
几十年来,对攻击进行检测一直是信息安全的一部分。 第一个已知的入侵检测系统(IDS)的实现可以追溯到20世纪80年代初。
如今,攻击检测已经成为一种行业。IDS、IPS、WAF和防火墙解决方案等许多技术存在于网络,而其中大多数技术均提供基于规则的攻击检测。 使用某种统计异常来识别网络中的攻击似乎已经得到了印证。但这个假设是否合理?
检测Web应用程序中的异常
20世纪90年代初,市场上出现了第一批用于检测Web应用程序攻击的防火墙。从那时起,攻击技术和保护机制都发生了巨大变化,攻击者争先恐后地进行创新以便领先一步。
当前的Web应用程序防火墙(WAF)都使用类似的方式检测攻击,例如将基于规则的引擎嵌入某种类型的反向代理中。最突出的例子是mod_security,它是2002年创建的Apache Web服务器的WAF模块。基于规则的检测有一些缺点:例如,它无法检测到新的漏洞攻击(0 day),即使这些攻击很容易被研究者检测到。这个事实并不令人惊讶,因为人类的大脑与一组正则表达式的工作方式完全不同。
从WAF的角度来看,攻击可以分为基于顺序的(时间序列)和由单个HTTP请求或响应组成的攻击。我们的研究重点是检测后一类攻击,包括:
- SQL 注入
- Cross-Site Scripting(跨站脚本)
- XML External Entity Injection
- Path Traversal
- OS Commanding (系统命令执行)
- Object Injection
但首先让我们问自己:我们将如何做到这一点?
在看到一个单一请求时,人类会做什么?
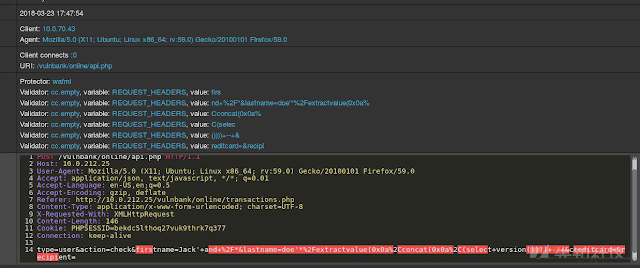
看一下对某个应用程序的常规HTTP请求:
如果用户必须检测发送到应用程序的请求,那么我们一定希望这个请求是正常的。在查看了许多应用程序执行端点的请求之后,用户将大致了解安全请求的结构及其包含的内容。
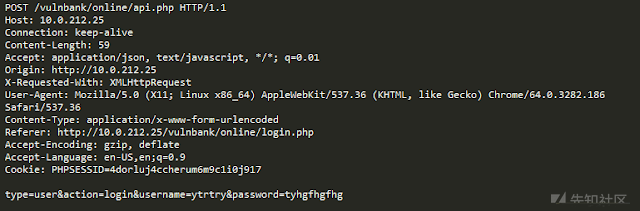
现在我们将看到以下请求:
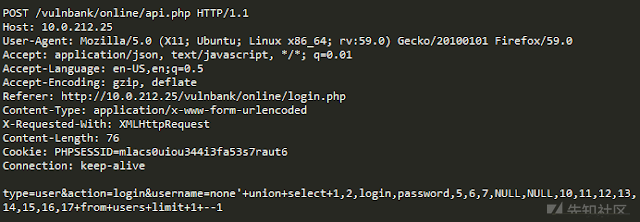
我们马上就知道出了什么问题。,并且需要更多的时间来了解这个漏洞究竟是什么,一旦找到异常请求的确切部分,我们就可以开始考虑它是什么类型的攻击。 从本质上讲,我们的目标是让我们的攻击检测AI以类似于人类推理的方式解决问题。
使我们的任务变得复杂的是,即使某些流量看起来是恶意的,但对于某个特定网站来说可能实际上是正常的。
例如,让我们看看以下请求:
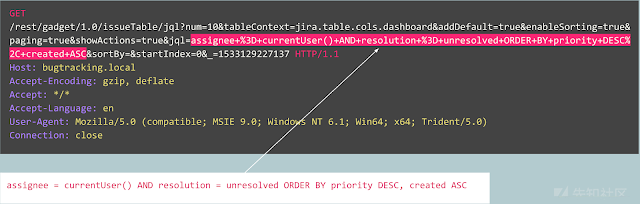
这是异常请求吗? 实际上,这个请求是无害的:这是与Jira bug跟踪器上的bug发布相关的典型请求。
现在让我们来看看另一个例子:
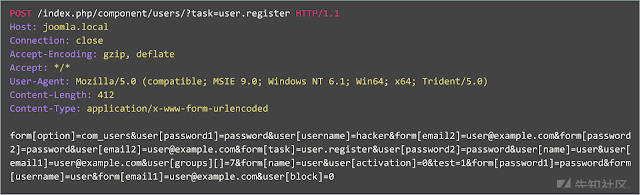
起初,该请求看起来像是由Joomla CMS的用户注册。 但是,请求的操作是“user.register”而不是正常的“registration.register”。 前一个选项已弃用。所以其中包含一个漏洞,允许任何人以管理员身份注册。
此漏洞被称为“Joomla <3.6.4帐户创建/权限提升”(CVE-2016-8869,CVE-2016-8870)。
我们如何开始
首先,我们需要看一下前些时间的研究。在过去几十年中,我们已经进行了许多尝试并创建不同的统计或机器学习算法来检测攻击。 最常用的方法之一是解决分配给类的任务(“ benign请求”,“SQL注入”,“XSS”,“CSRF”等)。 虽然可以通过对给定数据集进行分类来获得相当高的准确度,但这种方法无法解决一些非常重要的问题:
1 分类的问题。 如果机器在学习期间的模型有三个类(“ benign”,“SQLi”,“XSS”),但在生产中遇到CSRF攻击甚至是全新的攻击技术会怎么样?
2 类的含义。 假设我们需要保护10个客户,每个客户都运行完全不同的Web应用程序。 对于大多数人来说,你根本不知道针对他们的应用程序的单一“SQL注入”攻击是什么样的。 这意味着我们必须以某种方式人为地构建学习数据集。然而这并不是个好主意,因为我们最终将从与实际数据完全不同的分布数据中学习。
3 模型结果的可解释性。倘若模型提出了“SQL注入”标签,那我们应该如何处理? 我们最重要的是客户,他是第一个看到警报但通常不是网络攻击专家,所以他必须猜测模型并自行决定哪个部分是恶意的。
无论如何我们决定尝试分类,请记住这一点。
由于HTTP协议是基于文本的,很明显我们必须看一下现代文本分类器。其中一个例子是IMDB电影评论数据集的情绪分析器。解决方案使用递归神经网络(RNN)来对这些评论进行分类。我们决定使用类似的RNN分类模型。例如,自然语言分类RNN使用单词嵌入,但不清楚像HTTP这样的非自然语言中有哪些单词。这就是我们决定在模型中使用字符嵌入的原因。
现成的嵌入与解决问题无关,这就是为什么在我们完成模型的开发和测试之后将使用简单的字符映射到具有内部标记的数字代码,例如GO和EOS。之前预测的问题都得以实现。
我们如何进行检测
在这里,我们决定让我们的模型的结果变得更容易解释。在某些时候,我们遇到了“关注”机制并开始将其整合到我们的模型中。这产生了一些很好结果:最后,一切都汇集在一起,我们得到了一些人类可解释的结果。现在我们的模型不仅开始输出标签,还输出输入的每个字符的相应系数。
如果可以在Web界面中看到它,我们可以为找到“SQL注入”攻击的确切位置而提供帮助。
我们开始看到,我们可以从注意机制的方向入手,并远离分类。我们在序列模型上阅读了大量相关研究,并通过试验数据后,我们创建了一个可以在正常工作中进行异常检测的模型。
自动编码
在某些时候,很明显序列到序列自动编码器最能帮助我们进行处理。序列模型由两层长短期记忆(LSTM)模型组成:编码器和解码器。 编码器将输入序列映射到固定维度的矢量。 解码器使用编码器的该输出对目标矢量进行解码。
因此,自动编码器是一种序列模型,它将其目标值设置为等于其输入值。 这是教网络重新创建它已经看到的东西,换句话说,就是近似一个身份函数。 如果训练的自动编码器被给予异常样本,则由于从未见过这样的样本,所以很可能存在很大误差。
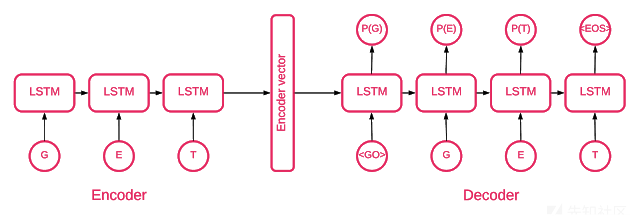
编码过程
我们的解决方案由几个部分组成:模型初始化,训练模型,预测和验证。
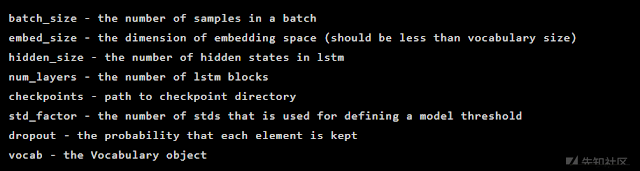
该模型初始化为Seq2Seq类的实例,该类具有以下构造函数参数:
之后,初始化自动编码器层。 首先,编码器:
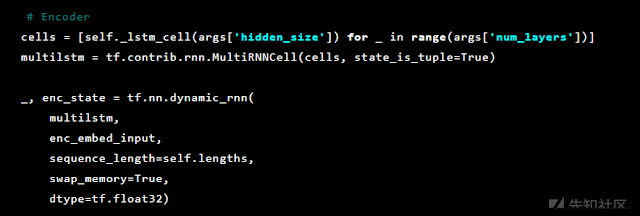
之后进行解码:
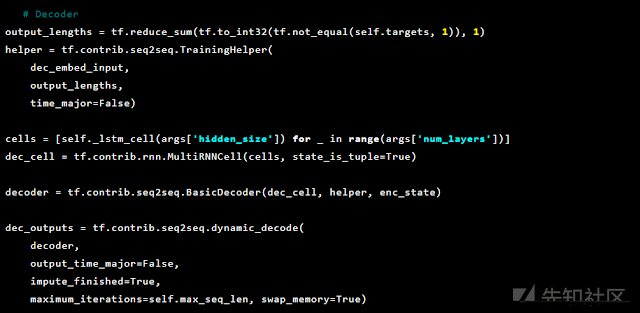
由于我们正在尝试解决异常检测,因此目标和输入是相同的。 因此我们的feed_dict如下:
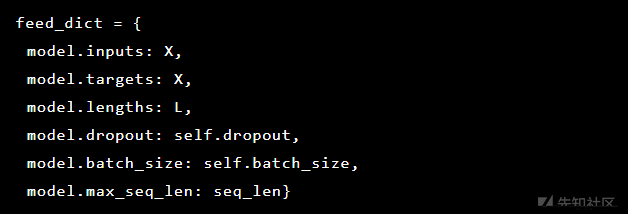
在每个处理后,最佳模型被保存为检查点,稍后可以加载该检查点以进行预测。 出于测试目的,由模型建立并保护实时Web应用程序,以便可以测试真实攻击是否成功。
受到注意机制的启发,我们尝试将其应用于自动编码器,我们发现从最后一层输出的概率在标记请求的异常部分时效果更优。

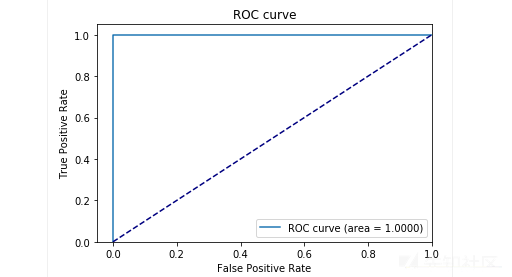
在测试阶段,我们的样品得到了非常好的结果:精度和recall接近0.99。 ROC曲线大约是1.绝对是一个不错的结果!
结果
我们描述的Seq2Seq自动编码器模型被证明能够高精度地检测HTTP请求中的异常。
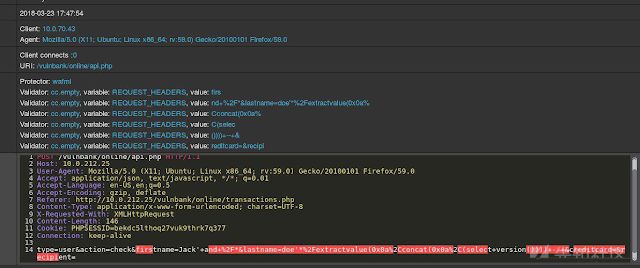
这个模型如同人类一样:它只学习发送给Web应用程序的“正常”用户请求。 它检测请求中的异常并突出显示被视为异常的请求。 我们针对测试应用程序的攻击评估了此模型。 例如,前面的屏幕截图描述了我们的模型检测到SQL注入如何跨两个Web表单参数分割。 此类SQL注入是碎片化的,因为攻击payload存在于多个HTTP参数中。 但是基于规则的经典WAF在检测SQL注入方面表现不佳,因为它们通常会自行检查每个参数。
模型代码和测试数据已作为Jupyter发布,因此任何人都可以复现我们的结果并提出改进建议。
结论
我们相信这次实验非常重要:我们想出一种以最小的投入来检测攻击的方法。一方面,我们试图避免过度复杂的解决方案并创建一种检测攻击的方法。与此同时,当一个(错误的)专家决定什么表示攻击而哪些不表示攻击时,我们希望避免人为因素的问题。总的来说,采用Seq2Seq架构的自动编码器解决了检测异常的问题。
我们还想解决数据可解释性问题。当使用复杂的神经网络架构时,我们很难解释特定的结果。当应用经过一系列转换时,识别结果背后的数据是很有难度的。然而,在重新思考模型对数据解释的方法之后,我们能够从最后一层获得每个结果的概率。
本文为翻译文章,文章来源:http://blog.ptsecurity.com/2019/02/detecting-web-attacks-with-seq2seq.html
 转载
转载
 分享
分享


-
-
-
-
-
-
-
-
