
STEM CTF Cyber Challenge 2019的一道400分的逆向题,做题过程中学到了很多以前忽略的小知识点,以下是详细复现记录
REbase-fix
简单交互
先file一下,发现是x86-64的elf
➜ Desktop file REbase-fix
REbase-fix: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux), statically linked, stripped
IDA打开后发现没有main函数,应该是加了壳
strings后发现,最后两行有UPX!的字符串
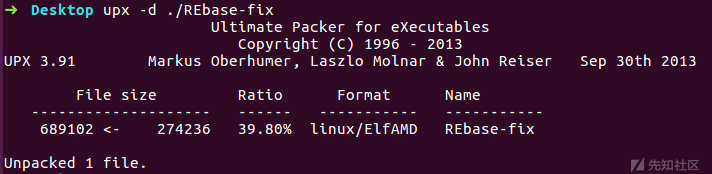
大概率是upx壳,于是直接upx -d脱壳后扔IDA分析
不过还是找不到main,应该是做了去符号的处理
和程序交互,先找找有没有字符串
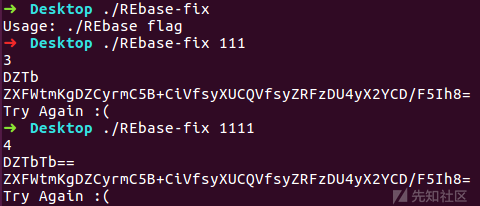
程序接收一个命令行参数,看起来像是进行了base64编码,要求相等
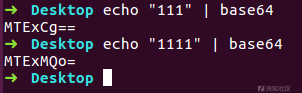
输出111和1111的base64编码值比较,发现并不相等
题目名字是REbase-fix,猜测意思是修复base系列编码
通过这两个测试字符串111和1111,可以发现,程序输出的DZTb就相当于标准base64的MTEx
应该是可以手动测试自己探测出程序的base表,但是既然这里看到了Try Again :(,在IDA中搜索一下
跟着交叉引用,F5后发现关键代码
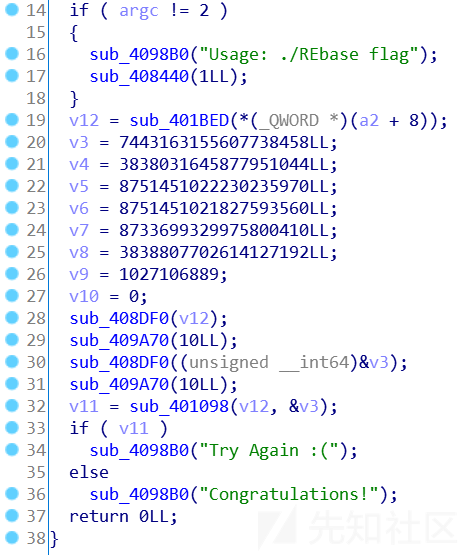
但是发现,即是根据功能猜测sub_4098B0是输出函数,点进去也会看到一堆复杂的代码 ......
又想到既然是base64的魔改,那程序中应该会有base码表
但是字符串窗口中里有太多字符串了,因为能找到Try Again :(",暂且认为字符串没有加密,但是也不能精准的找到关键的码表
这时感觉没有突破口了
尝试angr
尝试写一个angr脚本
import angr
import claripy
proj = angr.Project("./REbase-fix",auto_load_libs=False)
argv1 = claripy.BVS('argv1',50*8)
state = proj.factory.entry_state(args=["./REbase-fix",argv1])
simgr = proj.factory.simgr(state)
simgr.explore(find = 0x402070,avoid = 0x402084)
由于是命令行参数,用到这个claripy库,但是跑了两个多小时也没跑出来
我感觉爆破base64编码应该用不到这么久吧,毕竟没有多二进制码进行过多操作,可能是程序里有暗桩
查找码表
于是这条路又走不通了,参考一下其他大佬的writeup
发现一条命令strings REbase-fix | grep -x '.\{30,\}' | head
用来搜索长度大于等于30的字符串
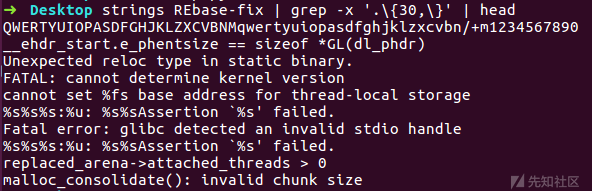
学到了...用strings配合正则表达式
看上去是滚键盘得到的字符串,长度也正好,看起来就是base的码表了
魔改base64解码
现在只要找一个base64的实现,把码表改成我们自己的就可以了
我用的cpp实现,但是代码太长,找了一个好用的python实现
import re
def base64_encode(s, dictionary):
r = ""
p = ""
c = len(s) % 3
if (c > 0):
for i in range(c, 3):
p += '='
s += "\0"
for c in range(0, len(s), 3):
n = (ord(s[c]) << 16) + (ord(s[c+1]) << 8) + (ord(s[c+2]))
n = [(n >> 18) & 0x3F, (n >> 12) & 0x3F, (n >> 6) & 0x3F, n & 0x3F]
r += dictionary[n[0]] + dictionary[n[1]] + dictionary[n[2]] + dictionary[n[3]]
return r[0:len(r) - len(p)] + p
def base64_decode(s, dictionary):
base64inv = {}
for i in range(len(dictionary)):
base64inv[dictionary[i]] = i
s = s.replace("\n", "")
if not re.match(r"^([{alphabet}]{{4}})*([{alphabet}]{{3}}=|[{alphabet}]{{2}}==)?$".format(alphabet = dictionary), s):
raise ValueError("Invalid input: {}".format(s))
if len(s) == 0:
return ""
p = "" if (s[-1] != "=") else "AA" if (len(s) > 1 and s[-2] == "=") else "A"
r = ""
s = s[0:len(s) - len(p)] + p
for c in range(0, len(s), 4):
n = (base64inv[s[c]] << 18) + (base64inv[s[c+1]] << 12) + (base64inv[s[c+2]] << 6) + base64inv[s[c+3]]
r += chr((n >> 16) & 255) + chr((n >> 8) & 255) + chr(n & 255)
return r[0:len(r) - len(p)]
def test_base64():
import base64
import string
import random
dictionary = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
def random_string(length):
return ''.join(random.choice(string.ascii_letters) for m in range(length))
for i in range(100):
s = random_string(i)
encoded = base64_encode(s, dictionary)
assert(encoded == base64.b64encode(s))
assert(s == base64_decode(encoded, dictionary))
if __name__ == "__main__":
dictionary = "QWERTYUIOPASDFGHJKLZXCVBNMqwertyuiopasdfghjklzxcvbn/+m1234567890"
print(base64_decode("ZXFWtmKgDZCyrmC5B+CiVfsyXUCQVfsyZRFzDU4yX2YCD/F5Ih8=", dictionary), end='')
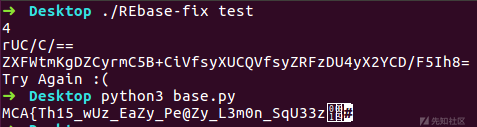
把这段丢给程序,发现输出有乱码,而且因为flag格式是MCA{},也没有预期的}
丢给程序发现还差了一点
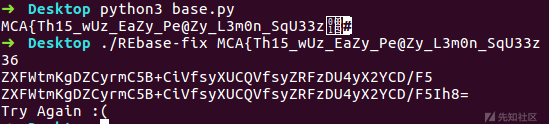
因为最后一个字符是},于是手动测几个

看上去}之前的字符不管是什么都会输出Congratulations!,不符合常理,字符串编码后应该是一对一的
但是由于是赛后复现,无法和服务器交互,其他writeup上说服务器只接受
{Th15_wUz_EaZy_Pe@Zy_L3m0n_SqU33zy}
最后的思考
linux下的命令,例如strings和grep配合管道符的使用需要多加练习,在CTF中很可能可以作为突破口
 转载
转载
 分享
分享


