
一.基础概念
LLVM最初是Low Level Virtual Machine的缩写,定位是一个比较底层的虚拟机。但是LLVM本身并不是一个完整的编译器,LLVM是一个编译器基础架构(infrastructure,把很多编译器需要的功能以可调用的模块形式实现出来并包装成库,供其他编译器实现者可以根据自己的需要选择使用或者扩展。主要聚焦于编译器后端功能,如代码生成、代码优化、JIT等。
目前常见的编译器都分为了三个部分,前端(Frontend),优化层(Optimizeation)以及后端(Backend),每一部分都承担了不同的功能:
- 前端:负责将高级源语言代码转换为 LLVM 的中间表示(IR),为后续的编译阶段打下基础。
- 优化层:对生成的中间表示 IR 进行深入分析和优化,提升代码的性能和效率。
- 后端:将优化后的中间表示 IR 转换成目标机器的特定语言,确保代码能够在特定硬件上高效运行。
这种分层的方法不仅提高了编译过程的模块化,还使得编译器能够更灵活地适应不同的编程语言和目标平台。同理,LLVM 也是按照这一结构设计进行架构设计:
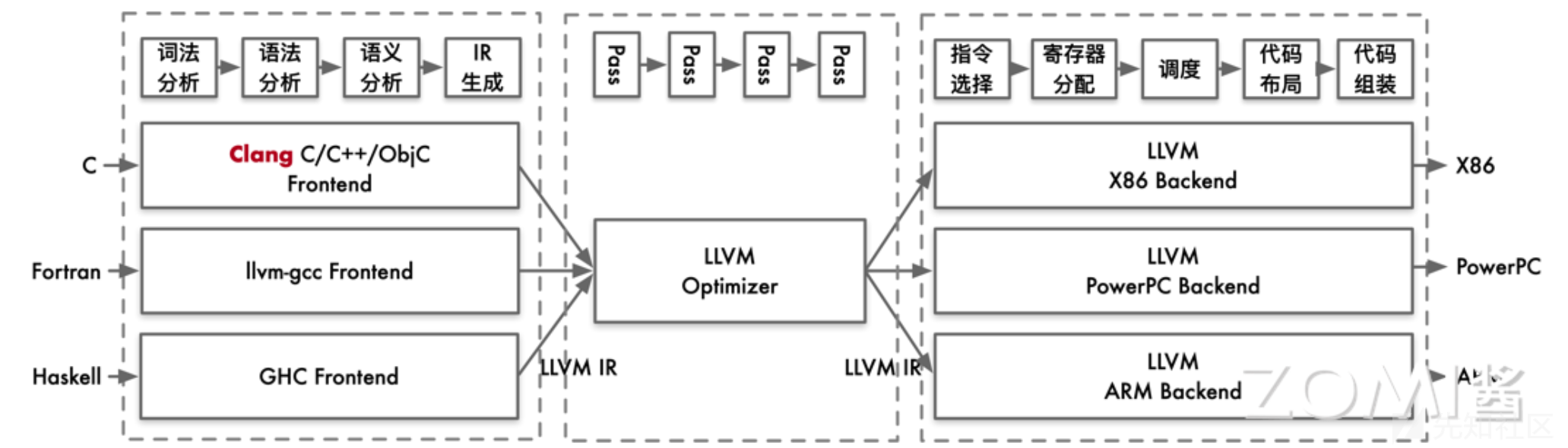
二.环境配置
可以参考llvm官方文档https://llvm.gnu.ac.cn/docs/
首先先下载llvm的源码,这里用的是llvm 18.1.8 (使用新版pass manager,与旧版差别比较大,可以参考官方文档说的,即:与旧版 Pass 管理器下的 Pass 不同,旧版 Pass 管理器通过继承定义 Pass 接口,新 Pass 管理器下的 Pass 依赖于基于概念的多态性,这意味着没有显式接口(有关更多详细信息,请参阅 PassManager.h 中的注释)。所有 LLVM Pass 都继承自 CRTP 混合类 PassInfoMixin<PassT>。Pass 应该有一个 run() 方法,该方法返回一个 PreservedAnalyses 并接收一些 IR 单元以及一个分析管理器。例如,函数 Pass 将具有 PreservedAnalyses run(Function &F, FunctionAnalysisManager &AM); 方法),在github上下载源码,解压到虚拟机上
即source code

然后根据文档要求下载对应环境并进行编译
sudo apt-get install g++
sudo apt-get install make
sudo apt-get install cmake
sudo apt install ninja-build
cd llvm-project
sudo cmake -S llvm -B build -G Ninja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_PROJECTS="clang"
cd build
ninja -j8然后把源码导入clion并进行编译
找到llvm目录下的CMakeLists.txt打开
然后设置编译参数
进入settings,然后CMake里点击+会添加Release版本,我们需要在CMake options里填上我们之前编译时用的命令
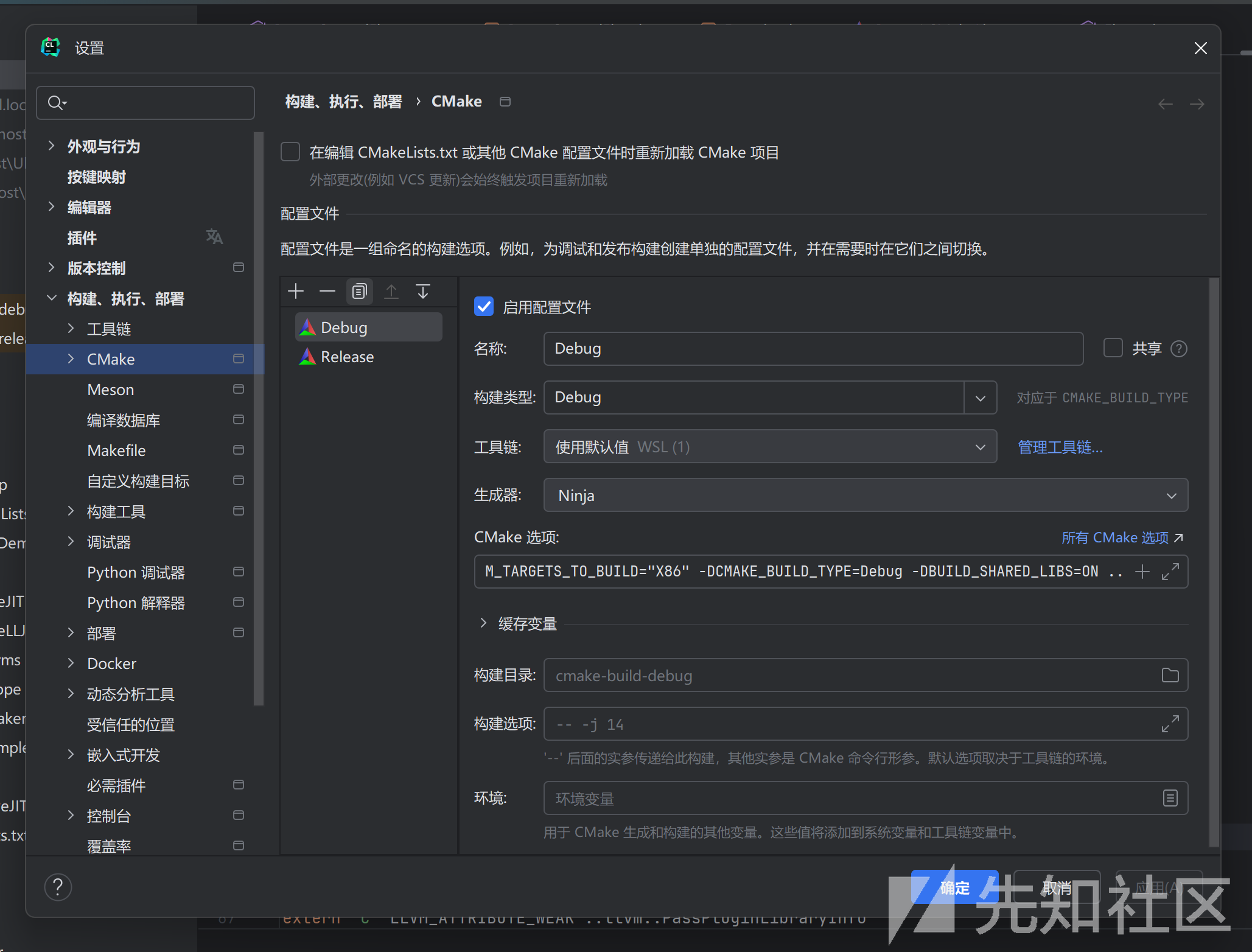
-G Ninja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_PROJECTS="clang" -DBUILD_SHARED_LIBS=ON发现会多出cmake -build-release和cmake-build-debug两个目录
然后直接进入release目录ninja -6,因为clion自己编译很慢
三.正式开始
首先入门可以查看官方文档,根据官方文档进行llvm pass的编写(因为现存的关于新版管理器的资料比较少,并没有旧版那么多且新版对管道进行了优化,在此我们参考官方文档)
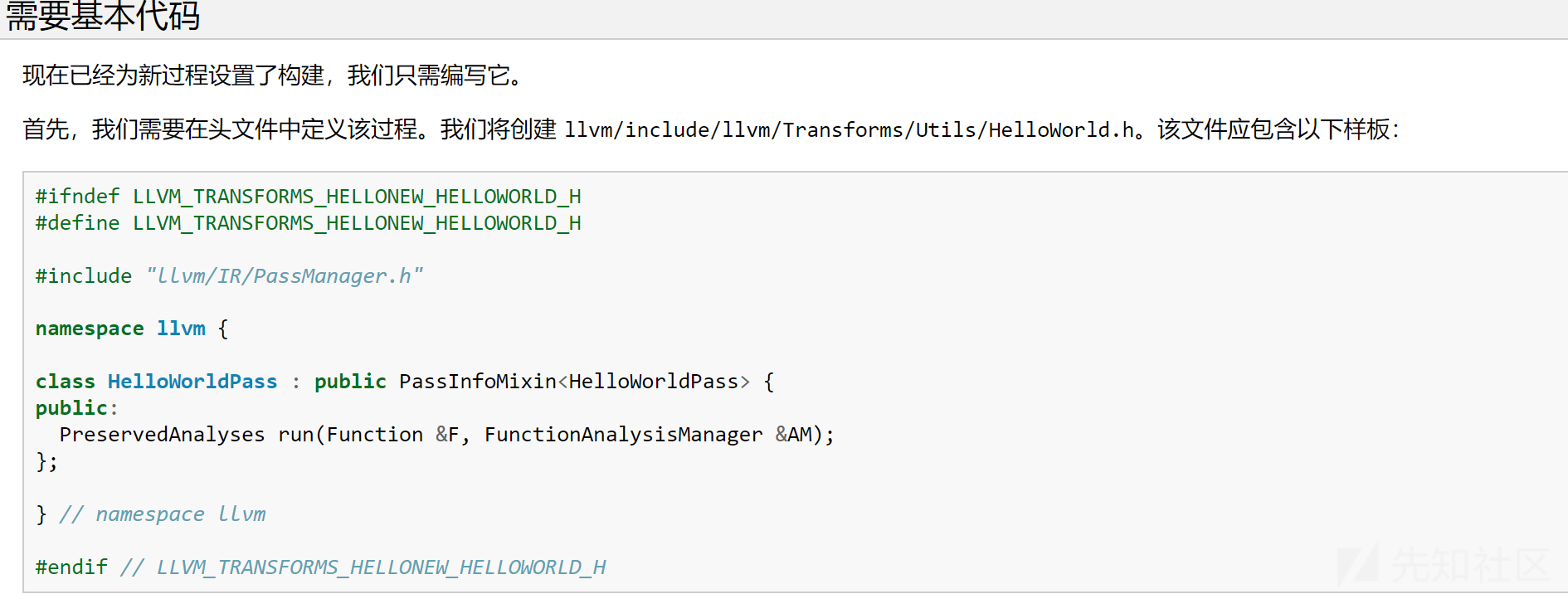
可以发现其实官方文档所写的helloworld.h已经被创建了,那么我们根据他再在该文件夹中创建一个encode.h
写出如下代码:
#ifndef LLVM_TRANSFORMS_UTILS_ENCODE_H
#define LLVM_TRANSFORMS_UTILS_ENCODE_H
#include "llvm/IR/PassManager.h"
namespace llvm {
class EncodePass : public PassInfoMixin<EncodePass> {
public:
PreservedAnalyses run(Function &F, FunctionAnalysisManager &AM);
};
} // namespace llvm
#endif // LLVM_TRANSFORMS_UTILS_ENCODE_H
这段代码写完可能会有run标红,不用管,否则编译opt的时候会报错
然后再在llvm/lib/Transforms/Utils中创建Encode.cpp,代码如下
#include "llvm/Transforms/Utils/Encode.h"
using namespace llvm;
PreservedAnalyses EncodePass::run(Function &F,
FunctionAnalysisManager &AM) {
errs() << F.getName() << "\n";
return PreservedAnalyses::all();
}
然后在llvm/lib/Transforms/Utils的Cmakelists.txt中添加一个Encode.cpp
写完后在llvm/lib/Passes/PassRegistry.def中添加如下
FUNCTION_PASS("encode",EncodePass())在llvm/lib/Passes/PassBuilder.cpp添加
#include "llvm/Transforms/Utils/Encode.h"然后在clion中重新编译
选择重新加载cmake项目
然后进入cmake-build-release文件夹重新编译
ninja -j2 opt不过编译过程中我莫名其妙跳出来一个循环依赖问题

不过解决也很容易,只要在clion中进入lib/support/BLAKE3/里面的cmakelists.txt,把最后一行和Encode.cpp有关的内容删除即可(虽然我还不知道有什么影响,不过好像没什么影响)
后来发现出现循环的原因是clion中新建.cpp文件的时候会有一个添加到目标,默认值就是lib/support/BLAKE3/
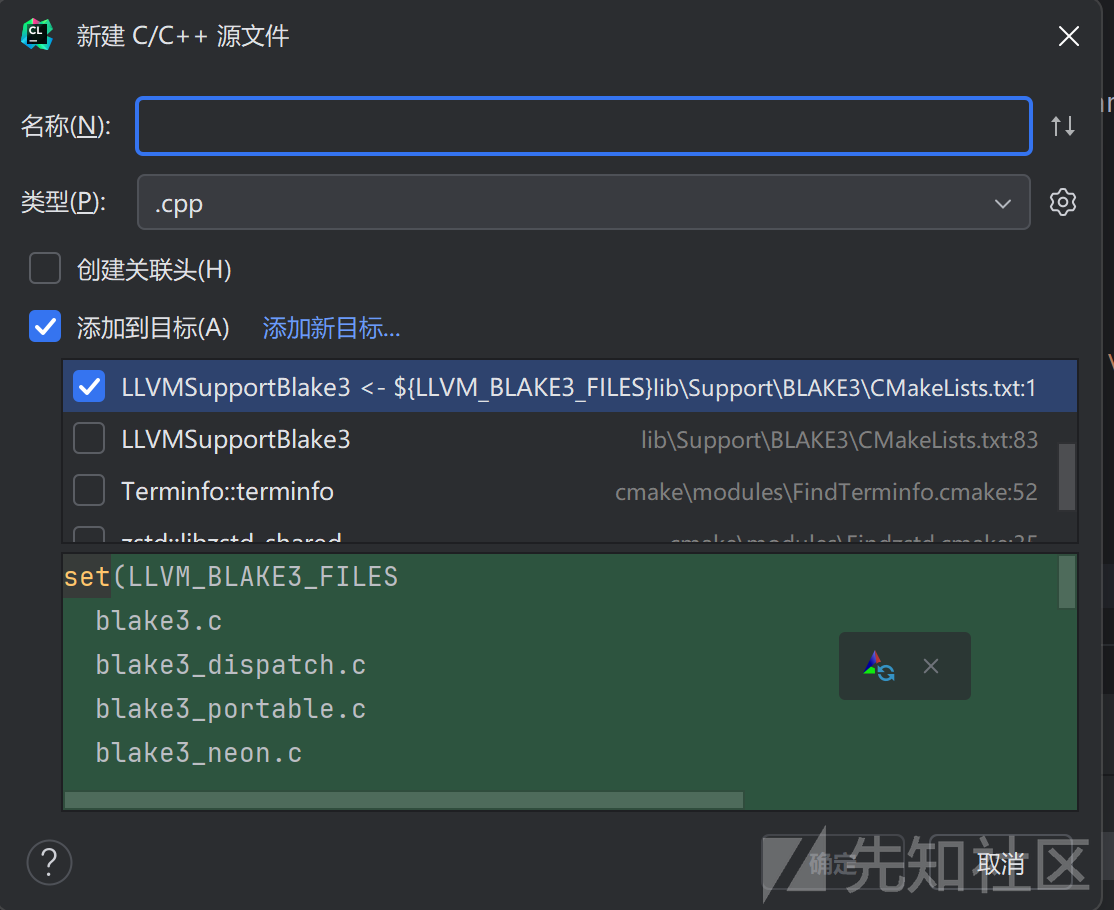
正好是出现循环依赖中的一环(只探究到这里了,再深还没有什么发现)
然后编译完成就可以使用opt将pass用于我们的IR代码上啦
四.使用pass
先浅浅的写一个c语言的代码,创建成hello_clang.c
#include<stdio.h>
void test_hello1(){
printf("test_hello1\n");
return ;
}
void test_hello2(){
printf("test_hello2\n");
return ;
}
int main(int argc ,char const *argv[]){
printf("hello clang\n");
return 0;
}
比如这样子,然后用clang进行编译,命令如下
clang -O3 -emit-llvm hello_clang.c -S -o hello_clang.ll注意这个-O3一定要加上,它对.ll文件进行了优化,如果不加上,面临的就是
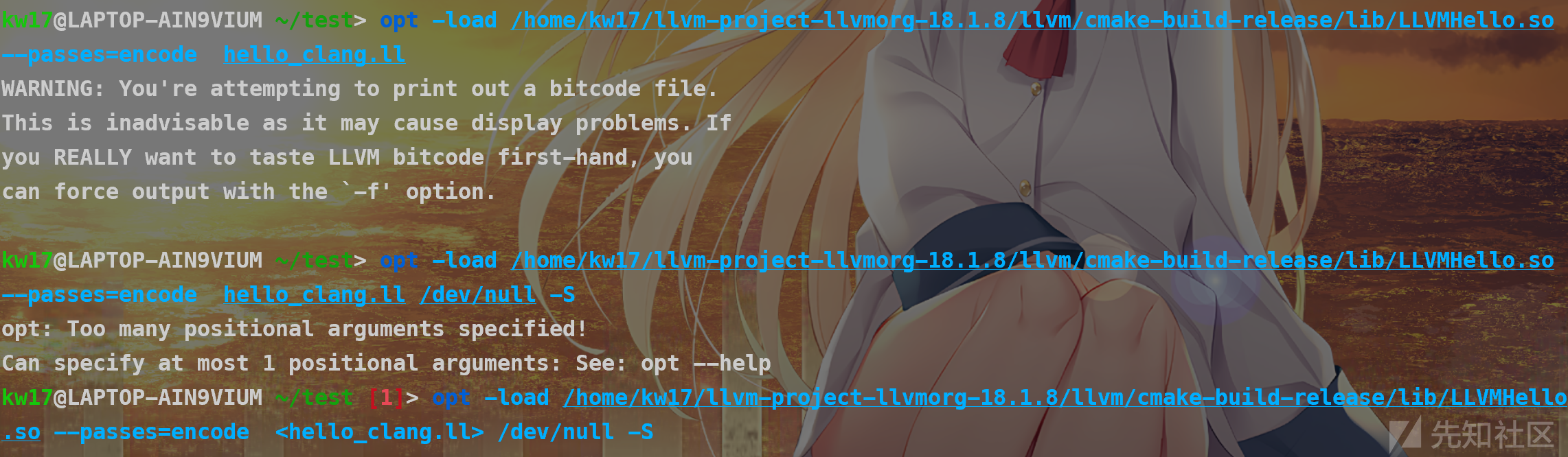
就是不管怎么样你编译出来的东西都没有办法被可爱的F.getname()识别,不管怎么样都抓耳挠腮但是官方给的.ll却可以正常运行让你怀疑你是不是有问题
总之当时被困了蛮久的,后来是在知乎上的某篇文章启发了我
然后后面就是正常的啦
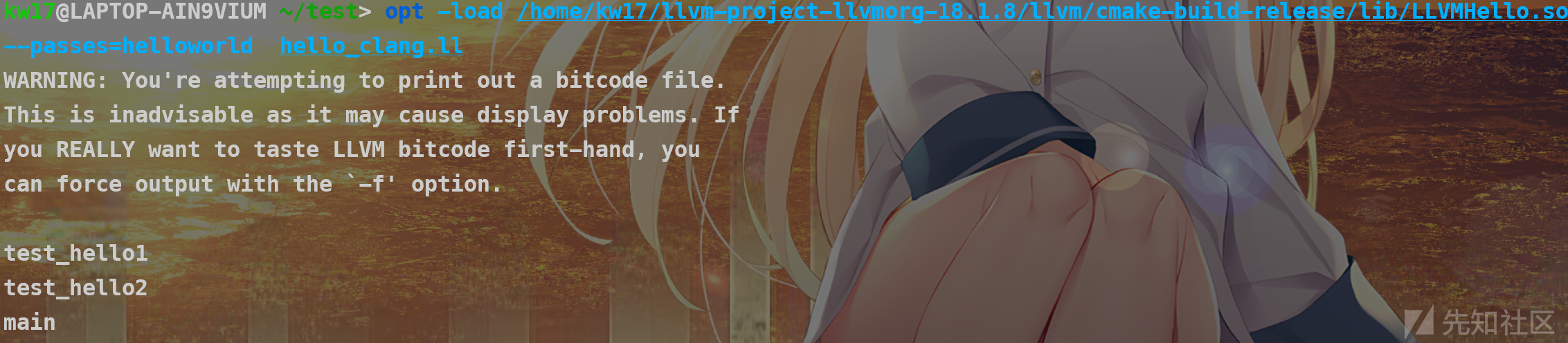
用了两种方式去运行了pass,一种是官方文档描述的

还有一种是老版的就是搞个.so文件(不过说实话感觉有点没有必要)
总结
llvm pass是很好用的作用于中间层IR的一种工具,ollvm也正是应用了这种性质实现各种操作,比如使用分发器实现控制流平坦化以及虚假控制流,对程序实现混淆或者提取IR中的信息,比起自己写一个脚本或者插件,基于llvm框架的项目显然更容易实现,因为它本身也规定了程序调用的某些api。
 转载
转载
 分享
分享

