
前言
论文名称:Generative Pre-Trained Transformer-Based Reinforcement Learning for Testing Web Application Firewalls
发表期刊:IEEE Transactions on Information Forensics and Security(CCF-A)
前置知识
Transformer Decoder
decoder是Transformer的一个分支,GPT系列就是用的这个
内部用的多头自注意力机制,比RNN好用
主要用于生成式任务,比如本文用来生成payload
语言模型微调
本质是预训练一个基础的语言模型,然后针对特定的任务,在模型的基础上进行微调
方法一般是用初始模型的参数初始化新模型,再传入特定任务对应的数据进行模型训练
本文通过模型微调来生成能够bypass waf的payload
奖励模型
本文中用于输出某条payload是可以bypass waf 的概率,主要用来提高RL的效率。
强化学习
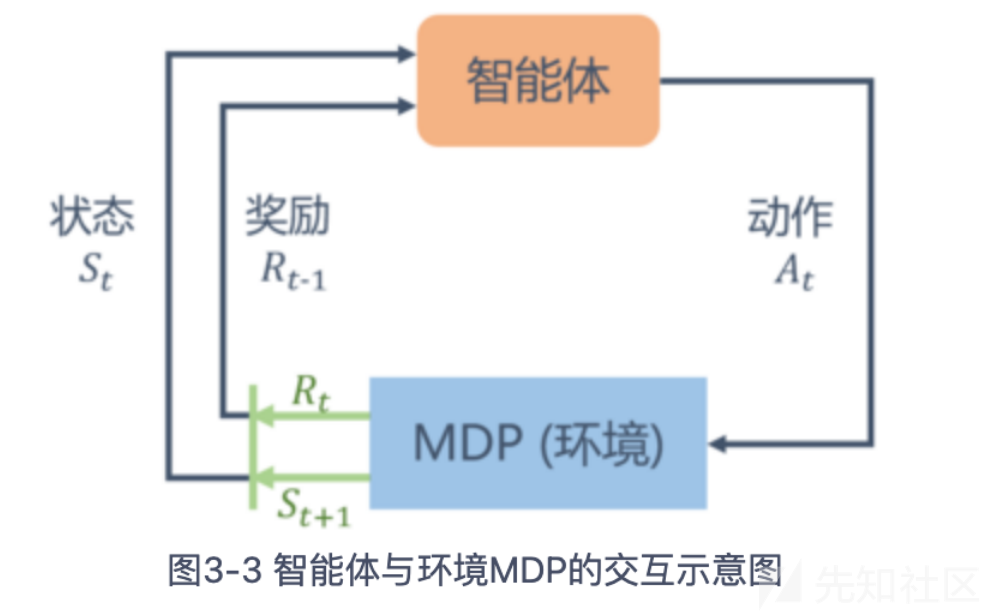
强化学习是机器通过与环境交互来实现目标的一种计算方法。机器和环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器,这种交互是迭代进行的,目标是在多轮交互过程中获得最大的奖励的期望。
马尔可夫决策过程
原理有些复杂,最终目标是求得一个获得最大累计奖励的期望的策略网络。
摘要
发表期刊:IEEE TRANSACTIONS ON DEPENDABLE AND SECURE COMPUTING(CCF A) 2024
作者:IEEE审稿人、北邮、中石油、国防科大、360
提出了一种WAF的黑盒测试方法,基于GPT语言模型、使用RL进行模型微调、使用RM提高RL效率、使用KL散度优化局部优化问题,然后将其应用到两个开源WAF做测试,测试结果表示,其效果远好于目前先进的两种黑盒测试Fuzz方法。
关键词:黑盒测试、强化学习、transformer、waf
介绍
目前的WAF大多是以预定义的策略对流量进行拦截,这就导致了策略过时的情况,所以一般来说WAF是要结合漏洞披露平台进行实时更新。
那么为了测试WAF的时效性或者说防御能力,一般就会由专门的渗透测试人员对WAF进行模糊测试。
模糊测试可以分成白盒测试、黑盒测试和基于AI的测试,其中黑盒测试不需要获取WAF的源码,是相对来说限制最小的。另外,基于机器学习的黑盒测试可以基于已有的payload,去选择新的payload自动进行模糊测试,可以有效提高黑盒测试的效率和性能。
基于机器学习的黑盒模糊测试可以分成两类方法,基于变异的方法和基于搜索的方法。
基于变异的方法,每次从payload池中选取payload和部分数据来变异生成新的payload。同时,为了避免生成大量的无效payload,通常还会使用攻击语法来确保变异的payload符合某种类型攻击的明确语法要求。例如,ML-Driven将一个payload映射到一颗根据攻击语法构造出的解析树中,通过这颗解析树来指导变异payload的生成。
基于搜索的方法,例如ART4SQLi、XSSART和RAT,它们使用机器学习方法对payload聚类,然后利用这种聚类结构来高效地搜索有效的攻击payload。例如,RAT使用深度自动编码器从payload中提取特征并对其进行聚类,然后使用贪婪强化学习来搜索包含可以绕过WAF的payload的聚类。
在基于变异的方法中,预定义的攻击语法(ML-Driven)或变异算子(WAF-AMoLE)发挥着至关重要的作用。但是它们一般都是由专业的安全专家制定的,很容易出现过时的问题。此外,变异方法依赖于初始payload进行生成,payload的空间可能没有被充分探索,导致局部最优问题。
在基于搜索的方法中,发现的payload的语法很容易满足,因为它们来自现有的payload,而不是新生成的payload。然而,为了获得具有令人满意的数量和种类的绕过payload,必须对payload空间进行密集采样,以构造用于搜索的非常大的payload集合。极端的情况是使用某种攻击的所有payload构成的集合,如RAT所做的那样,这在实践中是不现实的。此外,RAT中的贪婪搜索策略也会导致局部最优问题:它集中在那些包含许多绕过payload的簇上,因此没有彻底探索payload集合。
总的来说,上面的两种方法对payload数据集存在限制,例如需要符合攻击语法的payload(ML-Driven)或者需要很大的payload集合(RAT),这使得这两种方法在实际使用中并不理想。与此同时,它们在探索payload空间时也会遇到局部最优问题,从而降低了它们发现绕过payload的能力。
为了解决上述问题,本文提出了基于生成式payload的WAF测试方法,提出以逐个token的方式去生成新的payload。一方面,这种方法不依赖于显式的攻击语法或者巨大的payload集合(例如RAT需要400万个payload,而本文的方法仅需要20 K-200 K大小的payload集合),它通过使用强化学习去微调GPT语言模型,例如给定攻击类型为SQL注入,语言模型通过预训练来学习payload的隐式攻击语法,以适应不同的WAF(例如,ModSecurity或Naxsi)。另一方面,为了在探索payload空间时减轻局部最优问题,本文利用了自然语言处理(NLP)中的强化学习技术,也即通过奖励模型和KL散度,以提高GPTFuzzer的有效性。
另外,本文还把GPTFuzzer生成的三种攻击类型的payload(sql、xss、rce)应用到两个知名WAF(ModSecurity、Naxsi)中做测试,测试结果表明GPTFuzzer明显优于ML-Driven和RAT。
方法
GPTFuzzer的框架可以分成5个部分:数据收集和预处理、语言模型预训练、奖励模型训练、强化学习和payload生成。框架如下图所示:
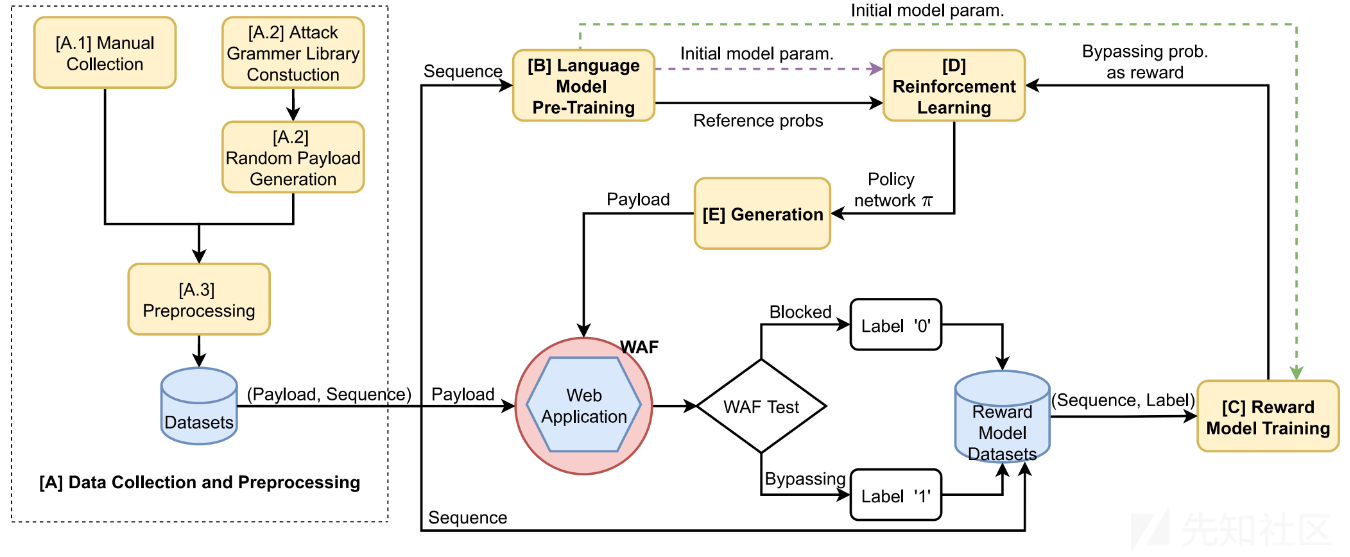
数据收集和预处理
数据收集的途径有两个,人工收集和攻击语法生成。
人工收集包括论文里的数据集、开源数据集和渗透测试工具自动生成的数据集。
攻击语法生成的数据集,即根据特定的攻击构建攻击语法,然后依据攻击语法自动生成payload。攻击语法一方面可以自下而上构建,即通过在现有的数据集中提取模式,并在攻击语法中表达该模式;另一方面攻击语法可以自上而下构建,即通过研究某种攻击的底层机制和原理,从头开始构建攻击语法。
攻击语法生成相比人工收集,显然需要更多的人力和专业知识,但相对获得的数据集的质量也更好。
下面描述一下如何通过攻击语法解析树来随机生成生成payload,左图是攻击语法解析树,右图是攻击语法的标签。简单来说,就是从树的根部开始,递归遍历所有子树节点,直到遍历到叶子节点为止,与二叉树的遍历不同,解析树的遍历顺序是随机选取的,这样才能确保采样足够大的payload空间。

以这个上下文为例,它由、、、四个子节点组成,于是需要递归遍历这四个子节点,而每个子节点又可以继续递归向下细分,以左图中的加粗路径为例,可以得到一条生成的攻击payload,如下图所示:

至于数据的预处理,无论是人工收集的payload还是攻击语法生成的payload,其终究是一条攻击payload,所以预处理的方法都是一样的,就是将一条payload拆分成一个个的token,然后通过一个token-integer的映射字典,把token序列转换成数字序列。简单来说就是:payload -> token sequence -> integer sequence。
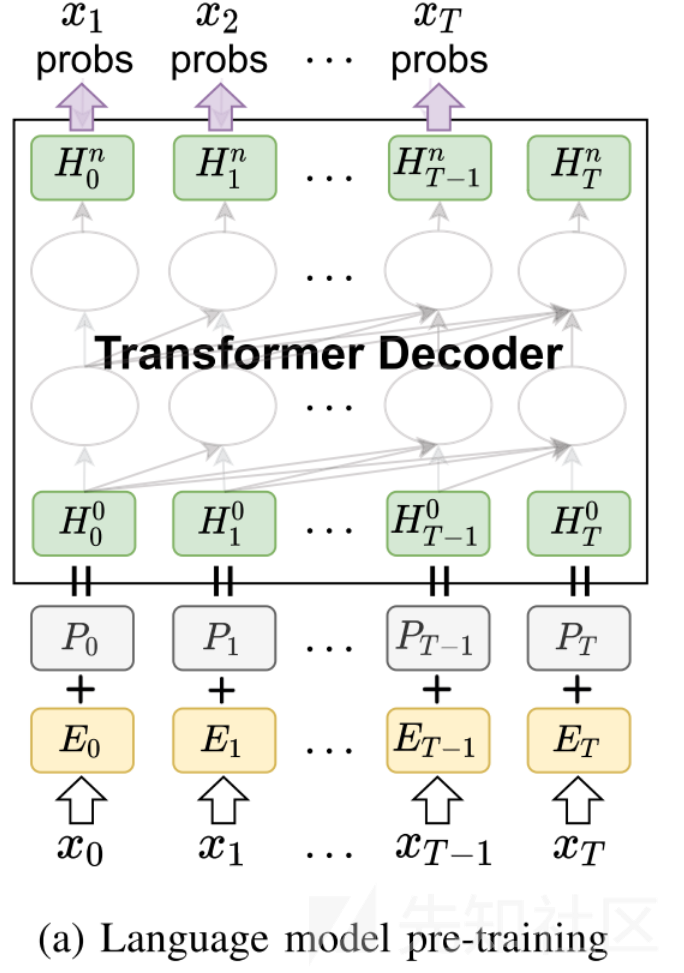
语言模型预训练
本文把payload当作某种“攻击语言”的句子,那么payload数据集就是我们的“语料库”。通过在这个“语料库”上训练语言模型,就可以实现自动生成攻击payload的目的。但是在语言模型能够生成可以绕过WAF的payload之前,它首先应该学会生成符合攻击语法要求的payload,否则生成的payload即使能绕过WAF也是毫无意义的。这就需要我们使用有效的攻击payload来对语言模型做预训练,具体步骤如下:
首先输入的payload token序列, 通过word2vec等方法转换成token编码x
然后因为transformer本身不会处理位置信息,所以加一个Position编码p
最后用Wtoken和Wpos两个矩阵做线性变化成矩阵H,作为Transformer Decoder里多头注意力机制模型的输入
经过多层Transformer Decoder后,最终输出预测的攻击payload序列
奖励模型训练
waf会对输入的payload作出判断,即绕过/拦截。直觉来说可以直接使用waf的结果作为RL的奖励,但是这种简单的奖励反馈会导致RL初期的学习效率降低,特别是当一开始就出现一些可以绕过waf的payload的时候。因此,本文训练一个RM来预测一个payload绕过waf的概率作为奖励,为RL提供学习信号。
首先,从之前生成的payload数据集中选取定量(2000-4000)的payload,输入到waf中做判断获取到结果,然后将结果作为标签加到payload中构建一个奖励模型的payload数据集。
然后,我们使用这个数据集训练奖励模型,来预测payload的绕过概率。实际上,奖励模型模拟了RL和真实WAF交互的这个过程。也就是说,在训练奖励模型之后,在RL阶段不再需要与实际的WAF进行交互。
为了使奖励模型继承预训练模型对隐含语法要求的理解,从而加速其收敛,我们使用预训练语言模型的参数来初始化奖励模型,然后在顶部添加一个奖励预测头。在训练之后,奖励模型的输出被用作RL中的payload的奖励,该奖励比直接测试WAF获得的(绕过/拦截)结果更加有效。
强化学习模型训练
在强化学习阶段,在奖励模型的帮助下,对预先训练好的语言模型进行再次微调,以获得一个策略网络,用于生成payload,这些payload针对WAF进行测试并打上标签,然后重新进入奖励模型和强化学习模型中,这个反复微调的过程直到生成可以bypass waf的payload时结束。
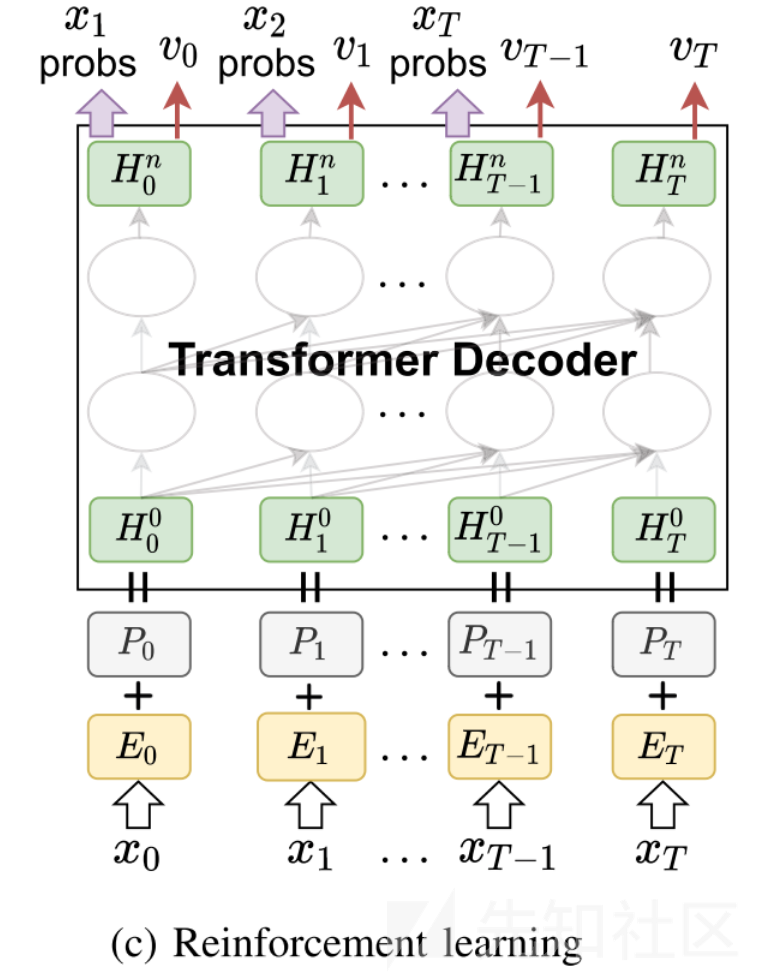
本文强化学习采用马尔可夫决策过程模型,目标是找到一个最优策略,使得智能体从初始状态出发能获得最多奖励的期望。
在GPTFuzzer中,上一小节所述,期望回报由奖励模型提供,该模型模拟WAF的响应。所以WAF和奖励模型即是环境。策略π是一个神经网络,下图的Transformer Decoder,与奖励模型类似,也由预训练模型的参数进行初始化。
强化学习的过程如下图的算法所示。算法使用最近策略优化(PPO)来训练策略网络,可以通过避免那些可能在一步中改变策略太多的参数更新,进而提高训练稳定性。
在算法1中,GPTFuzzer首先使用策略网络生成一组Payload(1-4行),并使用KL散度惩罚(缓解局部最优问题)结合奖励模型来计算期望回报(5-8行),然后计算优势估计值,并根据回报返回估计值(第9行),并通过PPO算法使用这些数据来更新策略和价值网络(11-13行),最后,GPTFuzzer使用更新的策略和价值网络重复上述步骤,当连续的epochs的平均奖励趋于稳定时,算法终止(14-16行)。

payload生成
RL模型训练好的策略网络逐个token生成payload序列,然后输入WAF上进行测试。生成算法如下所示。
Transformer Decoder会顺序输出payload的token序列,首先基于x0生成x1,然后基于x0和x1生成x2,以此类推,直到生成ID或达到预定义的最大长度Tmax(3-7行)。

实验结果
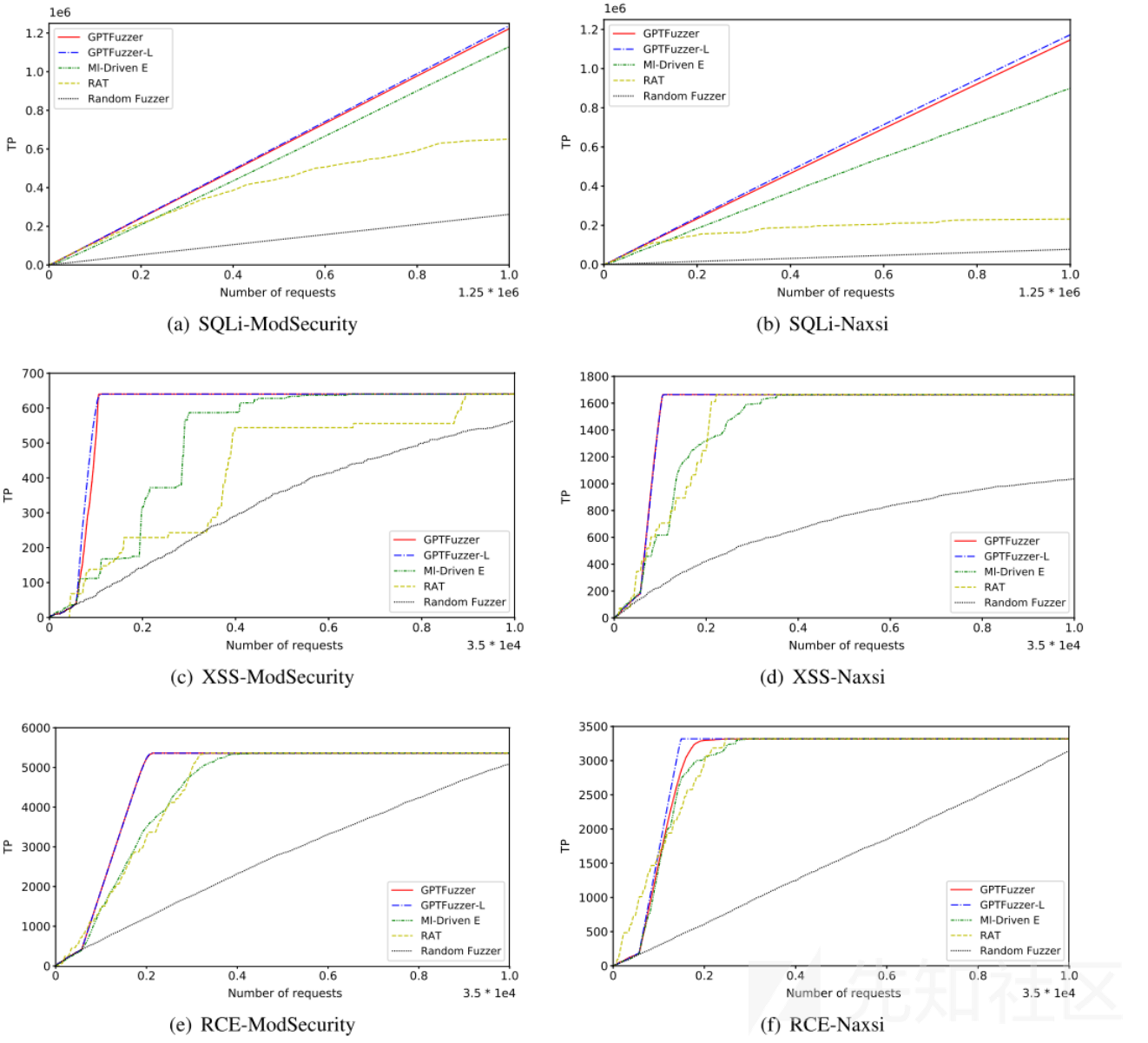
GPTFuzzer相较于其他方法的优势对比。
曲线越尖锐,其对应的方法越有效,因为理想的WAF测试方法旨在以尽可能少的请求获得尽可能多的payload(TP)。GPTFuzzer具有更高的TP值(即最尖锐的曲线),并明显优于其他方法。
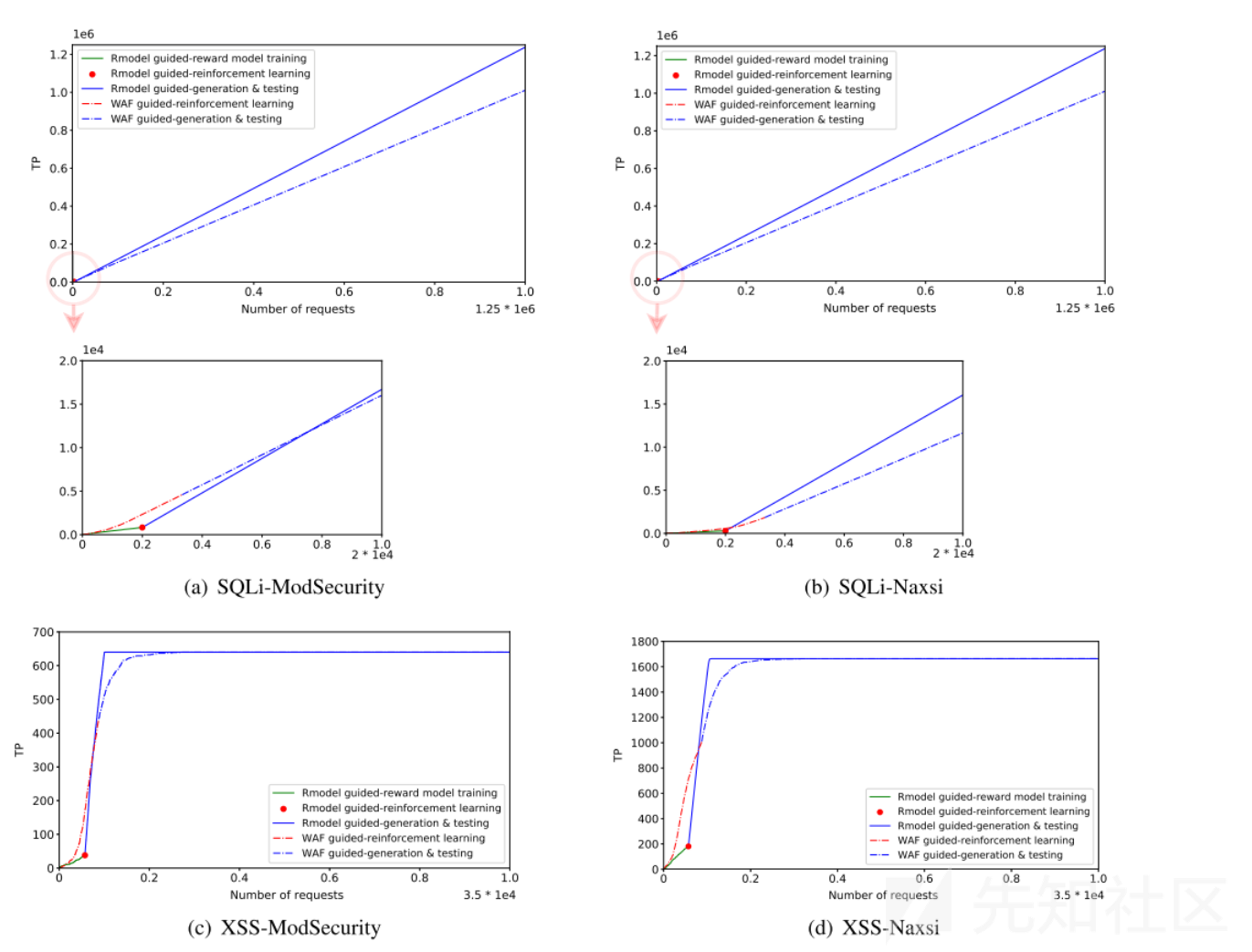
主要验证RM引导的RL比直接由WAF引导的RL更加优秀
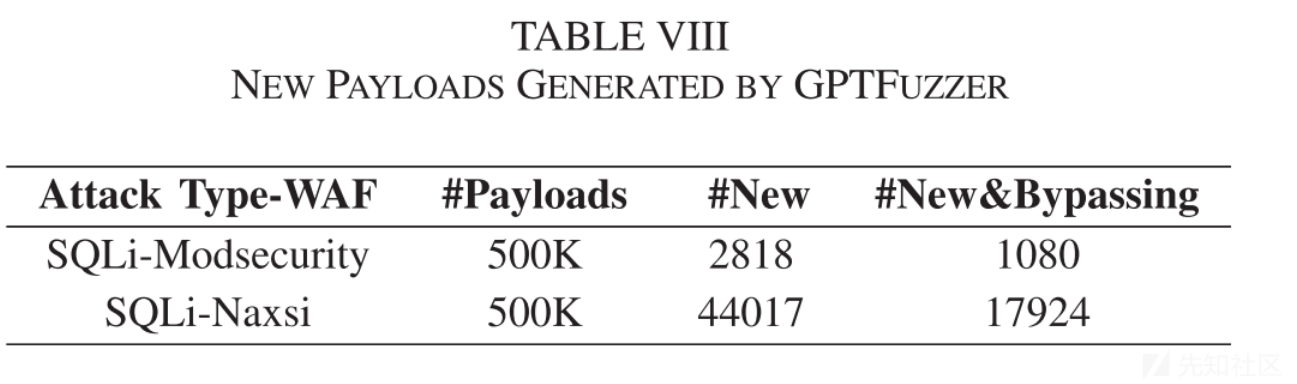
验证GTPFuzzer是否能生成攻击语法之外的绕过payload
总结
本文提出了GPTFuzzer,这是一种生成式的黑盒WAF测试方法,通过使用强化学习微调GPT语言模型,针对目标WAF逐个token生成bypass的payload。评估结果表明,在限制较少的情况下,GPTFuzzer的性能明显优于最先进的基于变异和基于搜索的方法。
本文的主要贡献点:
通过结合GPT、强化学习,提出了一个实用的生成式的黑盒WAF测试方法
结合了奖励模型和KL散度几种方法,高效地生成攻击payload并减轻局部最优问题
实现了GPTFuzzer并应用于两个著名的开源WAF中,实验结果表明其优于目前最先进的两种方法
是垂直大模型在Web安全领域上的新尝试,为垂直大模型在安全方面的应用提供了新的思路。
 转载
转载
 分享
分享

