过程:
参数可控性分析算法
设计思路:使用一个指向性、区域敏感算法,排除掉不可被利用/控制的函数调用,返回PCG。
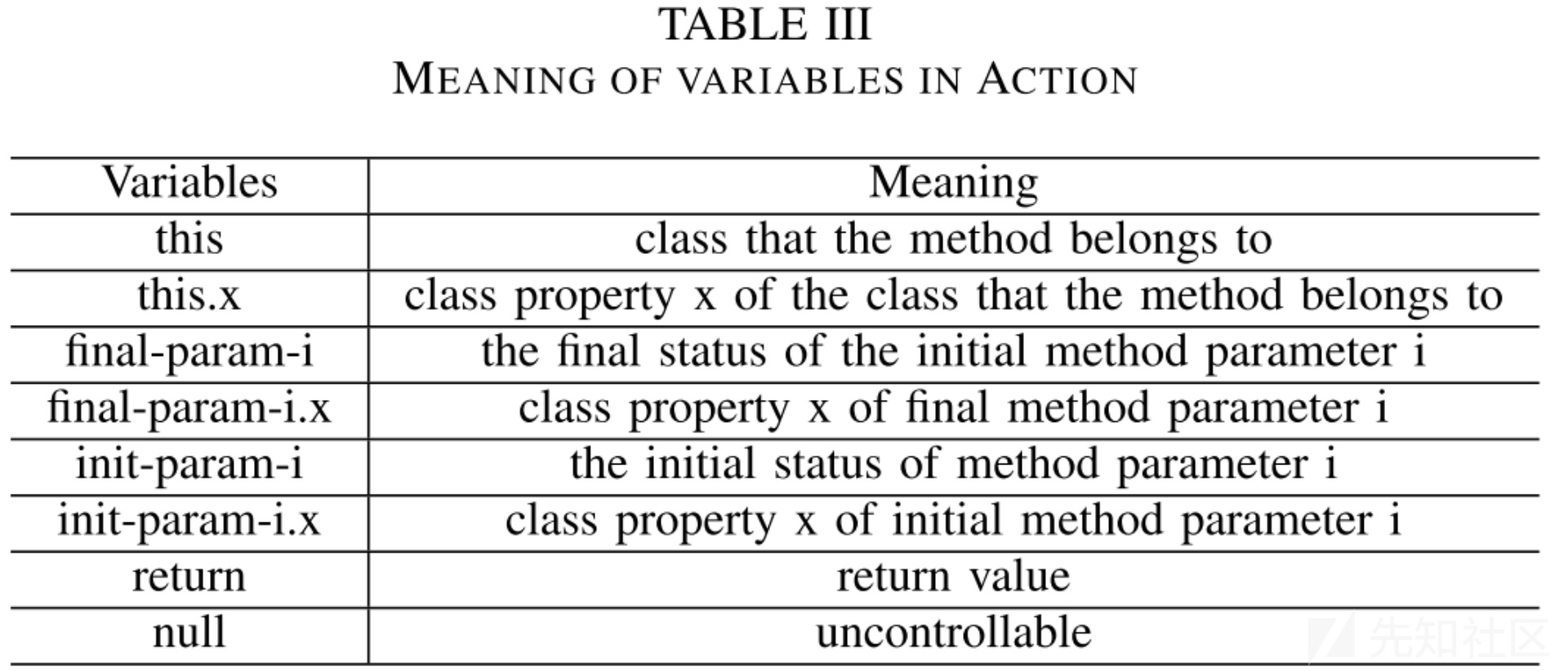
Action:method节点的属性,一个字典,用来表示函数参数和返回值在执行过程中的变化。
Action字典中每个元素是\<key, value>的形式,代表变量key经过函数执行最终指向变量value。
作者定义了变量的几种可能的类型,如下表所示:
LocalMap:method节点属性,也是一个字典,每个元素存储当前函数的\<变量,权重>
Pollution Position:函数调用边的属性,一个数组,存储调用函数的caller和传入参数的权重,会用在gadgets chain finding里用到
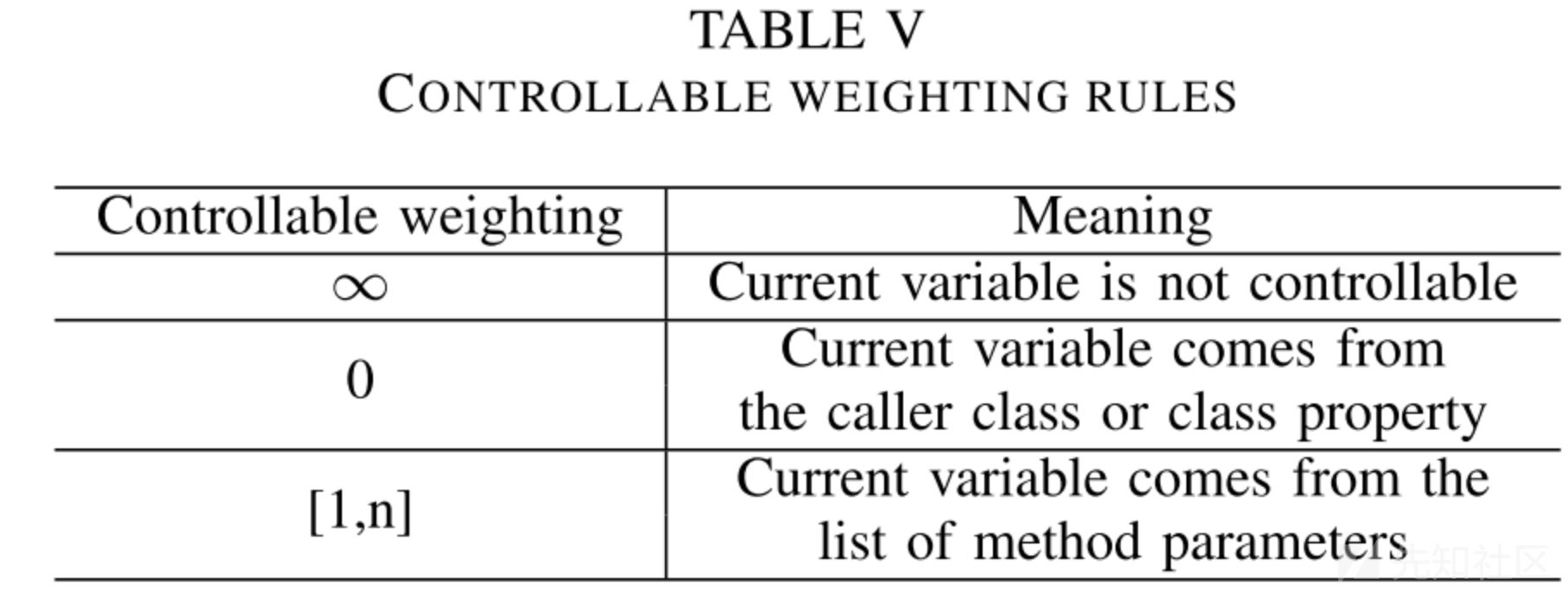
权重的分配:,基于作者定义的规则,如下表格所示:
算法实现:
函数主体:doMethodAnalysis;输入:程序控制流图(CFG),输出:results
从for循环开始看,如果当前语句不是return和函数调用,就解析stmt里的变量,给变量分配权重;
如果是函数调用语句,就会递归调用doMethodAnalysis()语句去解析函数内部的代码并分配权重,这里涉及到caller和callee的LocalMap的合并问题,作者用到了calc()和correct()两个函数实现。
如果是return语句就直接保存result到results,开始分析下一行代码。
如下图,左边的算法结合右上角的例子,观察LocalMap变化过程,结合上文很容易理解这个算法

利用链查找算法
由于在构造CPG时引入了alias method graph,不是所有的alias method node都可以最终到达sink method,所以需要使用finder plugin从sink method开始回溯,以此方法查找是否存在真正可用的gadgets chain。
核心思想:通过执行算法,如果能从sink method回溯到source method,证明找到链子。
trigger condition:sink method的属性,一个数组,用于存储哪些参数必须是可控的,通俗来说就是sink函数触发条件/调用条件

sink method:作者搜集了Java 反序列化中常见的一些sink method,如下表所示:
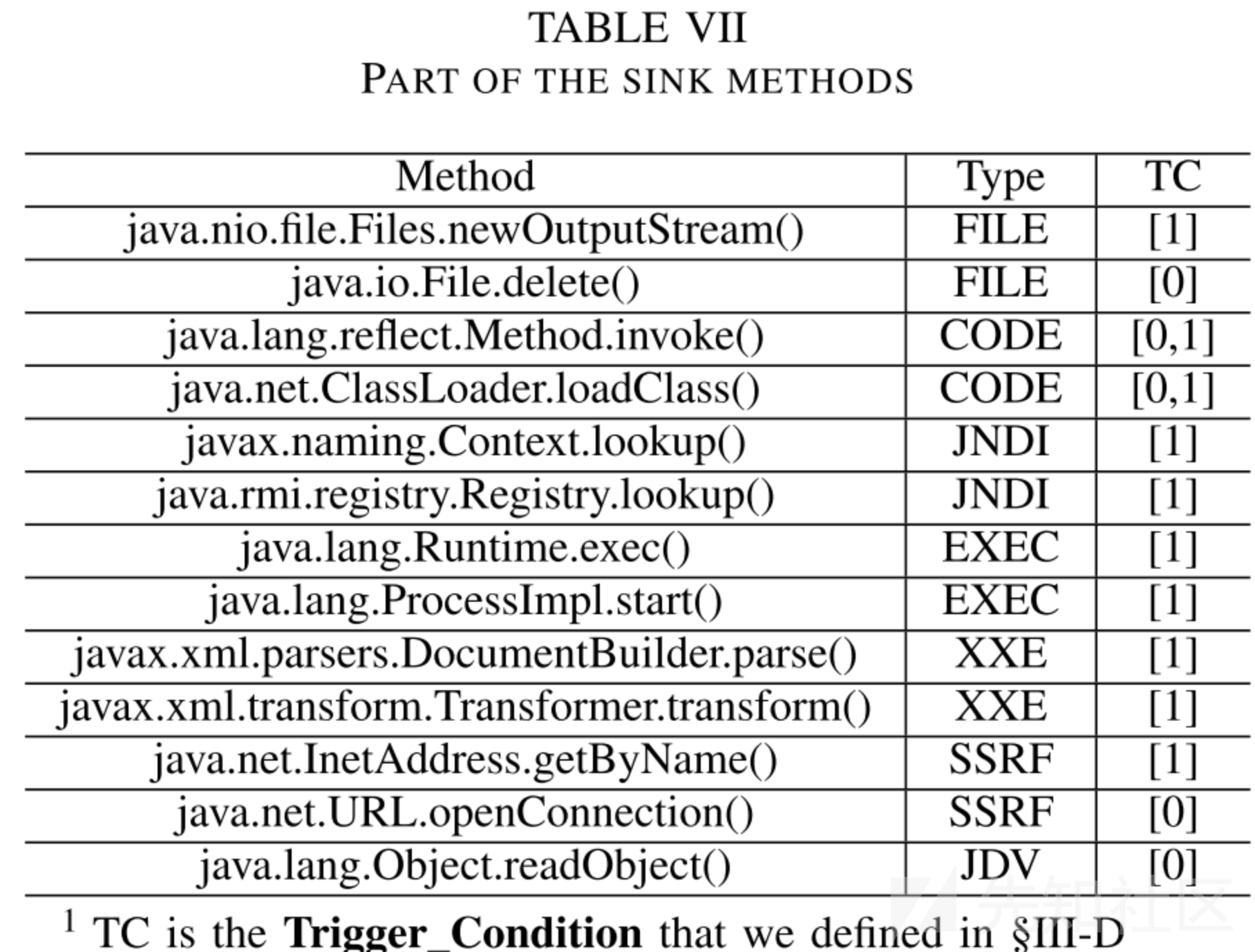
tarverse函数:传入TC、PP数组,生成新的TC next数组,本质是根据当前TC来截取PP
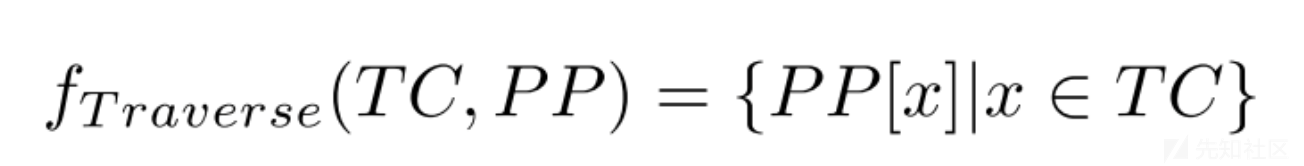
Expander算法思想:判断PP是否满足TC要求,以此决定回溯路线,每次拓展当前path的一个node,并返回新的path和tc。
Expander算法实现:
函数主体:Expander;输入:path、node_end、Relationship、TC;输出:path_next、TC_next
首先,判断节点间的关系是否为函数调用,如果是则用traverse函数计算tc_next,而tc_next中如果存在∞的元素,说明当前两个节点的调用关系中,存在不可控的变量,于是直接返回。
其次,判断节点间的关系是否为同名函数,如果是的话则直接更新TC_next为TC,继续执行。
最后,返回更新之后的path和tc,一次expander结束。

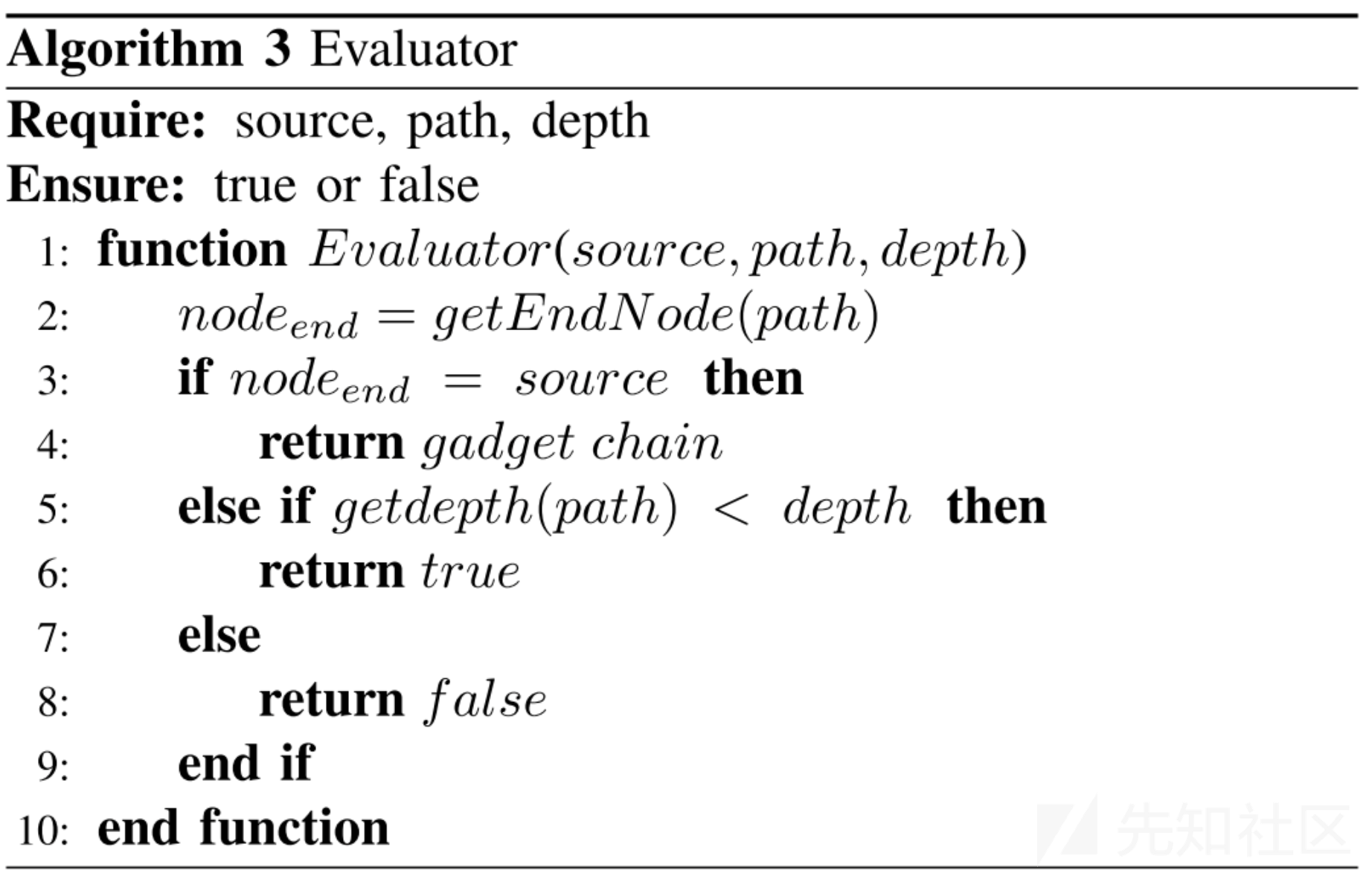
evaluator算法思想:判断搜索深度是否到达限制的深度或者已达到source node,感觉是用来限制回溯算法的执行时间的,避免查询链子的时间过长。
evaluator算法实现:
函数主体:evaluator;输入:source、path、depth,输出:true / false
这个算法相对简单,如果回溯到source则返回利用链,如果未达到设定深度返回true,到达设定深度返回false,没什么好说的。
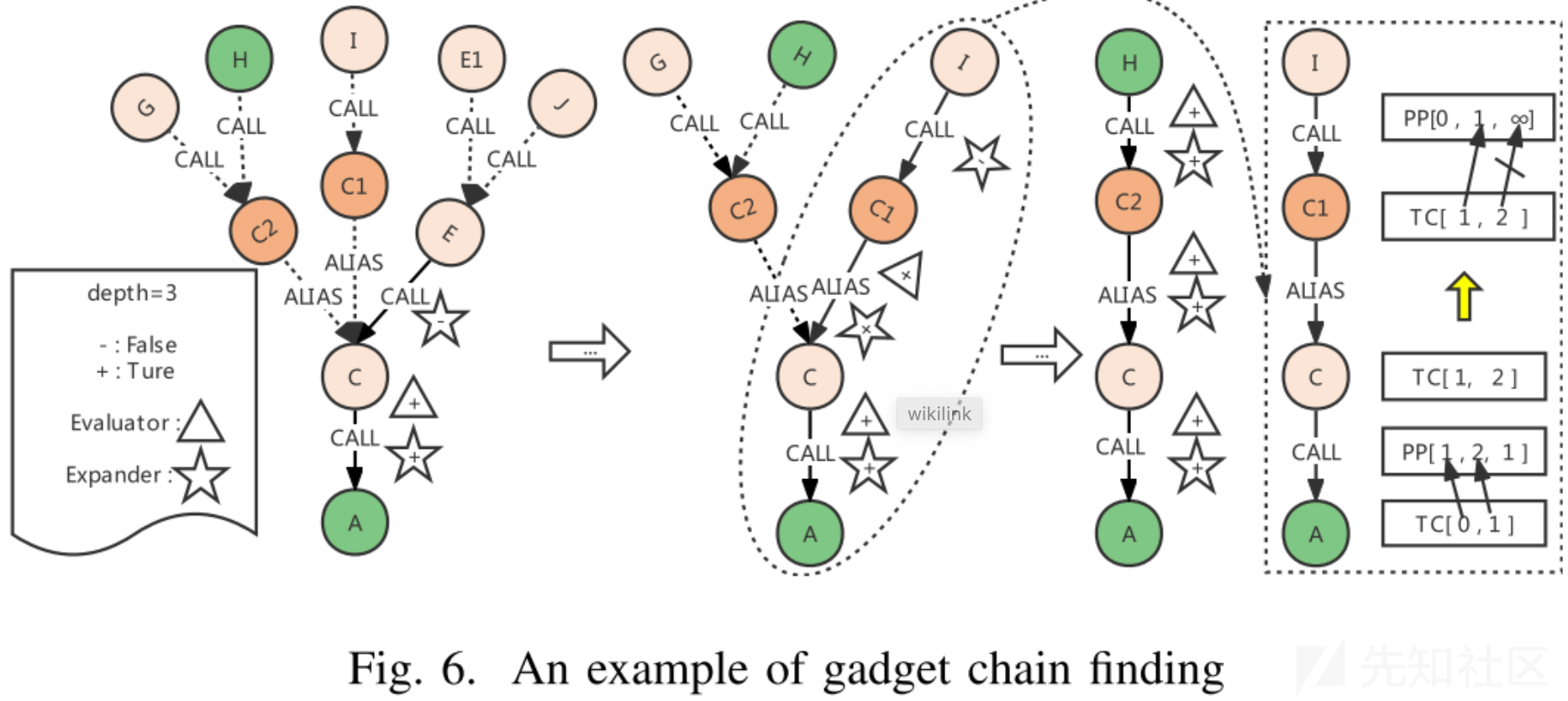
下面通过论文中的例子,演示理解一下path finder算法的工作流程:
前置知识:
- 三角形是Evaluator,五角星是Expander,里面有+表示成功,-表示失败
- A是sink点,由A出发开始查找链条
- A->C->C1->I是失败链条,A->C->C2-H是成功链条
首先看最左边的树,expander在tarverse到node E的时候,发现有变量不可控,这条链不通;
其次看中间的树,同样的,expander在tarverse到node I的时候发现变量不可控,链条不通;
然后我们看最右边的链子,它描绘了如何通过PP和TC判断当前函数调用边是否可控,可以看到node I和node C1不通的原因就是TC要求第二个参数可控,但是实际上PP显示第二个参数不可控;
最后我们看第三棵树,无论是expander,还是evaluator的深度要求都满足,于是寻找成功。
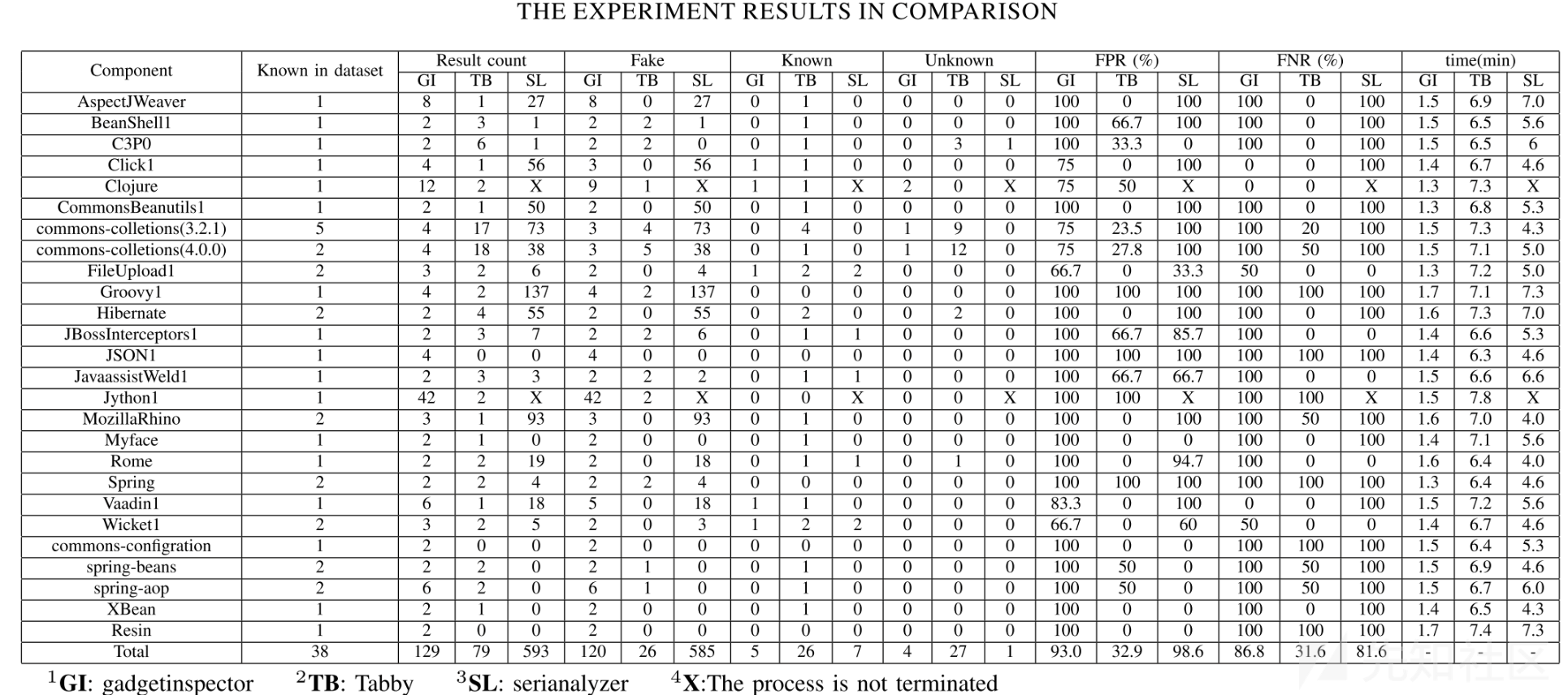
实验对比
这里对比了gadgetinspector、serianalyzer和Tabby,在挖Java 组件链子时的准确性和耗时。
总结
wh1t3P1g师傅基于soot框架和Neo4j图数据库开发出了可以自动化挖掘利用链的工具:Tabby。
Tabby解决了利用链挖掘过程中的痛点问题,并且经过许多师傅的验证(github 1.4k star),其实际使用效果也很优秀,wh1t3P1g师傅就通过Tabby挖到了7个CVE。
Tabby目前存在的限制是,很难通过执行控制流分析来找到包含反射和动态代理的链子,因为动态代理和反射的灵活性使得静态分析很难确定将使用代码中的哪个类或方法。
目前Tabby仅用于寻找Java反序列化利用链,能否将Tabby的设计思路拓展到其他语言(C#、PHP),相信这会是一个不错的研究方向。
 转载
转载
 分享
分享



