
基于深度学习(TextCNN&XGBoost stacking融合)对恶意软件的检测算法设计与实现
本文将基于深度学习技术提出一种新的利用模型融合的恶意软件检测模型。这种方法通过分析恶意软件的动态行为特征,即其运行时调用的的底层 API 信息,利用 one-hot 编码和word2vec 词向量算法的结合,通过将 API 名称及其调用序列特征映射到向量表示,并使用上下文嵌入技术将 API 名称的上下文信息嵌入到向量表示中来构造特征工程。而在模型方面,分别提出了基于TextCNN的检测模型与基于XGBoost的检测模型,最终基于模型融合将二者结合,提出一种新的恶意软件检测模型。
恶意软件检测,是近年来信息安全领域的热门研究方向之一。随着互联网和计算机技术的不断发展,恶意软件的数量和种类也越来越多,其攻击计算机和网络系统的手段花样百出,造成了巨大的用户损失。因此,在信息安全领域如何对恶意软件进行有效的检测和识别就成了一个重点课题。而传统的恶意软件检测技术已经无法高效准确地检测出互联网上不断出现的新的恶意软件,其主要缺点是:
1.传统的恶意软件检测技术很大程度上依赖于人工对代码特征的选取,一旦特征选取的数量不够多且选取的特征不具有代表性,检测准确率就会大大下降。
2.当已有的恶意软件经过混淆,加密等手段后,或是出现某种新的恶意软件后,传统的恶意软件检测技术无法自适应地学习到新的恶意代码特征,这也是很多零日漏洞可以造成很大危害的主要原因。
本文主要研究内容如下:
1. 恶意软件数据集收集。构建一个可靠的、全面的数据集对于深度学习模型的训练和优化至关重要。本文选取了阿里云恶意软件检测大赛的公开数据集。
2. 恶意软件分类与恶意软件检测技术研究。本文对恶意软件的分类及恶意软件的防范作了相关介绍,同时针对恶意软件检测技术常见的两种分类:静态检测技术及动态检测技术,介绍了目前研究学者在这两个方面的研究成果。最后总结前人经验,提出了一种新的利用模型融合将 TextCNN 与 XGBoost 模型结合的恶意软件检测模型。
3. 基于模型融合将 TextCNN 与 XGBoost 模型结合的恶意软件检测模型。为了解决传统机器学习检测模型无法检测经过多次混淆后的恶意软件变种,检测准确性依赖于人工样本标注特征的问题,以及大多数深度学习检测模型占用资源较高,检测时间较长的缺点,本文提出了一种新的基于模型融合的将 TextCNN 与 XGBoost 模型结合的恶意软件检测模型。
检测方案设计
第一步,在数据处理方面,该方案利用一种将 One-Hot 与上下文嵌入相结合的 API 特征向量模型,通过将 API 名称及序列特征映射到向量表示,并使用上下文嵌入技术将 API 调用函数的上下文信息嵌入到向量表示中,提高了数据的表示能力和模型的鲁棒性。
第二步,在模型方面,该方案首先建立了基于 TextCNN 分类模型的恶意软件检测模型,这是一种基于深度学习的分类模型,具有可以自学习,且处理文本数据效率高等优点,且在特征输入中加入了多个长距离 n 元组中有效性最高的 n 元组信息;又提出了基于 XGBoost 模型的恶意软件检测模型,XGBoost 模型的特征输入是短距离的 ngram 信息和 word2vec 的整体语义信息,它的优点在于具有比较完整的整体语义信息以及短距离 n 元组信息的非线性表示,且检测速度快。
第三步,我们选择强强联合,将这两个模型融合,来获得更高的检测率、在准确率较高的条件下的相对较短检测耗时以及更强的模型泛化性。该方案整体的检测流程框架如图所示:
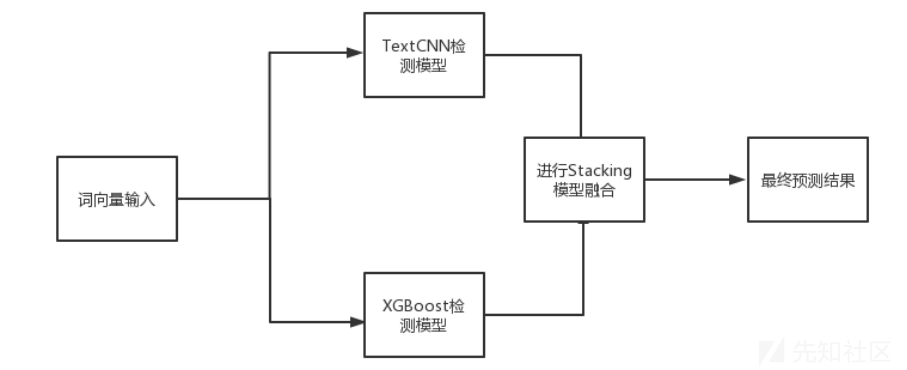
数据集获取
深度学习模型的预测准确度很大程度上依赖于数据集的大小及数据质量。本文在对恶意软件进行检测时选择了其在运行时的行为特征作为主要依据。常见的动态分析过程首先将提取的恶意软件样本进行反编译,必要时进行脱壳处理,接着利用Cuckoo等沙盒工具可以将其运行过程中调用的 API 进程和顺序返回为一份 json 格式的报告,最后将报告中所涉及到的行为特征(API 调用顺序,调用线程编号等)等提取出来后录入到 csv 格式的文件中。一个常见的动态分析流程如下:
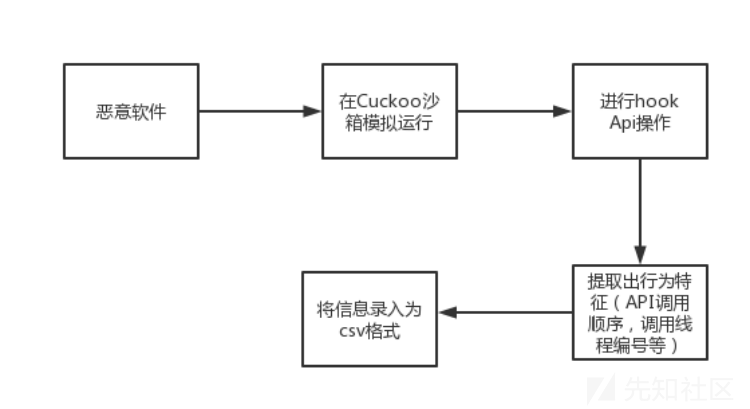
由于互联网上的恶意软件样本大多经过加壳或混淆处理,在提取时很大程度上依赖于技术人员的安全能力,为了扩充数据集样本量以及提高数据可信度,本文选取了阿里云公开恶意代码数据集。该数据集采用了上述提到的动态分析思路,数据为在沙箱仿真运行Windows上的二进制可执行程序后所提取到的API名称、调用API的线程编号、线程中API调用的顺序编号、文件编号以及文件标签。
特征向量化
将恶意软件的行为特征,即其运行时调用的的底层API信息等提取后,利用one-hot编码和word2vec词向量算法的结合,通过将API名称及调用序列映射到向量表示,并使用上下文嵌入技术将API名称的上下文信息嵌入到向量表示中来构造特征工程。为了将文本信息的特征向量化,我们需要首先使用One-Hot编码,主要是因为One-Hot编码用于深度学习处理文本分类的好处有以下几点:
- 降维:文本分类通常需要处理高维输入数据,例如几百维的文本向量。使用One-hot编码可以将高维数据映射到低维向量,从而减少数据的维度,提高模型的效率和准确性。
- 特征表现:One-Hot编码能够以离散类别的形式表现出文字特征,从而使其更好地表现出文字特征。这使得深度学习模型可以更好地捕捉文本特征之间的相关性,从而提高文本分类的准确性。
- 兼容性:One-hot编码可以兼容不同类型的文本特征,例如词袋模型、TF-IDF等。这些特征可以通过One-hot编码被映射到唯一的类别上,从而使得深度学习模型可以更好地处理不同类型的文本特征。
具体到本文中,对于恶意软件调用Api序列,假设有以下三条序列:
API1 API3 API2
API3 API4 API1
API2 API1 API3
先对以上三条API调用序列分词,并获取词典,然后对每个词进行索引编号:
API1:1;API2:2;API3:3;API4:4;
然后可以得到特征词的向量如下:
API1:(1,0,0,0)
API2:(0,1,0,0)
API3:(0,0,1,0)
API4:(0,0,0,1)
最后得到三条序列的特征向量如下:
API1 API3 API2:(1,1,1,0)
API3 API4 API1:(1,0,1,1)
API2 API1 API3:(1,1,1,0)
尽管One-Hot编码具有简单,容易被学习的特点,但是由于One-Hot在每次有新特征添加时,向量长度都会发送改变,特征会升到高维空间,会使得特征维度数太大。而Word2vec算法[18]能够将文本信息数字化,并且能够发现与所选定的中心词类似的词,在本方案中即可以很快发现与恶意软件相似的api调用。结合以上两种算法的优点,本文采用了一种One-Hot编码与Word2vec算法结合的特征向量模型。首先利用One-Hot模型将文本信息转换为One-Hot向量,再将其作为word2vec输入层的输入,通过隐藏层将输入来的One-Hot向量转化为低维度的连续值向量,解决了One-Hot数据离散并且维度巨大的问题。
改进后的特征向量化流程如下:
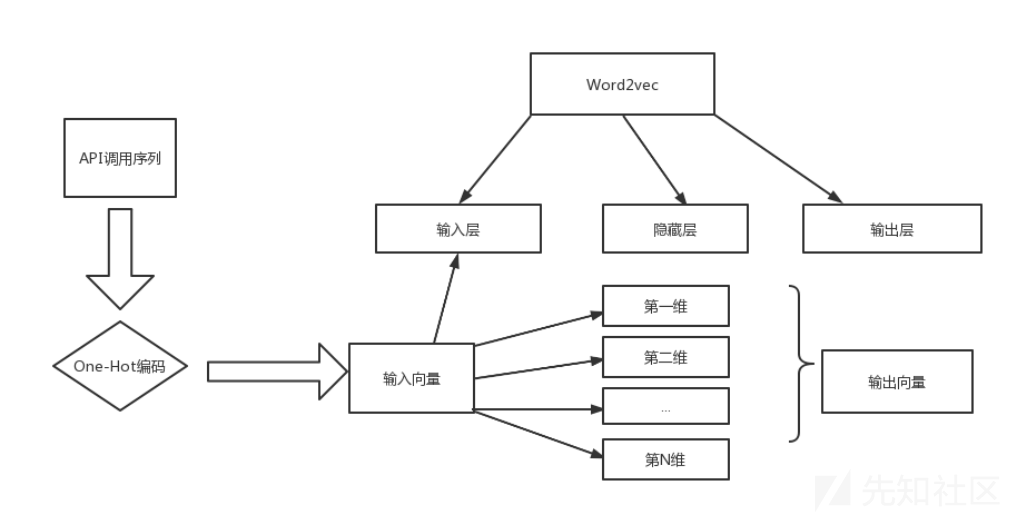
TextCNN检测
TextCNN是文本分类的深度学习模型。它的核心思想是利用卷积神经网络(CNN)对文本特征进行提取,然后使用池化操作将特征向量缩放到一维。下面是TextCNN的各个层:
*输入层:TextCNN的输入是任意长度的文本序列,通常使用词袋模型或TF-IDF等方法对文本进行特征提取。
卷积层:TextCNN的第一个层是卷积层。卷积层是通过一个小尺寸的卷积核在输入序列上运行的,可以提取出这个序列中的局部特征。在TextCNN中,卷积核的大小通常为3x3,步长为1,使用ReLU作为激活函数。
池化层:TextCNN的第二个层是池化层。池化操作可以将特征向量缩放到一维,从而方便进行模型参数的更新。在TextCNN中,常用的池化方式包括最大池化和平均池化两种。
激活函数:TextCNN的第三个层是激活函数。常用的激活函数包括ReLU、sigmoid和tanh等。
全连接层:全连接层将由卷积层和池化层输出的特征转化为一维向量,再由全连接层将其归类为全连接层(full connection)。在TextCNN中,全连接层的神经元数量通常为128或256。
输出层:TextCNN的最后一个层是输出层。通常输出层的神经元数量和数据集的分类数一样,输出向量被映射到各个类别上,使用的是SoftMax函数。
一个可参考的TextCNN网络结构如下:
def TextCNN():
num_filters = 64
kernel_size = [2, 4, 6, 8, 10]
conv_action = 'relu'
_input = Input(shape=(maxlen,), dtype='int32')
_embed = Embedding(304, 256, input_length=maxlen)(_input)
_embed = SpatialDropout1D(0.15)(_embed)
warppers = []
for _kernel_size in kernel_size:
conv1d = Conv1D(filters=32, kernel_size=_kernel_size, activation=conv_action, padding="same")(_embed)
warppers.append(MaxPool1D(2)(conv1d))
fc = concatenate(warppers)
fc = Flatten()(fc)
fc = Dropout(0.5)(fc)
fc = Dense(256, activation='relu')(fc)
fc = Dropout(0.5)(fc)
preds = Dense(8, activation='softmax')(fc)
model = Model(inputs=_input, outputs=preds)
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
return model
以上就是检测基本结构,本文结合恶意软件调用API后具体实现的流程如下:
- 在嵌入层中,将分词后的恶意代码词向量嵌入到低维矢量中,可以提高模型对恶意代码的理解能力,从而提高模型的检测准确率。具体来说,通过将恶意代码词向量映射到低维空间中,可以压缩原始信息,同时保留主要的信息,通过将大量的恶意代码词向量进行嵌入,可以提高模型对恶意软件的识别能力,同时减少模型的计算量和内存占用。
假设n为恶意代码长度,xi代表第i个代码词,则一个恶意代码词向量序列如下:

- 卷积层中,在卷积层中,选取了2,4,6,8,10共5种不同的内核大小,每个卷积层均有 32 个过滤器,通过这种多核融合的方式对恶意代码词向量进行卷积操作来提高模型的分类能力。多核融合可以将恶意代码所含有的不同特征的信息融合起来,从而提高模型的综合性能。卷积操作可以提取输入的恶意代码属性的特征,如API调用顺序,同时通过卷积核的变换,可以识别不同特征。通过多个卷积核的融合,可以进一步提高模型对恶意软件的分类能力31。卷积操作产生新特征的原理如下,其中h代表滑动窗口的长度:
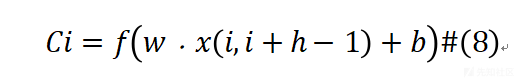
表示从第i行到第i+h-1行的列数为k的矩阵,而w代表权重矩阵,b表示偏离参数,在非线性函数ReLU的作用下,提取出了该窗口下对应的特征向量。最终在多核融合卷积下形成了卷积图。 - 在池化层中,根据提取到的特征,利用early_stopping来解决模型过拟合问题。early_stopping可以在训练过程中随时检查模型的泛化能力,如果模型的泛化能力较差,则停止训练,以避免模型在训练集上训练过度,导致在测试集上表现不佳。此外,池化操作可以缩小模型的输入大小,从而减少模型的过拟合风险。
- 在全连接层中,根据惩罚层的惩罚约定进行反向传播,来更新卷积核参数与本文所用到的恶意代码词向量。惩罚层可以用于优化模型的参数,从而提高模型的检测准确率。具体来说,通过设置惩罚参数,可以让模型更倾向于学习低概率类别,从而提高模型的分类能力。
- 最后,根据SOFTMAX层的输出来归类预测结果,SOFTMAX层可以将输入的向量转换为概率分布,从而将预测结果转化为概率输出。通过SOFTMAX层的输出,可以预测出输入的恶意代码属于哪个类别,从而提高模型的分类能力。此外,使用softmax函数可以将多个类别的概率合并为一个概率分布,从而更准确地预测恶意代码的类别。
XGBoost检测
XGBoost是一种应用梯度提升树算法的分类器。它广泛应用于工业界和学术界,并且在各个数据科学的比赛中被广泛使用。为了最大程度的发挥XGBoost的效果,可以通过网络搜索寻找多个参数的最佳值,如树的最大深度(max_depth)、学习率(eta)、对数据集的采样率(subsample)、对特征的采样率(colsample_bytree)。
在数据预处理方面,由于原始数据是csv格式,太过庞大,所以需要先利用python将其转换为pkl文件以便后续处理,这一过程的代码如下:
def read_test_file(path):
names = []
files = []
data = pd.read_csv(path)
goup_fileid = data.groupby('file_id')
for file_name, file_group in goup_fileid:
print(file_name)
# file_labels = file_group['label'].values[0]
result = file_group.sort_values(['tid', 'index'], ascending=True)
api_sequence = ' '.join(result['api'])
# labels.append(file_labels)
names.append(file_name)
files.append(api_sequence)
print(len(names))
print(len(files))
with open("security_test.csv.pkl", 'wb') as f:
pickle.dump(names, f)
pickle.dump(files, f)
在预处理后,把每个恶意软件样本根据file_id进行分组,在每个分组中把多个线程内部的API CALL(API调用序列)按照调用顺序排好,再把每个线程排好后的序列拼接成一个长字符串。
接下来利用sklearn中的TfidfTransformer统计文本中每个单词或相连词语(n-gram)的TF-IDF权值,以评估词对于一个文档集或一个语料库中的其中一个文档的重要程度:

选择对上文得到的API序列长字符串进行TF-IDF特征抽取,此处考虑到传统的机器学习方法XGBoost在高维稀疏的数据集上表现不如神经网络。选择5-gram,且忽略低于0.9,高于3的文档频率的词条,最后选择高斯映射实现降维。在实际工程中,利用python3中机器学习库sklearn中TfidfVectorizer来实现TF-IDF特征抽取。
Stacking融合
在实际恶意软件检测过程中,目前大多数的机器学习模型以及深度学习模型都存在无法获取到恶意软件的抽象深层次特征的问题,以及耗用资源多,检测时间长的问题。而上文提到的TextCNN模型存在无法很好的保留特征上下文的相关性,可解释性不强,耗时长的缺点,XGBoost模型的特征输入是短距离的n-gram信息和word2vec的整体语义信息,它的优点在于具有比较完整的整体语义信息以及短距离n元组信息的非线性表示,而TextCNN优势是加入了多个长距离n元组中有效性最高的n元组信息,所以我们选择强强联合,将这两个模型融合,来获得更高的检测率、在检测准确率较高条件下相对较短的检测耗时以及模型更强的泛化性。
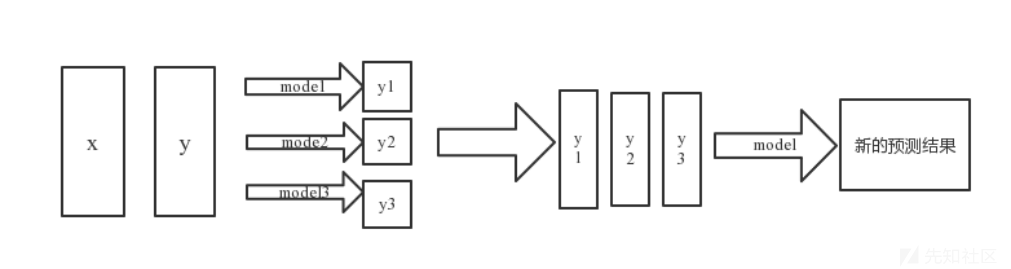
而在模型融合时,我们选择基于Stacking的模型融合方法,Stacking就是通过模型对原数据拟合的堆叠进行建模,首先通过基学习器学习原数据,然后这几个基学习器都会对原数据进行预测并输出,然后将这几个模型的输出进行堆叠,构成了(m,p)维的新数据,m代表样本数,p代表基学习器的个数,最后再将新的样本数据交给第二层模型进行拟合。原理如下图所示:
在实际工程中,模型融合的代码实现可以参考下方示例:
train = np.hstack([tfidf_train_result, textcnn_train_result])
test = np.hstack( [tfidf_out_result, textcnn_out_result])
meta_test = np.zeros(shape=(len(outfiles), 8))
skf = StratifiedKFold(n_splits=5, random_state=4, shuffle=True)
dout = xgb.DMatrix(test)
for i, (tr_ind, te_ind) in enumerate(skf.split(train, labels)):
print('FOLD: {}'.format(str(i)))
X_train, X_train_label = train[tr_ind], labels[tr_ind]
X_val, X_val_label = train[te_ind], labels[te_ind]
dtrain = xgb.DMatrix(X_train, label=X_train_label)
dtest = xgb.DMatrix(X_val, X_val_label)
param = {'max_depth': 6, 'eta': 0.01, 'eval_metric': 'mlogloss', 'silent': 1, 'objective': 'multi:softprob',
'num_class': 8, 'subsample': 0.9,
'colsample_bytree': 0.85} # 参数
evallist = [(dtrain, 'train'), (dtest, 'val')] # 测试 , (dtrain, 'train')
num_round = 10000 # 循环次数
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=100)
preds = bst.predict(dout)
meta_test += preds
本文所提出的基于模型融合的恶意软件检测模型,可以较好的结合TextCNN模型检测准确率高与XGBoost检测速度快的优点。但同时本文还是存在很多不足的地方需要进一步研究,主要有以下几点:
1.本文只进行了TextCNN与XGBoost模型的融合。考虑到恶意软件检测领域还有很多表现优异的模型,如果将更多个模型融合,同时选取更多的模型优化算法进行研究,可以使得模型性能更好。
2.本文只针对windows系统上的二进制可执行文件进行了分析,没有针对移动端或是Linux系统等进行分析,系统的可移植性不高。
3.深度学习过程中没有对数据集中可能出现的异常输入检测,框架鲁棒性不强。
4.本文借鉴了自然语言处理的思路。深度学习技术同样可以应用于图像处理,可以考虑将恶意软件特征转换为灰度图像后,利用深度学习模型进行处理。
本文实验数据选取了阿里云公开恶意软件数据集(csv 格式)。所涉及到的样本均为阿里云在沙箱仿真运行 Windows 上的二进制可执行程序后所提取到的 API 序列,经过脱敏处理后数据总计有 6 亿条。且涉及到了恶意软件中常见的感染型病毒、木马软件、挖矿程序、DDOS 木马、勒索病毒、蠕虫病毒、后门软件。
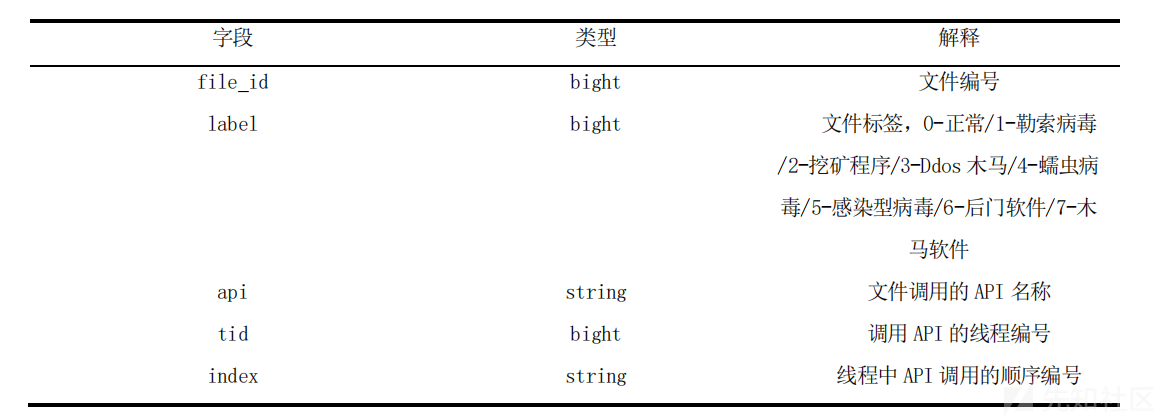
数据表中数据属性如图:
 转载
转载
 分享
分享

没有评论