
前言
挺久没有沉下心来好好的去研究分析一个自认为有意思的东西
解析流程
请求路径
/webshell.jsp/123.txt调用栈
buildInvocation:4175, WebApp (com.caucho.server.webapp)
buildInvocation:798, WebAppContainer (com.caucho.server.webapp)
buildInvocation:753, Host (com.caucho.server.host)
buildInvocation:319, HostContainer (com.caucho.server.host)
buildInvocation:1068, ServletService (com.caucho.server.cluster)
buildInvocation:250, InvocationServer (com.caucho.server.dispatch)
buildInvocation:223, InvocationServer (com.caucho.server.dispatch)
buildInvocation:1610, AbstractHttpRequest (com.caucho.server.http)
getInvocation:1583, AbstractHttpRequest (com.caucho.server.http)
handleRequest:825, HttpRequest (com.caucho.server.http)
dispatchRequest:1393, TcpSocketLink (com.caucho.network.listen)
handleRequest:1349, TcpSocketLink (com.caucho.network.listen)
handleRequestsImpl:1333, TcpSocketLink (com.caucho.network.listen)
handleRequests:1241, TcpSocketLink (com.caucho.network.listen)
调试解析流程来到
com.caucho.server.webapp.WebApp#buildInvocation(com.caucho.server.dispatch.Invocation, boolean)//...
if (isCache) {
entry = (FilterChainEntry)this._filterChainCache.get(((Invocation)invocation).getContextURI());
}
FilterChain chain;
if (entry != null && !entry.isModified()) {
//...
}
} else {
chain = this._servletMapper.mapServlet((ServletInvocation)invocation);
this._filterMapper.buildDispatchChain((Invocation)invocation, chain);
chain = ((Invocation)invocation).getFilterChain();
chain = this.applyWelcomeFile(DispatcherType.REQUEST, (Invocation)invocation, chain);
if (this._requestRewriteDispatch != null) {
FilterChain newChain = this._requestRewriteDispatch.map(DispatcherType.REQUEST, ((Invocation)invocation).getContextURI(), ((Invocation)invocation).getQueryString(), chain);
chain = newChain;
}
entry = new FilterChainEntry(chain, (Invocation)invocation);
chain = entry.getFilterChain();
if (isCache) {
this._filterChainCache.put(((Invocation)invocation).getContextURI(), entry);
}
}
chain = this.buildSecurity(chain, (Invocation)invocation);
chain = this.createWebAppFilterChain(chain, (Invocation)invocation, isTop);
((Invocation)invocation).setFilterChain(chain);
((Invocation)invocation).setPathInfo(entry.getPathInfo());
((Invocation)invocation).setServletPath(entry.getServletPath());
if (this._oldWebApp != null && CurrentTime.getCurrentTime() < this._oldWebAppExpireTime) {
Invocation oldInvocation = new Invocation();
oldInvocation.copyFrom((Invocation)invocation);
oldInvocation.setWebApp(this._oldWebApp);
this._oldWebApp.buildInvocation(oldInvocation);
invocation = new VersionInvocation((Invocation)invocation, this, oldInvocation, oldInvocation.getWebApp(), this._oldWebAppExpireTime);
}
var26 = invocation;
return (Invocation)var26;
}
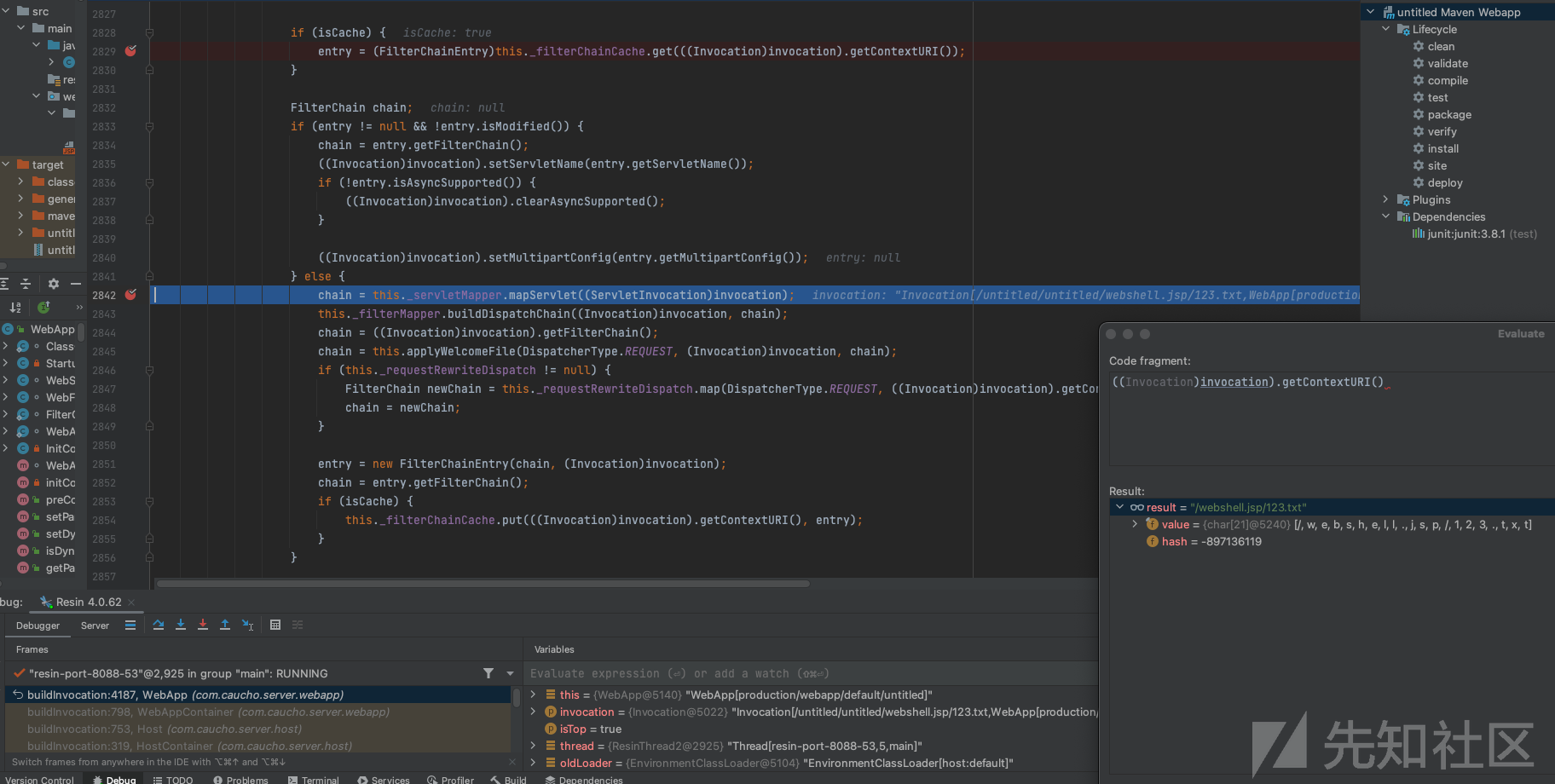
从_filterChainCache通过请求路径获取缓存的FilterChainEntry实体类,缓存中获取不到的话会调用this._servletMapper.mapServlet来进行获取

entry._regexp.matcher(uri);通过URI去匹配规则,因为^.*\.jsp(?=/)|^.*\.jsp\z该正则的缘故,所以这里能将xxx.jsp/123.xxx给匹配为xxx.jsp

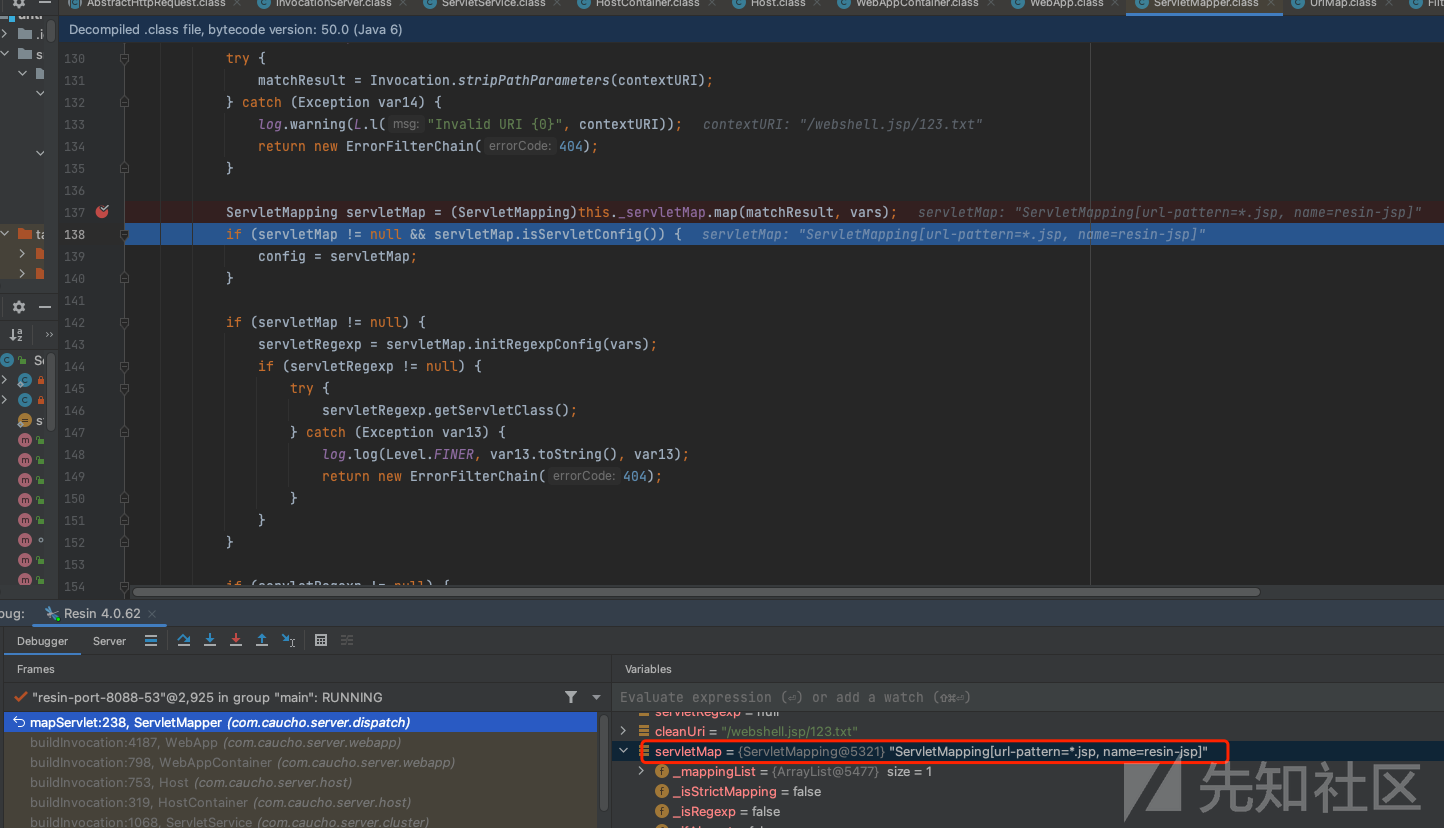
请求走了ServletMapping[url-pattern=*.jsp, name=resin-jsp]的处理机制

com.caucho.server.dispatch.ServletMapper#mapServlet下面代码这里会创建chain

创建完成后,到com.caucho.server.http.HttpRequest#handleRequest调用invocation.service
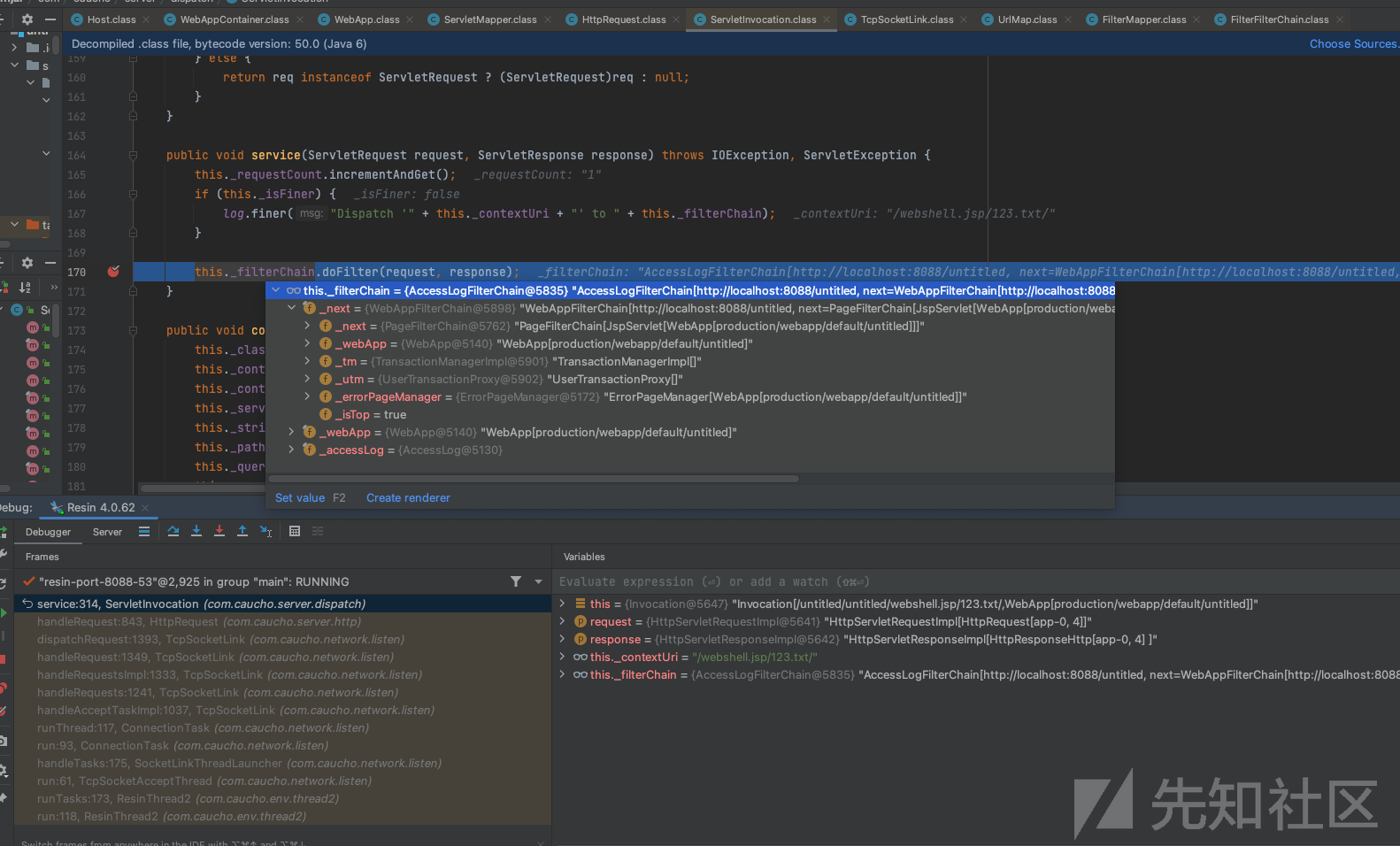
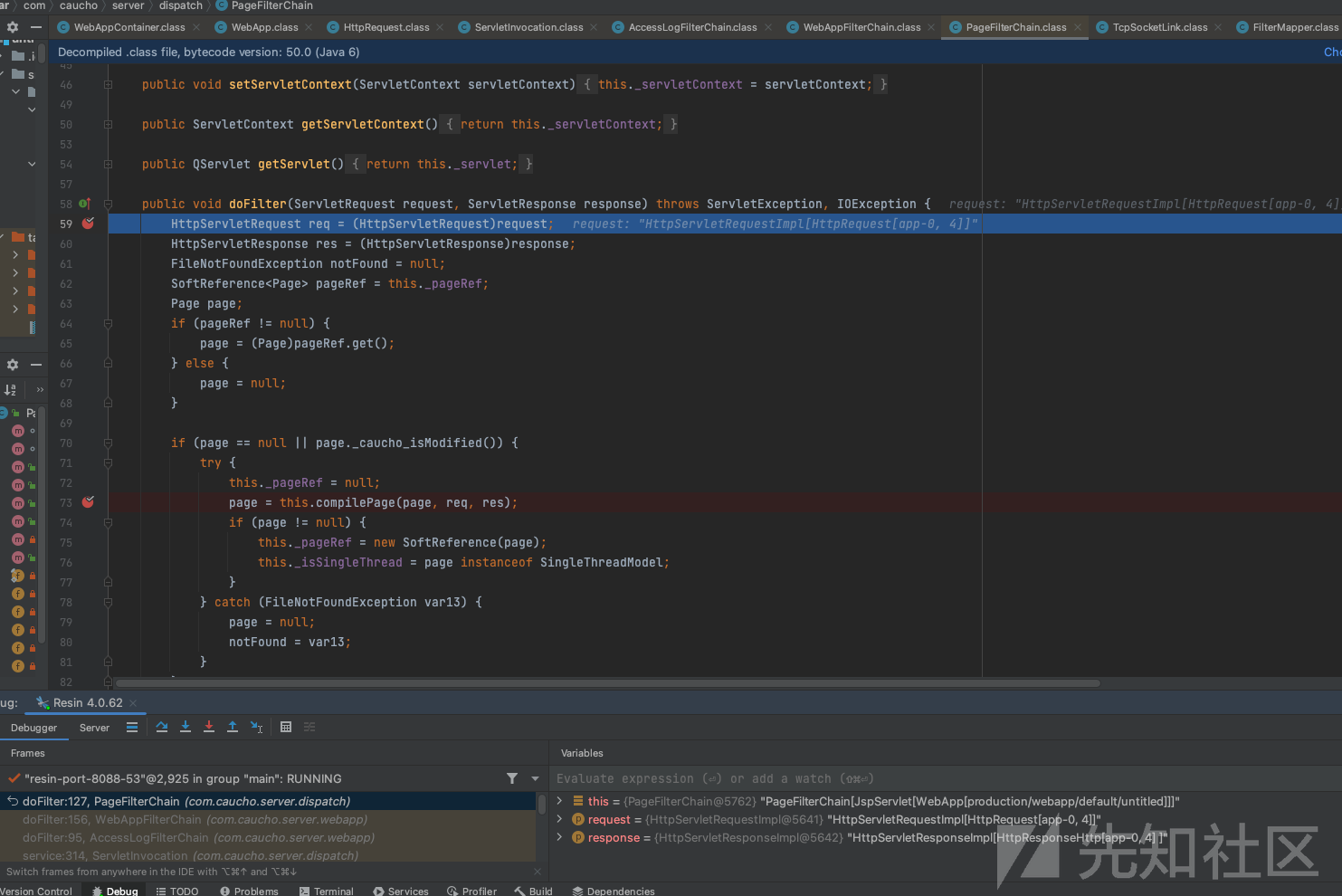
执行filterChain走到com.caucho.server.dispatch.PageFilterChain#doFilter进行jsp page的处理。
解析PHP
在/conf/app-default.xml文件中有这么一项,php后缀文件使用com.caucho.quercus.servlet.QuercusServlet来解析

使用默认的resin配置是会将这条规则进行加载的


QuercusServlet会调用Quercus来解析PHP
resin官方说明文档:http://quercus.caucho.com/
路径解析特性
escape编码解析
调用栈
splitQueryAndUnescape:254, InvocationDecoder (com.caucho.server.dispatch)
buildInvocation:1594, AbstractHttpRequest (com.caucho.server.http)
getInvocation:1583, AbstractHttpRequest (com.caucho.server.http)
handleRequest:825, HttpRequest (com.caucho.server.http)
com.caucho.server.dispatch.InvocationDecoder#splitQueryAndUnescape调用normalizeUriEscape进行解码
com.caucho.server.dispatch.InvocationDecoder#splitQueryAndUnescape代码
public void splitQueryAndUnescape(Invocation invocation, byte[] rawURI, int uriLength) throws IOException {
String decodedURI;
for(int i = 0; i < uriLength; ++i) {
if (rawURI[i] == 63) {
++i;
decodedURI = this.byteToChar(rawURI, i, uriLength - i, "ISO-8859-1");
invocation.setQueryString(decodedURI);
uriLength = i - 1;
break;
}
}
String rawURIString = this.byteToChar(rawURI, 0, uriLength, "ISO-8859-1");
invocation.setRawURI(rawURIString);
decodedURI = normalizeUriEscape(rawURI, 0, uriLength, this._encoding);
//...
String uri = this.normalizeUri(decodedURI);
invocation.setURI(uri);
invocation.setContextURI(uri);
com.caucho.server.dispatch.InvocationDecoder#normalizeUriEscape代码
private static String normalizeUriEscape(byte[] rawUri, int i, int len, String encoding) throws IOException {
//...
try {
while(i < len) {
int ch = rawUri[i++] & 255;
if (ch == 37) {
i = scanUriEscape(converter, rawUri, i, len);
} else {
converter.addByte(ch);
}
}
String result = converter.getConvertedString();
freeConverter(converter);
return result;
}
循环遍历路径每个字符匹配%字符,匹配到则调用scanUriEscape
private static int scanUriEscape(ByteToChar converter, byte[] rawUri, int i, int len) throws IOException {
int ch1 = i < len ? rawUri[i++] & 255 : -1;
int ch2;
int ch3;
if (ch1 == 117) {
ch1 = i < len ? rawUri[i++] & 255 : -1;
ch2 = i < len ? rawUri[i++] & 255 : -1;
ch3 = i < len ? rawUri[i++] & 255 : -1;
int ch4 = i < len ? rawUri[i++] & 255 : -1;
converter.addChar((char)((toHex(ch1) << 12) + (toHex(ch2) << 8) + (toHex(ch3) << 4) + toHex(ch4)));
} else {
ch2 = i < len ? rawUri[i++] & 255 : -1;
ch3 = (toHex(ch1) << 4) + toHex(ch2);
converter.addByte(ch3);
}
return i;
}
scanUriEscape该方法遍历每个字符,取四个字符进行Escape解码,如%u0077后后四位数。
请求路径:
http://localhost:8088/untitled/%u0077%u0065%u0062%u0073%u0068%u0065%u006c%u006c%u002e%u006a%u0073%u0070%u002f%u0031%u0032%u0033%u002e%u0074%u0078%u0074;
解码后为:/untitled/webshell.jsp/123.txt
编码规范
注意到在com.caucho.server.dispatch.InvocationDecoder#splitQueryAndUnescape中调用完normalizeUriEscape对URI进行解码后,还会调用com.caucho.server.dispatch.InvocationDecoder#normalizeUri(java.lang.String)对URI进行规范化处理。
public String normalizeUri(String uri, boolean isWindows) throws IOException {
CharBuffer cb = new CharBuffer();
int len = uri.length();
if (this._maxURILength < len) {
throw new BadRequestException(L.l("The request contains an illegal URL because it is too long."));
} else {
char ch;
if (len == 0 || (ch = uri.charAt(0)) != '/' && ch != '\\') {
cb.append('/');
}
for(int i = 0; i < len; ++i) {
ch = uri.charAt(i);
if (ch != '/' && ch != '\\') {
if (ch == 0) {
throw new BadRequestException(L.l("The request contains an illegal URL."));
}
cb.append(ch);
} else {
while(i + 1 < len) {
ch = uri.charAt(i + 1);
if (ch != '/' && ch != '\\') {
if (ch == ';') {
throw new BadRequestException(L.l("The request contains an illegal URL."));
}
if (ch != '.') {
break;
}
if (len > i + 2 && (ch = uri.charAt(i + 2)) != '/' && ch != '\\') {
if (ch == ';') {
throw new BadRequestException(L.l("The request contains an illegal URL."));
}
if (ch != '.') {
break;
}
if (len > i + 3 && (ch = uri.charAt(i + 3)) != '/' && ch != '\\') {
throw new BadRequestException(L.l("The request contains an illegal URL."));
}
int j;
for(j = cb.length() - 1; j >= 0 && (ch = cb.charAt(j)) != '/' && ch != '\\'; --j) {
}
if (j > 0) {
cb.setLength(j);
} else {
cb.setLength(0);
}
i += 3;
} else {
i += 2;
}
} else {
++i;
}
}
while(isWindows && cb.getLength() > 0 && ((ch = cb.getLastChar()) == '.' || ch == ' ')) {
cb.setLength(cb.getLength() - 1);
if (cb.getLength() > 0 && (ch = cb.getLastChar()) == '/' || ch == '\\') {
cb.setLength(cb.getLength() - 1);
}
}
cb.append('/');
}
}
while(isWindows && cb.getLength() > 0 && ((ch = cb.getLastChar()) == '.' || ch == ' ')) {
cb.setLength(cb.getLength() - 1);
}
return cb.toString();
}
}
遍历字符,如果不为/则持续向cb中添加字符,如果为/则遍历/后面的字符为;则报错。为.则退出循环,但是这个.并不会添加到cb中。当出现/.字符的时候会检测后面第三位数是否是.或者第四位是不是.如果是的话则跳出循环,该第三或第四个字符后面的字符不为/的话则抛异常。也就是说说当出现了/.后,检测一下一个字符,如果还是.会出循环再检测下面的字符,下面的字符必须得是/,只能以/../的方式请求
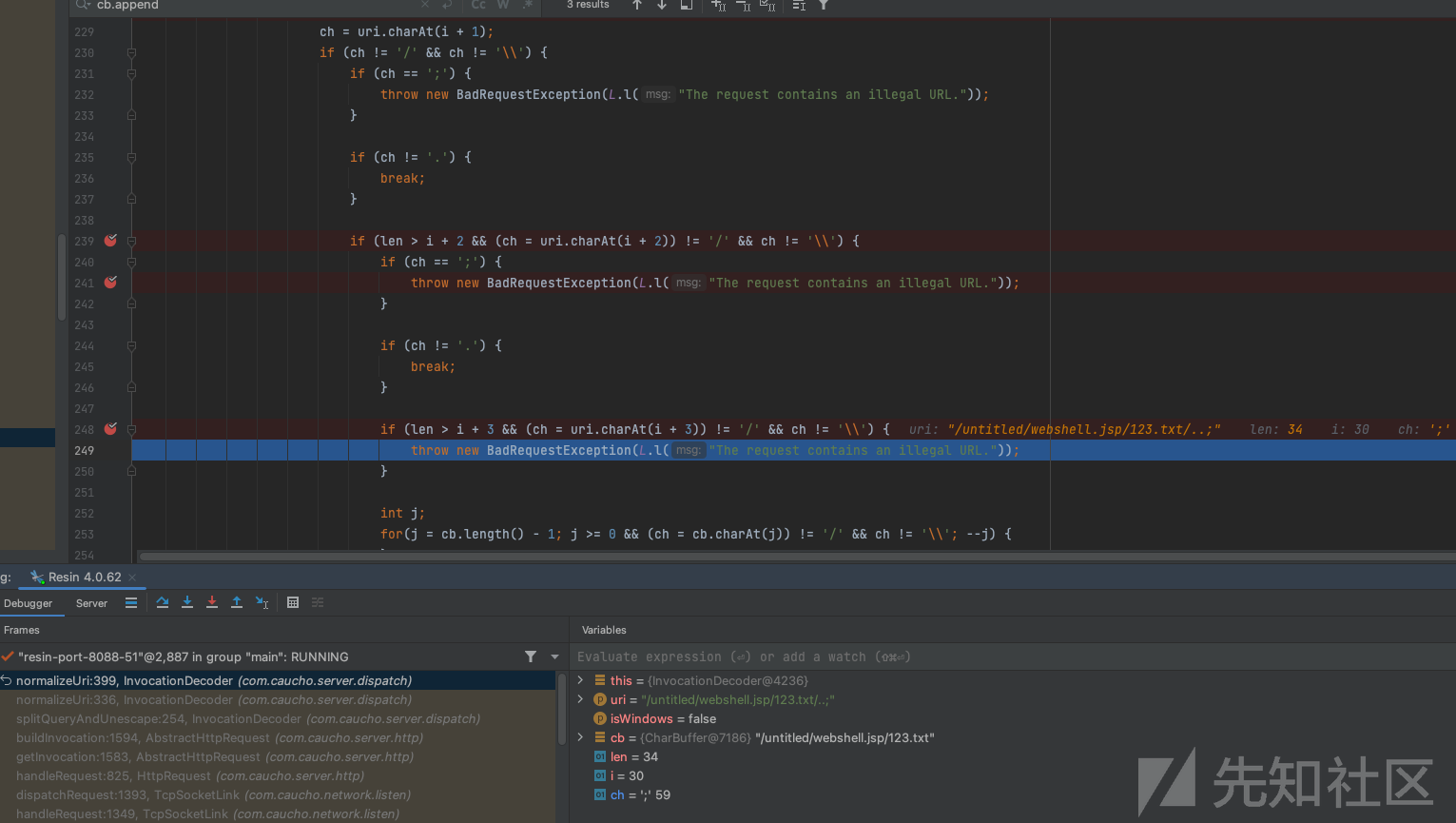
-
this._maxURILength设置URI最多不能超过1024个字符 -
/后面不能拼接;,/;这种方式。 -
/.是可以的,但是不能/.;这种方式是会报错的 - 在shiro中出现的
..;/这种方式不能适用
参考文章
 转载
转载
 分享
分享


